
一、Python程序结构
Python中,有3种常见的程序结构:
- Sequence顺序 从上向下依次执行。
- Condition条件 满足某个条件则执行。
- Loop循环 重复执行某个动作。
1.if条件
判断某个变量是否满足某个条件时如下:
possibility_to_rain = 0.7
print(possibility_to_rain > 0.8)
print(possibility_to_rain > 0.3)
possibility_to_rain = 1
print(possibility_to_rain > 0.8)
print(possibility_to_rain > 0.3)输出:
False
True
True
True如需本节同步
ipynb文件,可以直接点击加QQ群963624318 在群文件夹商业数据分析从入门到入职中下载即可。
但是如果想在变量满足某个条件时需要执行某个动作,则需要if条件判断语句,如下:
possibility_to_rain = 0.7
if possibility_to_rain > 0.8:
print("Do take your umberalla with you.") ## 这个地方标准格式是四个空格的缩进
elif possibility_to_rain > 0.3:
print("Take your umberalla just in case. hahaha")
else:
print("Enjoy the sunshine!")
print('hello')输出:
Take your umberalla just in case. hahaha这段代码的意思是:
如果possibility_to_rain > 0.8为True,则执行print("Do take your umberalla with you."),如果不满足前述条件,但满足possibility_to_rain > 0.3,则执行print("Take your umberalla just in case. hahaha"),否则执行print("Enjoy the sunshine!");
if语句执行完后,再执行后面的语句,如print('hello');
需要注意缩进,if、elif、else语句后面的语句都应该缩进4格并保持对齐,即通过缩进控制代码块和代码结构,而不像其他语言使用{}来控制代码结构,如下:

前面也看到,出现了很多以#开头的代码和文字性说明,代码颜色也是和其他代码有所区别的,这就是Python中的单行注释,注释后的代码不会被执行,而只能起到说明作用,这段代码中这个地方标准格式是四个空格的缩进被#注释,这一行前面的代码能正常执行,#后的文字不会执行、也不会报错、作为解释性语句。
除了对数值进行判断,还能对字符串进行判断:
card_type = "debit"
account_type = "checking"
if card_type == "debit":
if account_type == "checking":
print("Checkings selectd.")
else:
