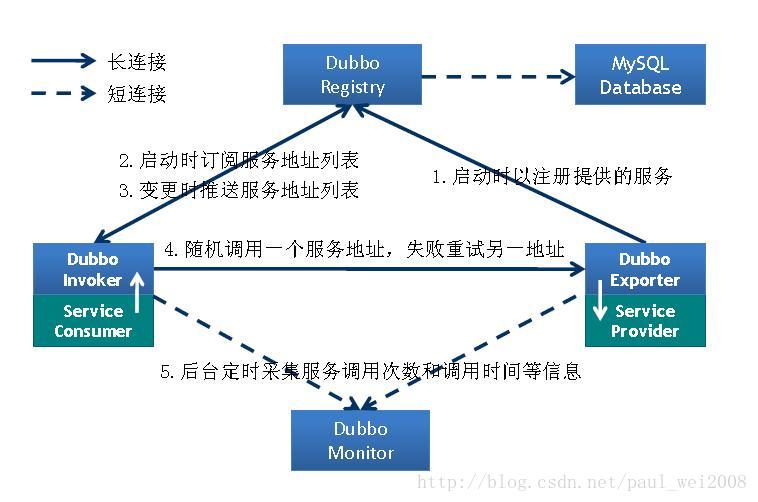
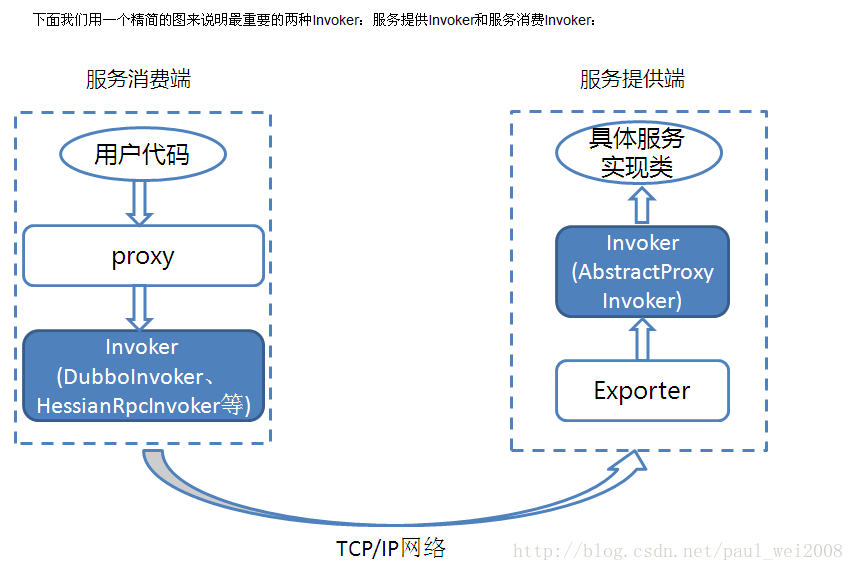
分布式服务框架:
–高性能和透明化的RPC远程服务调用方案
–SOA服务治理方案
-Apache MINA 框架基于Reactor模型通信框架,基于tcp长连接
Dubbo缺省协议采用单一长连接和NIO异步通讯,
适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况
分析源代码,基本原理如下:
- client一个线程调用远程接口,生成一个唯一的ID(比如一段随机字符串,UUID等),Dubbo是使用AtomicLong从0开始累计数字的
- 将打包的方法调用信息(如调用的接口名称,方法名称,参数值列表等),和处理结果的回调对象callback,全部封装在一起,组成一个对象object
- 向专门存放调用信息的全局ConcurrentHashMap里面put(ID, object)
- 将ID和打包的方法调用信息封装成一对象connRequest,使用IoSession.write(connRequest)异步发送出去
- 当前线程再使用callback的get()方法试图获取远程返回的结果,在get()内部,则使用synchronized获取回调对象callback的锁, 再先检测是否已经获取到结果,如果没有,然后调用callback的wait()方法,释放callback上的锁,让当前线程处于等待状态。
- 服务端接收到请求并处理后,将结果(此结果中包含了前面的ID,即回传)发送给客户端,客户端socket连接上专门监听消息的线程收到消息,分析结果,取到ID,再从前面的ConcurrentHashMap里面get(ID),从而找到callback,将方法调用结果设置到callback对象里。
- 监听线程接着使用synchronized获取回调对象callback的锁(因为前面调用过wait(),那个线程已释放callback的锁了),再notifyAll(),唤醒前面处于等待状态的线程继续执行(callback的get()方法继续执行就能拿到调用结果了),至此,整个过程结束。
- 当前线程怎么让它“暂停”,等结果回来后,再向后执行?
答:先生成一个对象obj,在一个全局map里put(ID,obj)存放起来,再用synchronized获取obj锁,再调用obj.wait()让当前线程处于等待状态,然后另一消息监听线程等到服 务端结果来了后,再map.get(ID)找到obj,再用synchronized获取obj锁,再调用obj.notifyAll()唤醒前面处于等待状态的线程。
- 正如前面所说,Socket通信是一个全双工的方式,如果有多个线程同时进行远程方法调用,这时建立在client server之间的socket连接上会有很多双方发送的消息传递,前后顺序也可能是乱七八糟的,server处理完结果后,将结果消息发送给client,client收到很多消息,怎么知道哪个消息结果是原先哪个线程调用的?
答:使用一个ID,让其唯一,然后传递给服务端,再服务端又回传回来,这样就知道结果是原先哪个线程的了。