
Spark在前面已经和大家说过很多了,Python这几天也整理出了很多自己的见解,今天就和大家说下一个新的东西,PySpark,一看名字就知道和前面二者都有很大关系,那么PySpark到底是什么,和之前所说的Spark与Python有什么不一样的呢?今天就和大家简单的聊聊。
回忆下Spark的简介:
Spark是一种通用的大数据计算框架,是基于RDD(弹性分布式数据集)的一种计算模型。那到底是什么呢?可能很多人还不是太理解,通俗讲就是可以分布式处理大量集数据的,将大量集数据先拆分,分别进行计算,然后再将计算后的结果进行合并。
PySpark简介
Spark是用 Scala编程语言 编写的。为了用Spark支持Python,Apache Spark社区发布了一个工具PySpark。使用PySpark,也可以使用Python编程语言中的 RDD 。正是由于一个名为 Py4j的库,他们才能实现这一目标。
简单来说
在python driver端,SparkContext利用Py4J启动一个JVM并产生一个JavaSparkContext。Py4J只使用在driver端,用于本地python与Java SparkContext objects的通信。大量数据的传输使用的是另一个机制。
RDD在python下的转换会被映射成java环境下PythonRDD。在远端worker机器上,PythonRDD对象启动一些子进程并通过pipes与这些子进程通信,以此send用户代码和数据。
PySpark 是 Spark 为 Python 开发者提供的 API,其依赖于 Py4J。
PySpark 使用的类
pyspark.SparkContext
pyspark.SparkContext 类提供了应用与 Spark 交互的主入口点,表示应用与 Spark 集群的连接,基于这个连接,应用可以在该集群上创建 RDD 和 广播变量 (pyspark.Broadcast)
pyspark.RDD
这个类是为 PySpark 操作 RDD提供了基础方法。
first() 是 pyspark.RDD 类提供的方法,返回 RDD 的第一个元素。
aggregate() 方法使用给定的组合函数和中性“零值,先聚合每个分区的元素,然后再聚合所有分区的结果。
cache() 使用默认存储级别(MEMORY_ONLY)对此 RDD 进行持久化。
collect() 返回一个列表,包含此 RDD 中所有元素。
pyspark.Accumulator
一种“只允许添加”的共享变量,Spark 任务只能向其添加值。
pyspark.Broadcast
Spark 提供了两种共享变量:广播变量 和 累加器,pyspark.Broadcast 类提供了对广播变量的操作方法。
pyspark.Accumulator
pyspark.Accumulator 提供了对累加器变量的操作方法。
累加器是仅仅被相关操作累加的变量,因此可以在并行中被有效地支持。
pyspark安装
linu系统 Anaconda3安装
(1)python自身缺少numpy、matplotlib、scipy、scikit-learn…等一系列包du,需要安装pip来导入这些包才能进行相应运算。
Anaconda(开源的Python包管理器)是一个python发行版,包含了conda、Python等180多个科学包及其依赖项。包含了大量的包,使用anaconda无需再去额外安装所需包。
下载anaconda
https://www.anaconda.com/distribution/
我们这里以Anaconda3-5.1.0-Linux-x86_64.sh为例,下载好以后拖到Linux系统根目录下下
前置安装spark环境变量
前面已经给大家讲过spark的具体安装教程,在这里就不给大家概述了,pyspark是依赖于spark的,所以必须要先把spark安装好,不然安装pyspark就免谈了,安装过spark以后,开始配置环境变量,
vi /etc/profile
export SPARK_HOME=/opt/soft/spark234 #我的spark安装的目录
export SPARK_CONF_DIR=$SPARK_HOME/conf
export PATH=$PATH:$SPARK_HOME/bin