print("Savings selected.")
else:
print("Credit card.")输出:
Take your umberalla just in case. hahaha
hello可以看到,使用到了条件判断的嵌套。
2.循环
while循环
之前要是需要执行重复操作,可能如下:
count =1
print(count)
count+=1
print(count)
count+=1
print(count)
count+=1
print(count)
count+=1
print(count)
count+=1
print(count)
count+=1
print(count)
count+=1
print(count)
count+=1
print(count)
count+=1
print(count)输出:
1
2
3
4
5
6
7
8
9
10显然,代码很冗长,此时就可以使用循环进行优化。
使用while循环如下:
count = 1
while count <= 10:
print(count)
count += 1执行效果与前面相同;
需要注意,循环一般要有停止的条件,当满足count <= 10时循环会一直执行,直到count = 11时就会不符合、从而退出循环;
如果没有停止条件,则可能陷入死循环、消耗内存。
再如:
cnt = 1
while True:
print("cnt = %d" % cnt)
ch = input('Do you want to continue? [y:n]: ')
if ch == 'y':
cnt += 1
else:
break 输出如下:
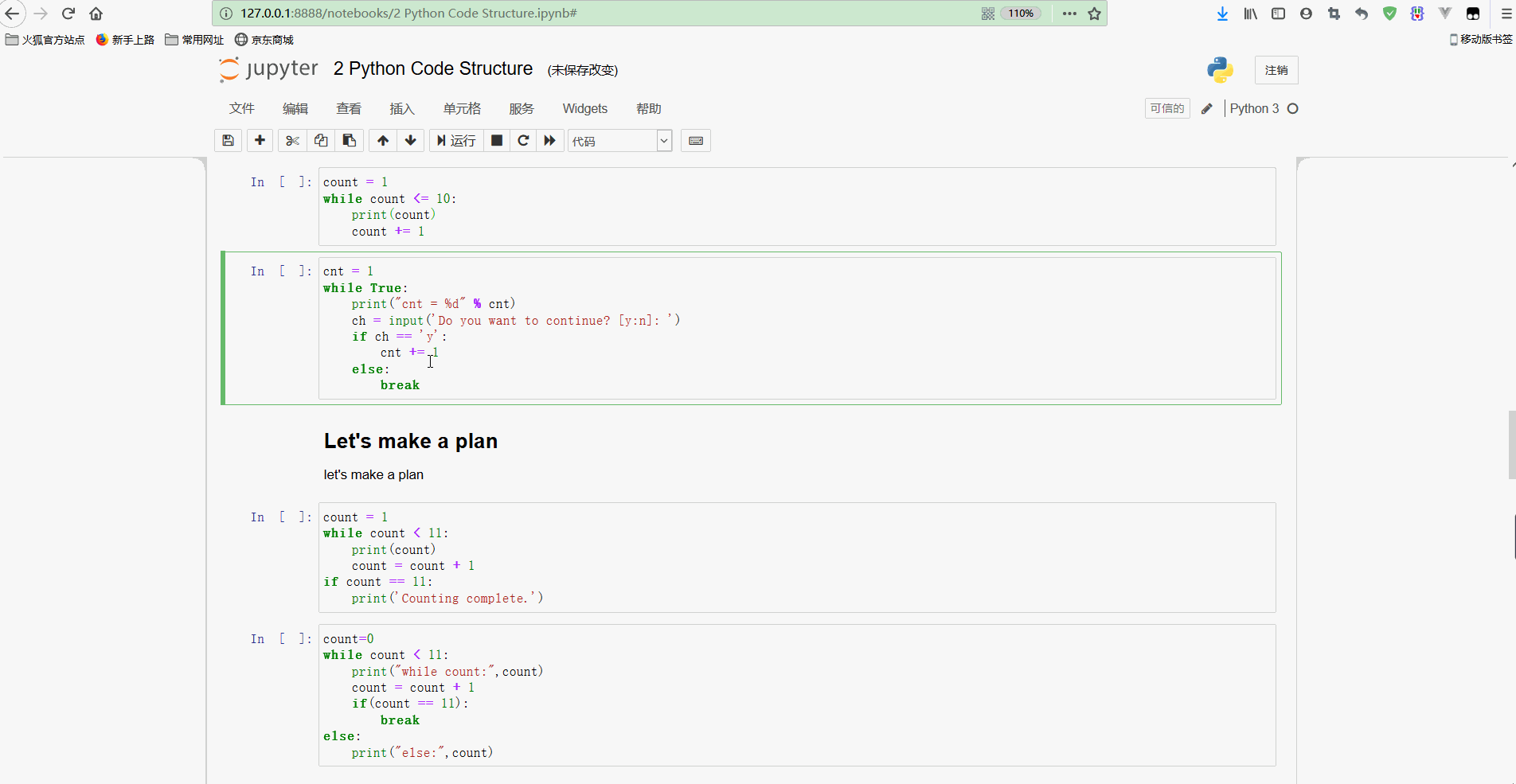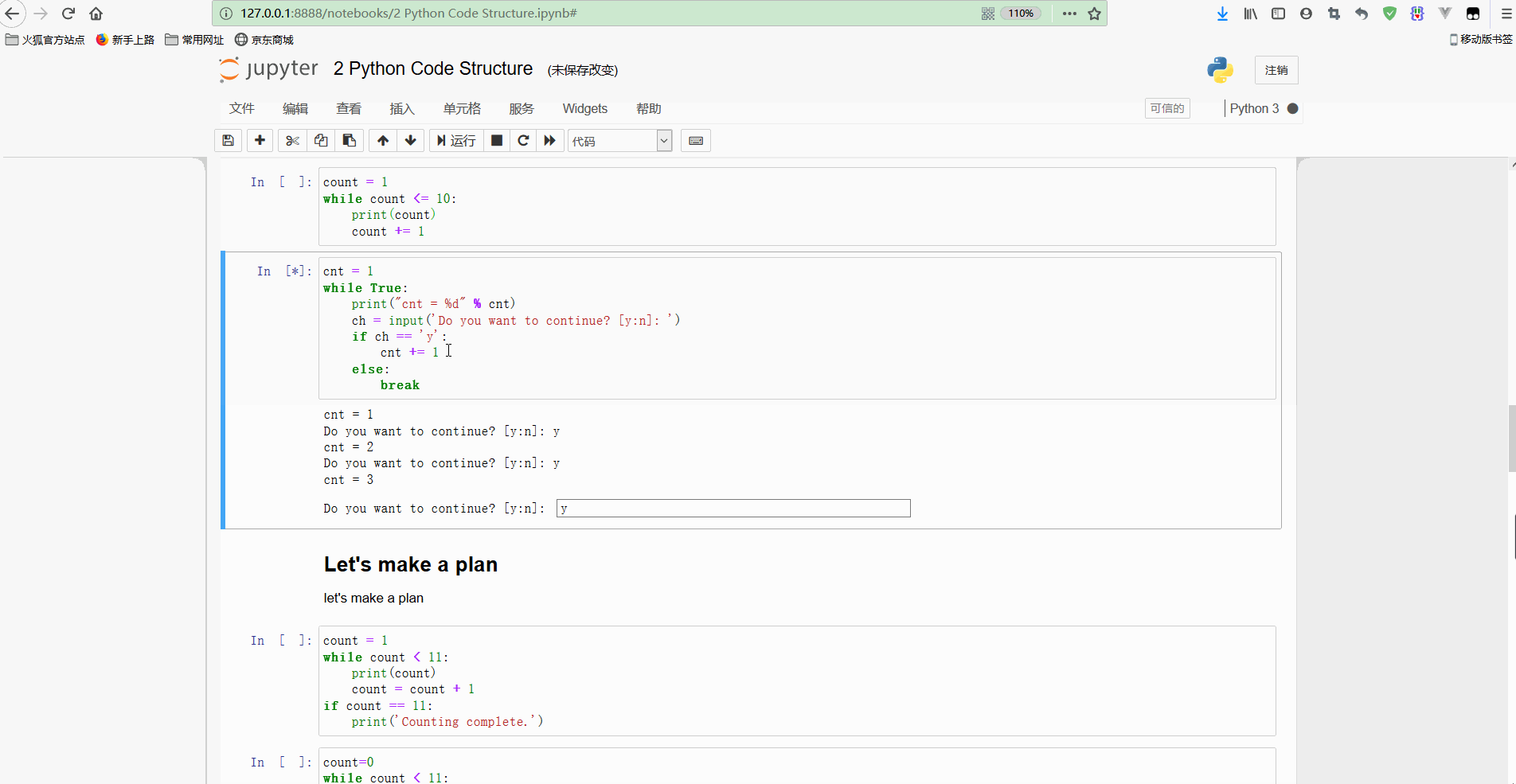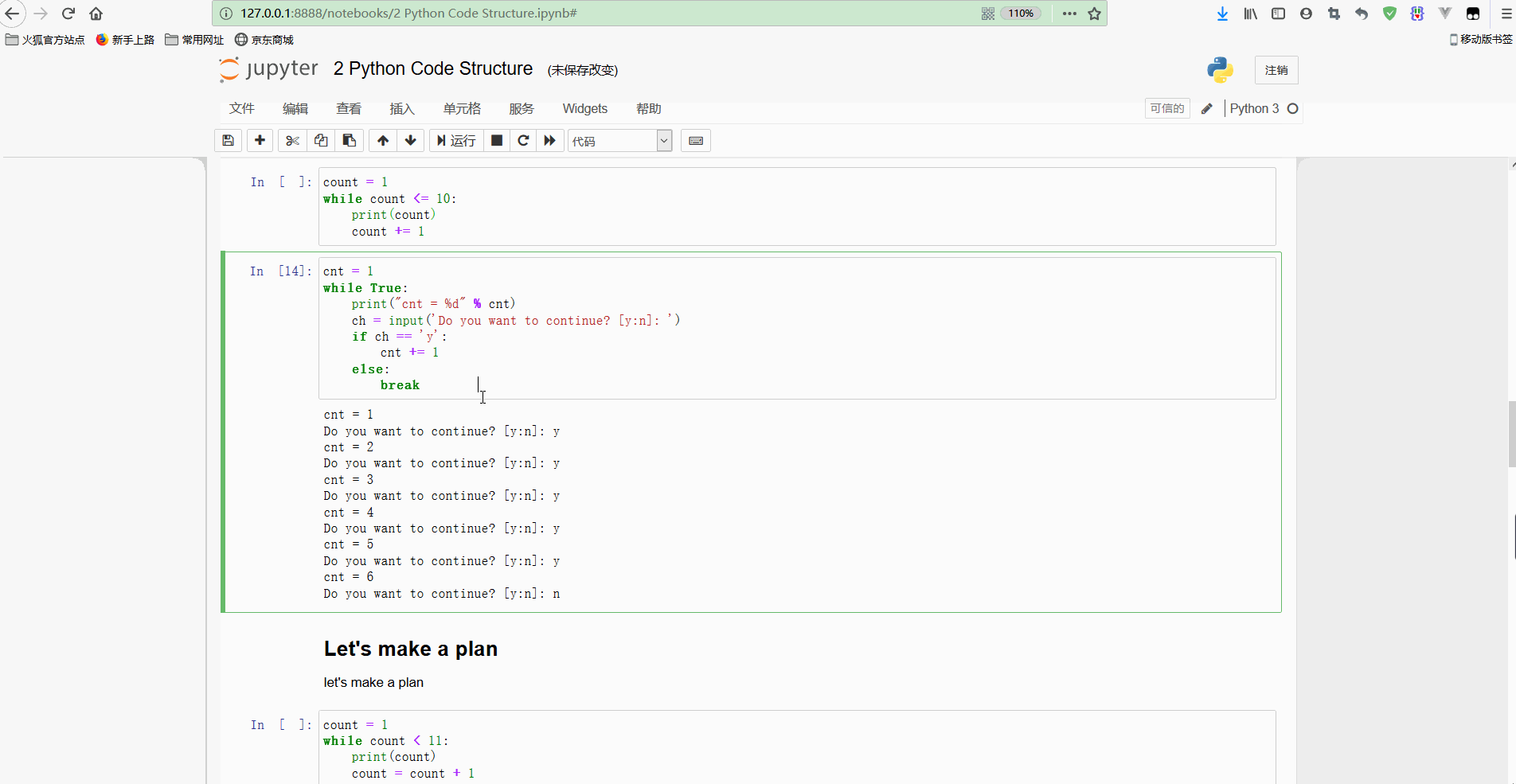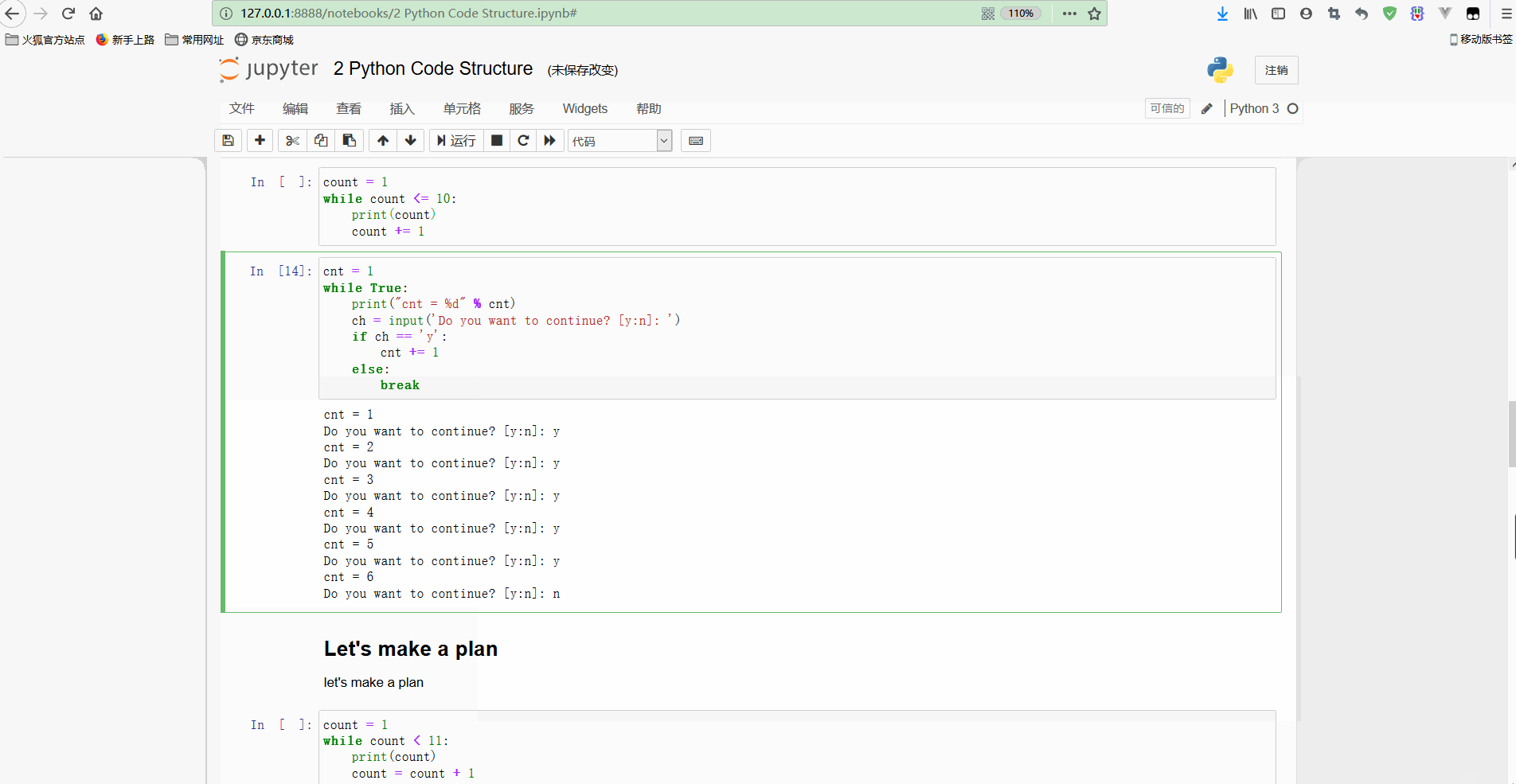
可以看到,虽然循环条件为True,是恒成立的,但是循环内部进行了条件判断,输入的是y就会一直循环,输入其他则执行break退出循环;
但是需要注意,这里只有严格地输入y才能继续循环,但是输入yes都会退出循环,所以要想进一步控制运行逻辑、还需要对代码进行完善。
在Python中,else也可以与while循环结合使用,如果循环不是因调用break而结束的,将执行else中的语句,这可以用于判断循环是不是完全执行,例如前面第1个循环的例子是不是运行了10次。
如下:
count = 1
while count < 11:
print(count)
count = count + 1
else:
print('Counting complete.')
print()
count = 1
while count < 11:
print(count)
count = count + 1
if count == 8:
break
else:
print('Counting complete.')输出:
1
2
3
4
5
6
7
8
9
10
Counting complete.
