

每一个成功人士的背后,必定曾经做出过勇敢而又孤独的决定。
放弃不难,但坚持很酷~
由于消费者模块的知识涉及太多,所以决定先按模块来整理知识,最后再进行知识模块汇总。今天学习一下消费者如何指定位移消费。
一、auto.offset.reset值详解
在 Kafka 中,每当消费者组内的消费者查找不到所记录的消费位移或发生位移越界时,就会根据消费者客户端参数 auto.offset.reset 的配置来决定从何处开始进行消费,这个参数的默认值为 “latest” 。
auto.offset.reset 的值可以为 earliest、latest 和 none 。关于 earliest 和 latest 的解释,官方描述的太简单,各含义在真实情况如下所示:
earliest :当各分区下存在已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,从头开始消费。
latest :当各分区下存在已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,消费该分区下新产生的数据。
none :topic 各分区都存在已提交的 offset 时,从 offset 后开始消费;只要有一个分区不存在已提交的offset,则抛出异常。
二、seek()方法
到目前为止,我们知道消息的拉取是根据 poll() 方法中的逻辑来处理的,这个 poll() 方法中的逻辑对于普通的开发人员而言是一个黑盒,无法精确地掌控其消费的具体位置。Kafka 提供的 auto.offset.reset 参数也只能在找不到消费位移或位移越界的情况下粗粒度地从开头或末尾开始消费。有的时候,我们需要一种更细粒度的掌控,可以让我们从指定的位移处开始拉取消息,而 KafkaConsumer 中的 seek() 方法正好提供了这个功能,让我们得以追前消费或回溯消费。seek() 方法的具体定义如下:
public void seek(TopicPartition partition, long offset)
seek() 方法中的参数 partition 表示分区,而 offset 参数用来指定从分区的哪个位置开始消费。seek() 方法只能重置消费者分配到的分区的消费位置,而分区的分配是在 poll() 方法的调用过程中实现的,也就是说,在执行 seek() 方法之前需要先执行一次 poll() 方法,等到分配到分区之后才可以重置消费位置。
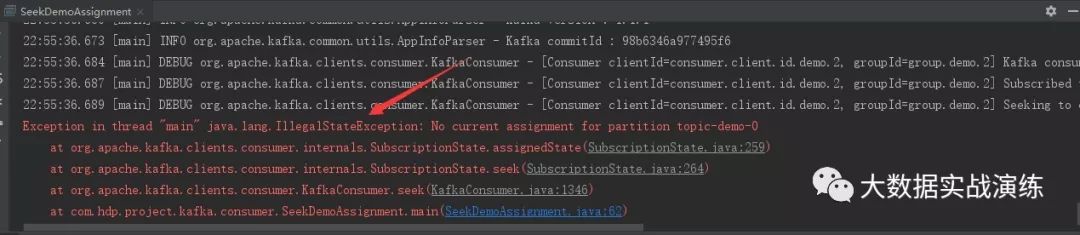
如果对未分配的分区执行 seek() 方法,那么会报出 IllegalStateException 的异常。类似在调用 subscribe() 方法之后直接调用 seek() 方法,如下所示:
consumer.subscribe(Arrays.asList(TOPIC));consumer.seek(new TopicPartition(TOPIC, 0), 80);
会报下述错误:
三、指定offset开始消费
接下来的代码示例讲述了消费各分区 offset 为 80(包括80)之后的消息:
Properties props = initConfig();KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Arrays.asList(TOPIC));Set<TopicPartition> assignment = new HashSet<>();// 在poll()方法内部执行分区分配逻辑,该循环确保分区已被分配。// 当分区消息为0时进入此循环,如果不为0,则说明已经成功分配到了分区。while (assignment.size() == 0) { consumer.poll(100); // assignment()方法是用来获取消费者所分配到的分区消息的 // assignment的值为:topic-demo-3, topic-demo-0, topic-demo-2, topic-demo-1 assignment = consumer.assignment();}System.out.println(assignment);for (TopicPartition tp : assignment) { int offset = 80; System.out.println("分区 " + tp + " 从 " + offset + " 开始消费"); consumer.seek(tp, offset);}while (true) { ConsumerRecords<String, String> records = consumer.poll(1000); // 消费记录 for (ConsumerRecord<String, String> record : records) { System.out.println(record.offset() + ":" + record.value() + ":" + record.partition()); }}
