大家好,我是朱小五
昨天的文章《我用 Python 预测了股票价格》中就提了一嘴,最近爬了一些股票和基金数据。
再加上我们之前也做过基金抄底成功的概率问题,那就简单跟大家说一下如何爬取tiantian基金的数据。

基金代码
爬取基金的数据有个必要条件就是要知道基金代码,如何获取呢,打开官网找吧。
点了一圈,发现了基金代码的主页,寻思翻页爬取就完事了
http://fund.eastmoney.com/allfund.html
结果没想到F12打开下图中的fundcode_search.js
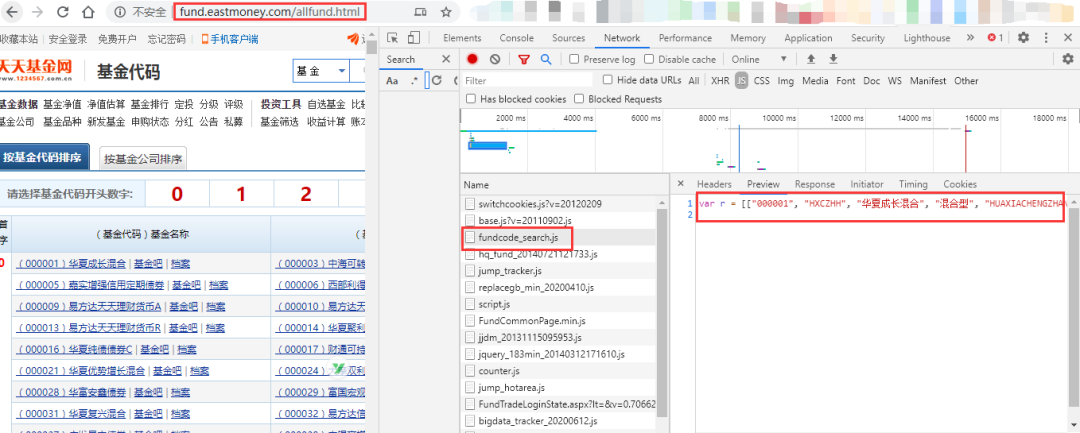
右键新标签页打开→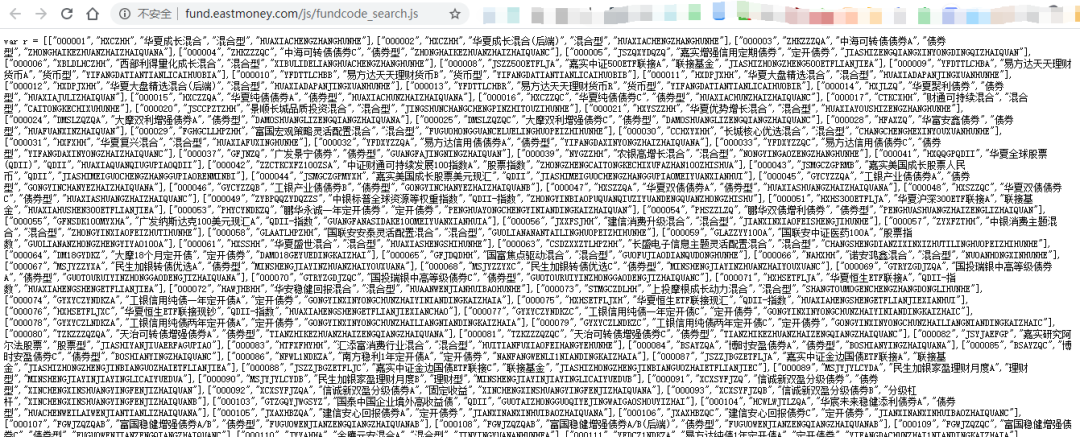
发现所有的基金代码都在,那么就更简单了呀。
import requests
import re
import json
import pandas as pd
url = 'http://fund.eastmoney.com/js/fundcode_search.js'
r = requests.get(url)
a = re.findall('var r = (.*])', r.text)[0]
b = json.loads(a)
fundcode = pd.DataFrame(b, columns=['fundcode', 'fundsx', 'name', 'category', 'fundpy'])
fundcode = fundcode.loc[:, ['fundcode', 'name', 'category']]
fundcode.to_csv('fundcode_search.csv', index=False, encoding='utf-8-sig')

运行获得所有基金代码共10736条数据。
爬取基金历史
有了上万个基金代码,再爬取他们近三年的净值数据,那四舍五入不就是千万条数据嘞~
在《用python来分析:基金抄底成功的概率有多大?》中就已经给出了方法,同样打开基金网站,用浏览器自带流量分析工具可以轻松找到数据接口。
其中callback为返回js回调函数,可以删除,funCode为基金代码,pageIndex为页码,pageSize为每页返回的数据条数是,startDate和endDate分别为开始时间和结束时间。[1]
fundCode = '001618' #基金代码
pageIndex = 1
startDate = '2018-02-22' #起始时间
endDate = '2020-07-10' #截止时间
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0',
'Referer': 'http://fundf10.eastmoney.com/jjjz_{0}.html'.format(fundCode)
}
url = 'http://api.fund.eastmoney.com/f10/lsjz?fundCode={0}&pageIndex={1}&pageSize=5000&startDate={2}&endDate={3}&_=1555586870418?'\
.format(fundCode, pageIndex, startDate, endDate)
response = requests.get(url, headers=header)
这样单个基金的数据就爬取好啦
那如何结合前面的基金代码合集进行循环爬取,相信也难不倒大家

最后小结一下,希望大家不要用这个破方法
明明有tushare 、akshare等等金融数据接口,用着不香吗?
所以你要问我爬取千万条基金数据是怎样的体验?
我觉得自己很傻。。。
参考文章
[1]
《用python来分析:基金抄底成功的概率有多大?》: https://mp.weixin.qq.com/s/irjLb-lJSKnXBxfGQYTJog


下面这本书限时300积分兑换哦
也可参加当当活动每满100减50
感谢北京大学出版社的大力支持
本文转转自微信公众号凹凸数据原创https://mp.weixin.qq.com/s/SVjNWBLIHSepOeFZVXmQ9w,可扫描二维码进行关注:
 如有侵权,请联系删除。
如有侵权,请联系删除。