1
2
3
4
5
6
7可以看到: 第一个循环并没有因为break而停止循环,因此在执行完循环语句后执行了else语句; 第二个循环因为count为8时满足if条件而退出循环、并未将循环执行完毕,因此未执行else语句。
再如:
count=0
while count < 11:
print("while count:",count)
count = count + 1
if count == 11:
break
else:
print("else:",count)输出:
while count: 0
while count: 1
while count: 2
while count: 3
while count: 4
while count: 5
while count: 6
while count: 7
while count: 8
while count: 9
while count: 10显然,此时因为执行最后一次循环时满足if条件而执行了break语句,因此并未执行else语句块。
for循环
经常与for循环同时出现的还有range,range(self, /, *args, **kwargs)函数有以下两种常见的用法:
range(stop) -> range object
range(start, stop[, step]) -> range object该函数返回一个对象,该对象以step为步长生成从start(包含)到stop(排除)的整数序列。例如range(i, j)产生i,i+1,i+2,…,j-1的序列。
输入:
for i in range(10):
print(i)输出:
0
1
2
3
4
5
6
7
8
9再如:
for i in range(4,10):
print(i)
print()
for i in range(4,10,2):
print(i)
print()
for i in range(5):
print('Corley')
print()
for i in range(5):
print('Corley'[i])输出:
4
5
6
7
8
9
4
6
8
Corley
Corley
Corley
Corley
Corley
C
o
r
l
e可以看到,for循环内也可以执行与i无关的操作; 还可以用来遍历字符串。
for循环中也可以使用break语句来终止循环,如下:
for i in range(10):
print(i)
if i == 5:
break输出:
0
1
2
3
4
5再如:
result = 0
for num in range(1,100):
if num % 2 == 0:
result = result + num
print(result)输出:
2450上面的例子实现了计算从1到100(不包括)的所有偶数的和。
3.案例-王者荣耀纯文本分析
目标是从以下文本提取出所有的英雄信息链接、头像图片链接、英雄名称,如herodetail/194.shtml、http://game.gtimg.cn/images/yxzj/img201606/heroimg/194/194.jpg和苏烈:
<ul class="herolist clearfix"><li><a href="herodetail/194.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/194/194.jpg" width="91px" alt="苏烈">苏烈</a></li><li><a href="herodetail/195.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/195/195.jpg" width="91px" alt="百里玄策">百里玄策</a></li><li><a href="herodetail/196.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/196/196.jpg" width="91px" alt="百里守约">百里守约</a></li><li><a href="herodetail/193.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/193/193.jpg" width="91px" alt="铠">铠</a></li></ul>我们可以先找出一个英雄的信息,即使用下标进行字符串切分,找下标时使用find()方法。
例如,对于链接http://game.gtimg.cn/images/yxzj/img201606/heroimg/194/194.jpg,如果找到第一个h字母和最后一个g字母的下标,就可以通过切分将该链接提取出来。
先读入字符串,如下:
page_hero = '''<ul class="herolist clearfix"><li><a href="herodetail/194.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/194/194.jpg" width="91px" alt="苏烈">苏烈</a></li><li><a href="herodetail/195.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/195/195.jpg" width="91px" alt="百里玄策">百里玄策</a></li><li><a href="herodetail/196.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/196/196.jpg" width="91px" alt="百里守约">百里守约</a></li><li><a href="herodetail/193.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/193/193.jpg" width="91px" alt="铠">铠</a></li></ul>
'''此时再通过一步步地获取与目标相关字符的下标和根据下标切片来获取目标字符串,如获取图片链接如下:
start_link = page_hero.find('<img src="')
print(start_link)
start_quote = page_hero.find('"', start_link)
end_quote = page_hero.find('"', start_quote+1)
hero_link = page_hero[start_quote+1:end_quote]
print(hero_link)输出:
81
http://game.gtimg.cn/images/yxzj/img201606/heroimg/194/194.jpg此时再依次获取英雄名和信息链接如下:
# 第1个英雄
start_link = page_hero.find('<a href="')
start_quote = page_hero.find('"', start_link)
end_quote = page_hero.find('"', start_quote+1)
hero_info1 = page_hero[start_quote+1:end_quote]
print(hero_info1)
start_link = page_hero.find('<img src="', end_quote+1)
start_quote = page_hero.find('"', start_link)
end_quote = page_hero.find('"', start_quote+1)
hero_link1 = page_hero[start_quote+1:end_quote]
print(hero_link1)
end_bracket = page_hero.find('>', end_quote+1)
start_bracket = page_hero.find('<', end_bracket+1)
hero_name1 = page_hero[end_bracket+1:start_bracket]
print(hero_name1)输出:
herodetail/194.shtml
http://game.gtimg.cn/images/yxzj/img201606/heroimg/194/194.jpg
苏烈显然,已经获取到第1个英雄的完整信息。
此时再获取第2个英雄的信息,如下:
# 第2个英雄
page_hero = page_hero[start_bracket:]
start_link = page_hero.find('<a href="')
start_quote = page_hero.find('"', start_link)