注意:假如某分区的前 100 条数据由于过期,导致被删除,那么此时如果使用 seek() 方法指定 offset 为 0 进行消费的话,是消费不到数据的。因为前 100 条数据已被删除,所以只能从 offset 为 100 ,来进行消费。
四、从分区开头或末尾开始消费
如果消费者组内的消费者在启动的时候能够找到消费位移,除非发生位移越界,否则 auto.offset.reset 参数不会奏效。此时如果想指定从开头或末尾开始消费,也需要 seek() 方法来实现。
如果按照第三节指定位移消费的话,就需要先获取每个分区的开头或末尾的 offset 了。可以使用 beginningOffsets() 和 endOffsets() 方法。
public Map
beginningOffsets(Collection
partitions) public Map
beginningOffsets(Collection
partitions, long timeout) public Map
endOffsets(Collection
partitions) public Map
endOffsets(Collection
partitions, long timeout)
其中 partitions 参数表示分区集合,而 timeout 参数用来设置等待获取的超时时间。如果没有指定 timeout 的值,那么 timeout 的值由客户端参数 request.timeout.ms 来设置,默认为 30000 。
接下来通过示例展示如何从分区开头或末尾开始消费:
Set<TopicPartition> assignment = new HashSet<>();// 在poll()方法内部执行分区分配逻辑,该循环确保分区已被分配。// 当分区消息为0时进入此循环,如果不为0,则说明已经成功分配到了分区。while (assignment.size() == 0) { consumer.poll(100); // assignment()方法是用来获取消费者所分配到的分区消息的 // assignment的值为:topic-demo-3, topic-demo-0, topic-demo-2, topic-demo-1 assignment = consumer.assignment();}// 指定分区从头消费Map<TopicPartition, Long> beginOffsets = consumer.beginningOffsets(assignment);for (TopicPartition tp : assignment) { Long offset = beginOffsets.get(tp); System.out.println("分区 " + tp + " 从 " + offset + " 开始消费"); consumer.seek(tp, offset);}// 指定分区从末尾消费Map<TopicPartition, Long> endOffsets = consumer.endOffsets(assignment);for (TopicPartition tp : assignment) { Long offset = endOffsets.get(tp); System.out.println("分区 " + tp + " 从 " + offset + " 开始消费"); consumer.seek(tp, offset);}// 再次执行poll()方法,消费拉取到的数据。// ...(省略)
值得一说的是:
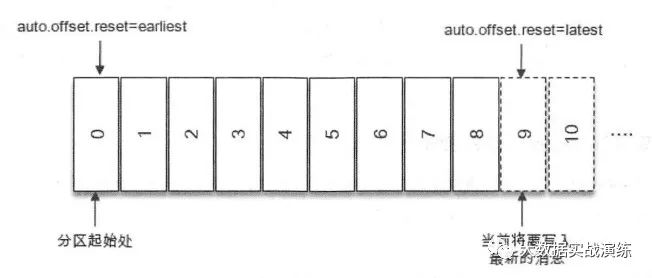
指定分区从头消费时,需要了解:一个分区的起始位置是 0 ,但并不代表每时每刻都为 0 ,因为日志清理的动作会清理旧的数据,所以分区的起始位置会自然而然地增加。
指定分区从末尾消费,需要了解:endOffsets() 方法获取的是将要写入最新消息的位置。如下图中 9 的位置:
其实,KafkaConsumer 中直接提供了 seekToBeginning() 和 seekToEnd() 方法来实现上述功能。具体定义如下:
public void seekToBeginning(Collection
partitions) public void seekToEnd(Collection
partitions)
例如使用
consumer.seekToBeginning(assignment);
直接可以代替
Map<TopicPartition, Long> beginOffsets = consumer.beginningOffsets(assignment);for (TopicPartition tp : assignment) { Long offset = beginOffsets.get(tp); System.out.println("分区 " + tp + " 从 " + offset + " 开始消费"); consumer.seek(tp, offset);}
五、根据时间戳消费
有时候我并不知道特定的消费位置,却知道一个相关的时间点。比如我想要消费某个时间点之后的消息,这个需求更符合正常的思维逻辑。这时,我们可以用 offsetsForTimes() 方法,来获得符合筛选条件的 offset ,然后再结合 seek() 方法来消费指定数据。offsetsForTimes() 方法如下所示:
- public Map<TopicPartition, OffsetAndTimestamp> offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch)
offsetsForTimes() 方法的参数 timestampsToSearch 是一个 Map 类型,其中 key 为待查询的分区,value 为待查询的时间戳,该方法会返回时间戳大于等于查询时间的第一条消息对应的 offset 和 timestamp 。
接下来就以消费当前时间前一天之后的消息为例,代码片段如下所示:
Set<TopicPartition> assignment = new HashSet<>();// 在poll()方法内部执行分区分配逻辑,该循环确保分区已被分配。// 当分区消息为0时进入此循环,如果不为0,则说明已经成功分配到了分区。while (assignment.size() == 0) { consumer.poll(100); // assignment()方法是用来获取消费者所分配到的分区消息的 // assignment的值为:topic-demo-3, topic-demo-0, topic-demo-2, topic-demo-1 assignment = consumer.assignment();}Map<TopicPartition, Long> timestampToSearch = new HashMap<>();for (TopicPartition tp : assignment) { // 设置查询分区时间戳的条件:获取当前时间前一天之后的消息 timestampToSearch.put(tp, System.currentTimeMillis() - 24 * 3600 * 1000);}// timestampToSearch的值为{topic-demo-0=1563709541899, topic-demo-2=1563709541899, topic-demo-1=1563709541899}Map<TopicPartition, OffsetAndTimestamp> offsets = consumer.offsetsForTimes(timestampToSearch);for(TopicPartition tp: assignment){ // 获取该分区的offset以及timestamp OffsetAndTimestamp offsetAndTimestamp = offsets.get(tp); // 如果offsetAndTimestamp不为null,则证明当前分区有符合时间戳条件的消息 if (offsetAndTimestamp != null) { consumer.seek(tp, offsetAndTimestamp.offset()); }}while (true) { ConsumerRecords<String, String> records = consumer.poll(1000); System.out.println("##############################"); System.out.println(records.count()); // 消费记录 for (ConsumerRecord<String, String> record : records) { System.out.println(record.offset() + ":" + record.value() + ":" + record.partition() + ":" + record.timestamp()); }}
六、总结
本节内容主要讲解了消费者如何指定位移消费,主要从以下几方面入手:
讲解了 auto.offset.reset 参数值的含义。
如何使用 seek() 方法指定 offset 消费。
接着又介绍了如何从分区开头或末尾消费消息:beginningOffsets()、endOffsets()、seekToBeginning、seekToEnd() 方法。
最后又介绍了如何根据时间戳来消费指定消息,更加务实一些。
即使消息已被提交,但我们依然可以使用 seek() 方法来消费符合一些条件的消息,这样为消息的消费提供了很大的灵活性。
七、推荐阅读
另外本文涉及到的源码已上传至:github,链接如下:
https://github.com/841809077/hdpproject/blob/master/src/main/java/com/hdp/project/kafka/consumer/,详见 SeekDemoAssignment.java 和 SeekToTimeDemo.java 文件。


本文分享自微信公众号 - 大数据实战演练(gh_f942bfc92d26)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