激活配置
source /etc/profile
接下来开始安装anaconda
使用 yum 安装 bzip2,缺少 bzip2 安装 Anaconda 会失败
yum install -y bzip2
安装 Anaconda3-5.1.0-Linux-x86_64
bash Anaconda3-5.1.0-Linux-x86_64.sh
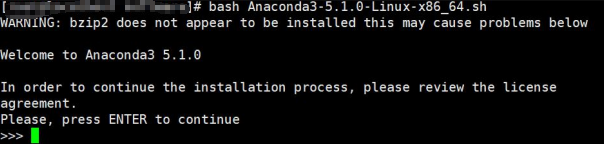
根据提示输入ENTER,然后一直按回车或根据提示输入yes 只有最后提示要安装 Microsoft VSCode时回答no,这样就开始安装了。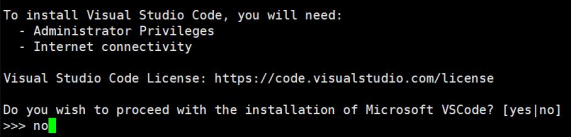
安装完以后默认会在/root/anaconda3下。
你也可以自己找目录放,如下图所示: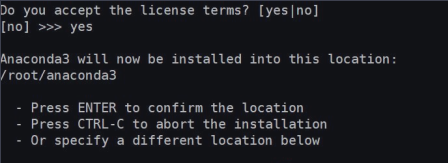
输入ENTER就会自己帮你放到/root/anaconda3,也可以自己输入存放的目录。
生成jupyter配置文件
(我生成的文件是root用户路径下/root/.jupyter/jupyter_notebook_config.py)
进入你的用户根目录,生成配置文件
cd ~
#或者
cd /root
#输入命令生成配置文件
./jupyter notebook --generate-config
生成Jupyter登录密码
输入命令
ipython
会出现提示语 **In [1]**,输入命令
from notebook.auth import passwd
出现提示语 **In [2]**,输入命令
passwd()
要求输入密码
1234
输入完密码后会出现密钥:生成一个’sha1:xxxxx’ ,用记事本 粘贴单引号里面的内容 .先保存好。
配置jupyter_notebook_config.py文件
允许从外部访问 Jupyter
cd /root/.jupyter
vi jupyter_notebook_config.py
c.NotebookApp.allow_root=True
c.NotebookApp.ip='*'
c.NotebookApp.open_browser=False
#刚才生成的密钥,粘贴过来放到单引号里面
c.NotebookApp.password=u'sha1:a7bd0a5fa349:d818d9bc31ee70715eff7b1705ebfb047cd38b72'
c.NotebookApp.port=7070

加入anaconda环境变量 并激活
vi /etc/profile
export ANACONDA_HOME=/root/anaconda3 #anaconda3安装目录,前面提到过
export PATH=$PATH:$ANACONDA_HOME/bin
export PYSPARK_DRIVER_PYTHON=jupyter-notebook
export PYSPARK_DRIVER_PYTHON_OPTS="--ip=0.0.0.0 --port=8888"
激活配置
source /etc/profile
执行命令启动pyspark
如果要环境加入pyspark 就直接执行命令
pyspark
如果只需要普通python环境 就输入命令
jupyter notebook --allow-root
输入完成后,会有个端口提示,那就是要进入jupyter浏览器的端口,前提是要先启动spark,在这里我就不多说了
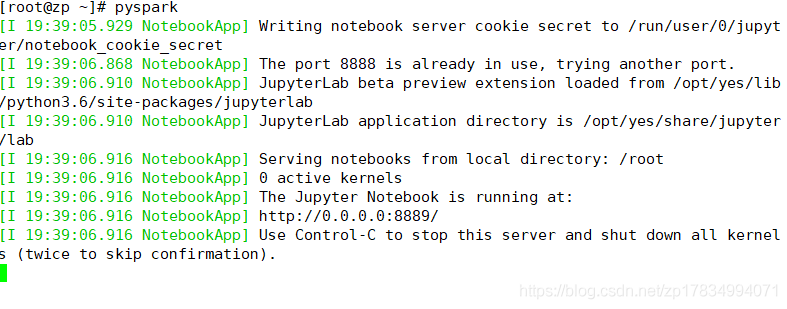
通过浏览器打开 Jupyter
如上图提示,端口号是8889,那么我民就去输入网址自己的主机IP和这个端口就可以进入jupyter
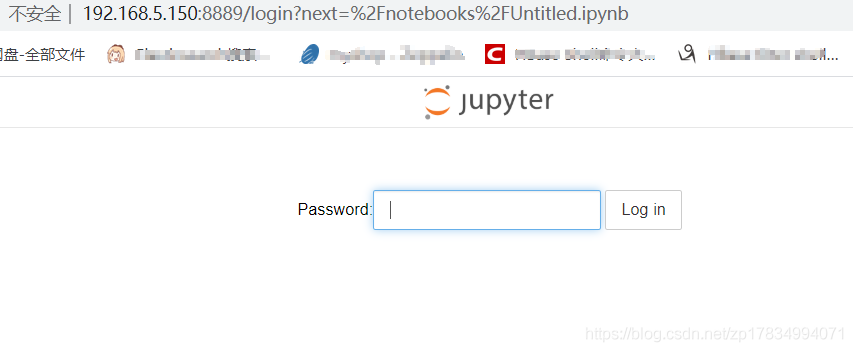 如上图所示,输入地址后会有个提示,要求输入密码,这是输入你的密码就可以登录了
如上图所示,输入地址后会有个提示,要求输入密码,这是输入你的密码就可以登录了
注意:
有时会启动不了pyspark,会报错没有执行权限,这时就需要更改权限了。
cd /root/anaconda3/share
chmod +777 jupyter
这时就可以启动了!