end_quote = page_hero.find('"', start_quote+1)
hero_info2 = page_hero[start_quote+1:end_quote]
print(hero_info2)
start_link = page_hero.find('<img src="', end_quote+1)
start_quote = page_hero.find('"', start_link)
end_quote = page_hero.find('"', start_quote+1)
hero_link2 = page_hero[start_quote+1:end_quote]
print(hero_link2)
end_bracket = page_hero.find('>', end_quote+1)
start_bracket = page_hero.find('<', end_bracket+1)
hero_name2 = page_hero[end_bracket+1:start_bracket]
print(hero_name2)输出:
herodetail/195.shtml
http://game.gtimg.cn/images/yxzj/img201606/heroimg/195/195.jpg
百里玄策需要注意:
第二次切分不需要再在原字符串上进行切分、而只要从上次切分的位置开始查找和切分即可,所以page_hero = page_hero[end_quote:]即是将上次切分之后的子字符串重新赋值给page_hero作为新字符串;
因为各个英雄信息的字符串形式是一样的,所以可以直接利用查找第一个英雄的方式即可。
查找第3个和第4个英雄也类似如下:
# 第3个英雄
page_hero = page_hero[start_bracket:]
start_link = page_hero.find('<a href="')
start_quote = page_hero.find('"', start_link)
end_quote = page_hero.find('"', start_quote+1)
hero_info3 = page_hero[start_quote+1:end_quote]
print(hero_info3)
start_link = page_hero.find('<img src="', end_quote+1)
start_quote = page_hero.find('"', start_link)
end_quote = page_hero.find('"', start_quote+1)
hero_link3 = page_hero[start_quote+1:end_quote]
print(hero_link3)
end_bracket = page_hero.find('>', end_quote+1)
start_bracket = page_hero.find('<', end_bracket+1)
hero_name3 = page_hero[end_bracket+1:start_bracket]
print(hero_name3)
# 第4个英雄
page_hero = page_hero[start_bracket:]
start_link = page_hero.find('<a href="')
start_quote = page_hero.find('"', start_link)
end_quote = page_hero.find('"', start_quote+1)
hero_info4 = page_hero[start_quote+1:end_quote]
print(hero_info4)
start_link = page_hero.find('<img src="', end_quote+1)
start_quote = page_hero.find('"', start_link)
end_quote = page_hero.find('"', start_quote+1)
hero_link4 = page_hero[start_quote+1:end_quote]
print(hero_link4)
end_bracket = page_hero.find('>', end_quote+1)
start_bracket = page_hero.find('<', end_bracket+1)
hero_name4 = page_hero[end_bracket+1:start_bracket]
print(hero_name4)输出:
herodetail/196.shtml
http://game.gtimg.cn/images/yxzj/img201606/heroimg/196/196.jpg
百里守约
herodetail/193.shtml
http://game.gtimg.cn/images/yxzj/img201606/heroimg/193/193.jpg
铠可以看到,找4个英雄的思路都大致如下: (1)找到第一个出现的<img src= >=>start_link; (2)找到第一个出现的"=>start_quote; (3)找到start_quote+1之后那个引号 end_quote; (4)end_quote+1找到后面的>记作 end_bracket; (5)end_bracket+1 找到 start_bracket; (6)抛弃start_bracket之前的所有内容,再根据上面的方法找。
可以看到,3部分代码也有很大部分相似,因此可以使用循环来简化代码:
# 使用循环简化代码
page_hero = '''<ul class="herolist clearfix"><li><a href="herodetail/194.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/194/194.jpg" width="91px" alt="苏烈">苏烈</a></li><li><a href="herodetail/195.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/195/195.jpg" width="91px" alt="百里玄策">百里玄策</a></li><li><a href="herodetail/196.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/196/196.jpg" width="91px" alt="百里守约">百里守约</a></li><li><a href="herodetail/193.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/193/193.jpg" width="91px" alt="铠">铠</a></li></ul>
'''
for i in range(4):
print('第%d个英雄:' % (i+1))
start_link = page_hero.find('<a href="')
start_quote = page_hero.find('"', start_link)
end_quote = page_hero.find('"', start_quote+1)
hero_info = page_hero[start_quote+1:end_quote]
print(hero_info)
start_link = page_hero.find('<img src="', end_quote+1)
start_quote = page_hero.find('"', start_link)
end_quote = page_hero.find('"', start_quote+1)
hero_link = page_hero[start_quote+1:end_quote]
print(hero_link)
end_bracket = page_hero.find('>', end_quote+1)
start_bracket = page_hero.find('<', end_bracket+1)
hero_name = page_hero[end_bracket+1:start_bracket]
print(hero_name)
page_hero = page_hero[start_bracket:]输出:
第1个英雄:
herodetail/194.shtml
http://game.gtimg.cn/images/yxzj/img201606/heroimg/194/194.jpg
苏烈
第2个英雄:
herodetail/195.shtml
http://game.gtimg.cn/images/yxzj/img201606/heroimg/195/195.jpg
百里玄策
第3个英雄:
herodetail/196.shtml
http://game.gtimg.cn/images/yxzj/img201606/heroimg/196/196.jpg
百里守约
第4个英雄:
herodetail/193.shtml
http://game.gtimg.cn/images/yxzj/img201606/heroimg/193/193.jpg
铠
显然,代码精简很多。
二、函数的介绍和基本使用
函数是一段命名的代码,并且独立于所有其他代码。 函数可以接受任何类型的输入参数,并返回任意数量和类型的输出结果。 简而言之,函数可以代替大段代码,在需要使用这些代码的时候、直接调用函数即可,而不再需要重复大段代码,很大程度上优化了代码的结构、提高了代码的可读性。
定义一个不做任何事的函数如下:
# An empty function that does nothing
def do_nothing():
pass
do_nothing()
type(do_nothing)输出:
function其中,do_nothing()是调用函数,即函数名()。
定义一个不带参数和返回值的函数如下:
# A function without parameters and returns values
def greeting():
print("Hello Python")
# Call the function
a = greeting()输出:
Hello Python以后需要打印Hello Python的地方,就不用再使用print("Hello Python")语句,直接调用greeting()即可。
还可以定义带参数、但是不带返回值的函数:
# A function with a parameter that returns nothing
def greeting(name):
print("Hello %s" % name)
# Call the function
greeting('Corley')输出:
Hello Corley此时在调用函数时,传入了参数'Corley',会在函数内部使用,如果参数值变化,在函数内部被使用的变量也会同步变化,导致结果也可能变化。
但是此时:
print(a)输出:
None即返回为空,这是因为在函数内部并未定义返回值。 在需要时可以在函数内部定义返回值,以便用于下一步的运算。
如下:
# A function with a parameter and return a string
def greeting_str(name):
return "Hello again " + name
# Use the function
s = greeting_str("Corley")
print(s)输出:
Hello again Corley像许多编程语言一样,Python支持位置参数,其值按顺序复制到相应的参数中。即可以给函数传递多个参数,如下:
# A function with 3 parameters
def menu(wine, entree, dessert):
return "wine:{},entree:{},dessert:{}".format(wine,entree,dessert)
# Get a menu
menu('chardonnay', 'chicken', 'cake')输出:
'wine:chardonnay,entree:chicken,dessert:cake'为了避免位置参数混淆,可以通过参数对应的名称来指定参数,甚至可以使用与函数中定义不同的顺序来指定参数,即关键字参数。 如下:
menu(entree='beef', dessert='cake', wine='bordeaux')输出:
'wine:bordeaux,entree:beef,dessert:cake'显然,此时不按照顺序也可以实现传参。
甚至可以混合使用位置参数和关键字参数; 但是需要注意,在输入任何关键字参数之前,必须提供所有位置参数。
如果函数调用者未提供任何参数的默认值,则可以为参数设置默认值。 如下:
# default dessert is pudding
def menu(wine, entree, dessert='pudding'):
return "wine:{},entree:{},dessert:{}".format(wine,entree,dessert)
# Call menu without providing dessert
menu('chardonnay', 'chicken')输出:
'wine:chardonnay,entree:chicken,dessert:pudding'可以看到,此时也可以不给dessert参数传值也能正常运行,因为在定义函数时已经提供了默认值。
当然,也可以给dessert参数传值,此时就会使用传递的值代替默认值,如下:
# Default value will be overwritten if caller provide a value
menu('chardonnay', 'chicken', 'doughnut')输出:
'wine:chardonnay,entree:chicken,dessert:doughnut'在函数中,存在作用域,即变量在函数内外是否有效。 如下:
x = 1
def new_x():
x = 5
print(x)
def old_x():
print(x)
new_x()
old_x()输出:
5
1显然,第一个函数中的x在函数内部,属于局部变量,局部变量只能在当前函数内部使用; 第二个函数使用的x函数内部并未定义,因此使用函数外部的x,即全局变量,全局变量可以在函数内部使用,也可以在函数外部使用; 函数内部定义了与全局变量同名的局部变量后,不会改变全局变量的值。
要想在函数内部使用全局变量并进行修改,需要使用global关键字进行声明。
如下:
x = 1
def change_x():
global x
print('before changing inside,', x)
x = 3
print('after changing inside,', x)
print('before changing outside,', x)
change_x()
print('after changing outside,', x)输出:
before changing outside, 1
before changing inside, 1
after changing inside, 3
after changing outside, 3可以看到,此时在函数内部对变量进行修改后,函数外部也发生改变。
此时可以对之前王者荣耀纯文本分析案例进一步优化:
# 使用函数实现
def extract_info(current_page):
start_link = current_page.find('<a href="')
start_quote = current_page.find('"', start_link)
end_quote = current_page.find('"', start_quote+1)
hero_info = current_page[start_quote+1:end_quote]
print(hero_info)
start_link = current_page.find('<img src="', end_quote+1)
start_quote = current_page.find('"', start_link)
end_quote = current_page.find('"', start_quote+1)
hero_link = current_page[start_quote+1:end_quote]
print(hero_link)
end_bracket = current_page.find('>', end_quote+1)
start_bracket = current_page.find('<', end_bracket+1)
hero_name = current_page[end_bracket+1:start_bracket]
print(hero_name)
return start_bracket
start_bracket = 0
