
内存管理
当 Redis 作为缓存使用时(此时缓存仅作为热点数据提高服务的访问性能),需要考虑内存的限制,以及如何随着业务的增长,仅保留热点数据。
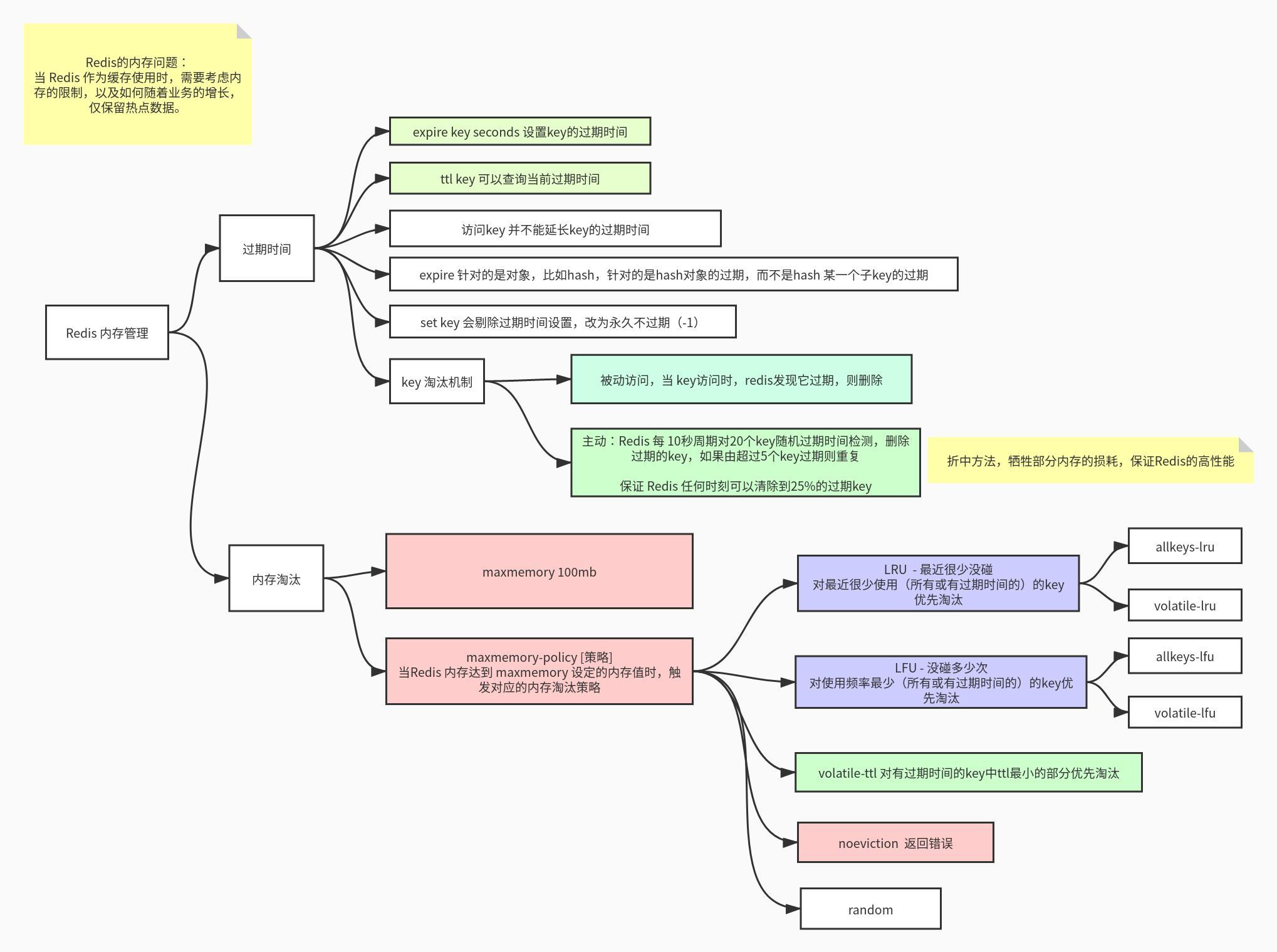
过期时间
Redis 所有的数据结构都可以设置过期时间,时间到了,Redis 会自动删除相应的对象。 需要注意的:
过期
expire是以对象为单位,比如一个 hash 结构的过期是整个 hash 对象的过期,而不是其中的某个子 key。如果一个字符串已经设置了过期时间,然后你调用了 set 方法修改了它,它的过期时间会消失。
127.0.0.1:6379> set k1 aaa OK 127.0.0.1:6379> expire k1 600 (integer) 1 127.0.0.1:6379> ttl k1 (integer) 597 127.0.0.1:6379> set k1 bbb OK 127.0.0.1:6379> ttl k1 (integer) -1...
淘汰过期的 Keys
Redis keys过期有两种方式:被动和主动方式。
- 被动
当一些客户端尝试访问它时,key会被发现并主动的过期。
- 主动
当然,这样是不够的,因为有些过期的keys,永远不会访问他们。
无论如何,这些keys应该过期,所以定时随机测试设置keys的过期时间。所有这些过期的keys将会从密钥空间删除。
具体就是Redis每秒10次做的事情:
- 1.测试随机的20个keys进行相关过期检测。
- 2.删除所有已经过期的keys。
- 3.如果有多于25%的keys过期,重复步奏1. 这是一个平凡的概率算法,基本上的假设是,我们的样本是这个密钥控件,
并且我们不断重复过期检测,直到过期的keys的百分百低于25%,这意味着,在任何给定的时刻,最多会清除1/4的过期keys。
内存淘汰
在 redis.conf 或 使用 CONFIG 命令配置 Redis的配置项:
maxmemory 100mb
maxmemory-policy [策略]
淘汰策略:
LRU- 最近很少没碰
对最近很少使用(所有或有过期时间的)的key优先淘汰
allkeys-lru尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。volatile-lru尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。LFU- 没碰多少次
对使用频率最少(所有或有过期时间的)的key优先淘汰
allkeys-lfu尝试回收回收使用频率最少的键(LFU),使得新添加的数据有空间存放。volatile-lfu尝试回收使用频率最少的键(LFU),但仅限于在过期集合的键,使得新添加的数据有空间存放。volatile-ttl对有过期时间的key中ttl最小的部分优先淘汰noeviction返回错误allkeys-random: 回收随机的键使得新添加的数据有空间存放。
volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
近似LRU算法
Redis的LRU算法并非完整的实现。这意味着Redis并没办法选择最佳候选来进行回收,也就是最久未被访问的键。
相反它会尝试运行一个近似LRU的算法,通过对少量keys进行取样,然后回收其中一个最好的key(被访问时间较早的)。
Redis LRU有个很重要的点,你通过调整每次回收时检查的采样数量,以实现调整算法的精度。这个参数可以通过以下的配置指令调整:
maxmemory-samples 5
@SvenAugustus(https://www.flysium.xyz/)
更多请关注微信公众号【编程不离宗】,专注于分享服务器开发与编程相关的技术干货:










