
一、前提说明
1、说明:
NFS client provisioner 利用 NFS Server 给 Kubernetes 作为持久存储的后端,并且动态提供PV。
默认 rancher 2 的存储类中的提供者不包含NFS,需要手动添加;添加方式有两种:
1)从应用商店直接安装配置 nfs-client-provisioner (需手动添加仓库,该仓库是从helm官方代码库复制自己需要的应用代码并定制的)
2)手动创建 nfs-client-provisioner 存储类,步骤如下:
2、前提:
1)安装好 nfs server(172.31.49.9 ),并分享目录(k8snfs_test)
2)安装有 helm 的 master 主机上安装 git
yum install -y git
3)安装rpcbind
yum install -y rpcbind
systemctl enable rpcbind
systemctl start rpcbind
二、安装 nfs-client-provisioner
参考:https://github.com/helm/charts/tree/master/stable/nfs-client-provisioner
在安装 helm 的主机上操作:
git clone https://github.com/helm/charts.git
cd charts/
helm install stable/nfs-client-provisioner --set nfs.server=172.31.49.9 --set nfs.path=/k8snfs_test
执行结果如下:
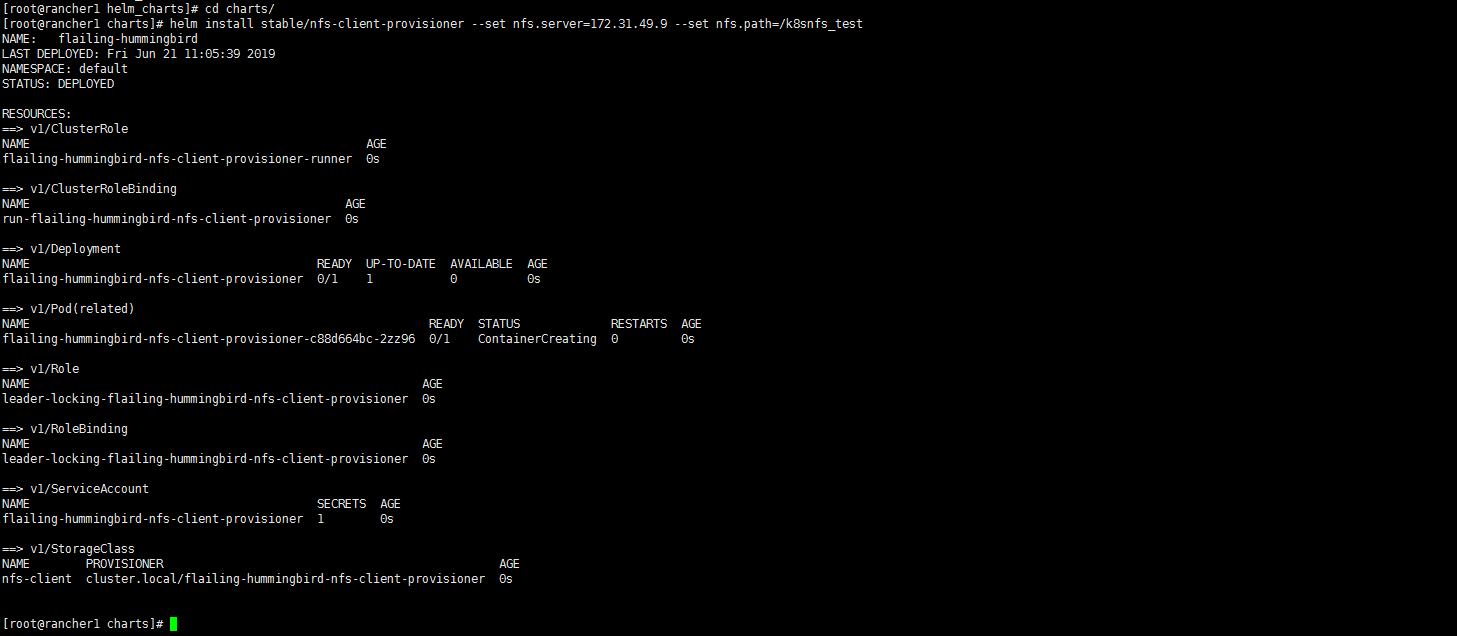
nfs client 会以容器的形式运行。同时在集群的存储类中创建了 nfs-client 类
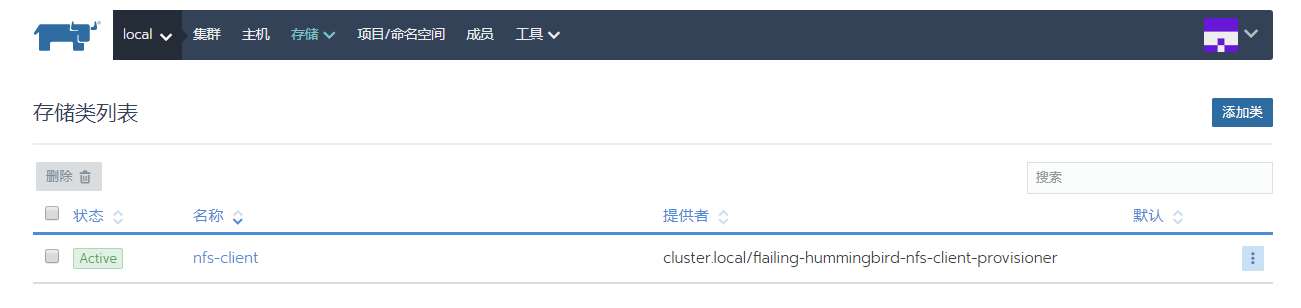
三、验证
1、启动一个 pod,添加存储卷(创建新的 PV,存储类选择 nfs-client,保存)。
2、然后填写PVC卷名,容器路径。
3、进入容器,创建一个测试文件
4、进入 NFS server 中查看分享的 k8snfs_test 目录可看到自动创建了持久卷目录。
[root@DL-Dev4-49-9 k8snfs_test]# ll
total 4
drwxrwxrwx 2 root root 4096 Jun 21 15:42 default-pvc-g55h2-pvc-a002261e-93f7-11e9-a843-025f44ec7002
[root@DL-Dev4-49-9 k8snfs_test]#
[root@DL-Dev4-49-9 k8snfs_test]# ll default-pvc-g55h2-pvc-a002261e-93f7-11e9-a843-025f44ec7002/
total 0
-rw-r--r-- 1 root root 0 Jun 21 15:42 111.txt
5、在rancher的持久卷中也可以看到该持久卷
四、NFS性能调整
Linux nfs客户端对于同时发起的NFS请求数量进行了控制,若该参数配置较小会导致IO性能较差,请查看该参数:
cat /proc/sys/sunrpc/tcp_slot_table_entries
默认编译的内核该参数最大值为256,可适当提高该参数的值来取得较好的性能,请以root身份执行以下命令:
echo "options sunrpc tcp_slot_table_entries=128" > /etc/modprobe.d/sunrpc.conf
echo "options sunrpc tcp_max_slot_table_entries=128" > /etc/modprobe.d/sunrpc.conf
sysctl -w sunrpc.tcp_slot_table_entries=128
修改完成后,您需要重新挂载文件系统或重启机器。
参考:
https://yq.aliyun.com/articles/501417
https://github.com/helm/charts/tree/master/stable/nfs-client-provisioner