page_hero = '''<ul class="herolist clearfix"><li><a href="herodetail/194.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/194/194.jpg" width="91px" alt="苏烈">苏烈</a></li><li><a href="herodetail/195.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/195/195.jpg" width="91px" alt="百里玄策">百里玄策</a></li><li><a href="herodetail/196.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/196/196.jpg" width="91px" alt="百里守约">百里守约</a></li><li><a href="herodetail/193.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/193/193.jpg" width="91px" alt="铠">铠</a></li></ul>
'''
for i in range(4):
print('第%d个英雄:' % (i+1))
page_hero = page_hero[start_bracket:]
start_bracket = extract_info(page_hero) 输出:
第1个英雄:
herodetail/194.shtml
http://game.gtimg.cn/images/yxzj/img201606/heroimg/194/194.jpg
苏烈
第2个英雄:
herodetail/195.shtml
http://game.gtimg.cn/images/yxzj/img201606/heroimg/195/195.jpg
百里玄策
第3个英雄:
herodetail/196.shtml
http://game.gtimg.cn/images/yxzj/img201606/heroimg/196/196.jpg
百里守约
第4个英雄:
herodetail/193.shtml
http://game.gtimg.cn/images/yxzj/img201606/heroimg/193/193.jpg
铠显然,循环和函数结合使用,实现了功能,并且进一步简化代码。
除了使用for循环,还可以使用while循环,如下:
# 使用函数实现
def extract_info(i, current_page):
start_link = current_page.find('<a href="')
start_quote = current_page.find('"', start_link)
end_quote = current_page.find('"', start_quote+1)
hero_info = current_page[start_quote+1:end_quote]
start_link = current_page.find('<img src="', end_quote+1)
start_quote = current_page.find('"', start_link)
end_quote = current_page.find('"', start_quote+1)
hero_link = current_page[start_quote+1:end_quote]
end_bracket = current_page.find('>', end_quote+1)
start_bracket = current_page.find('<', end_bracket+1)
hero_name = current_page[end_bracket+1:start_bracket]
if hero_info.startswith('hero'):
print('第%d个英雄:' % i)
print(hero_info)
print(hero_link)
print(hero_name)
return start_bracket
else:
return -1
start_bracket = 0
i = 1
page_hero = '''<ul class="herolist clearfix"><li><a href="herodetail/194.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/194/194.jpg" width="91px" alt="苏烈">苏烈</a></li><li><a href="herodetail/195.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/195/195.jpg" width="91px" alt="百里玄策">百里玄策</a></li><li><a href="herodetail/196.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/196/196.jpg" width="91px" alt="百里守约">百里守约</a></li><li><a href="herodetail/193.shtml" target="_blank"><img src="http://game.gtimg.cn/images/yxzj/img201606/heroimg/193/193.jpg" width="91px" alt="铠">铠</a></li></ul>
'''
while True:
page_hero = page_hero[start_bracket:]
start_bracket = extract_info(i, page_hero)
i += 1
if start_bracket == -1:
break效果与前面一样。
三、函数进阶
1.可变位置参数
一般情况下,在定义了一个包含若干个参数的函数后,在调用时,也需要传递相同数量的参数值才能正常调用函数,否则会报错。
但是也可以看到,之前在调用print()函数时,每次要打印的变量数可能都不一样,即参数的数量可能是多变的,如果需要定义不变数量的参数,就需要使用参数*args,也称为可变位置参数。
如下:
def print_args(*args):
print('Positonal args:', args)
print('hello', 'Corley')
print('hello', 'Corley','again')
print('what', 'are','you','doing')输出:
hello Corley
hello Corley again
what are you doing显然,此时传入不同个数的参数,均可以正常调用函数。
查看args类型,如下:
def print_args(*args):
print(type(args))
print('Positonal args:', args)
print_args('hello')输出:
<class 'tuple'>
Positonal args: ('hello',)可以看到,传入的args类型被解析为元组,包含了传递的所有参数;
print()函数也是用类似的方式定义的。
此时定义函数时,传递参数可以更加灵活。 如下:
def print_args_with_required(req1, req2, *args):
print('req1:', req1)
print('req2:', req2)
print('all other args:', args)
print_args_with_required()此时会报错:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-79-0f8d1d1519ce> in <module>
4 print('all other args:', args)
5
----> 6 print_args_with_required()
TypeError: print_args_with_required() missing 2 required positional arguments: 'req1' and 'req2'因为这样定义函数,是表示req1和req2都是必须要传的参数,还可以根据需要决定是否需要传递其他参数,如果有则包含进args中,此时调用并没有传递前两个参数,因此会报错。
测试:
def print_args_with_required(req1, req2, *args):
print('req1:', req1)
print('req2:', req2)
print('all other args:', args)
print_args_with_required(1,2)
print_args_with_required(1,2, 3, 'hello')输出:
req1: 1
req2: 2
all other args: ()
req1: 1
req2: 2
all other args: (3, 'hello')此时,如果有多余的参数,则会放入元组。
2.可变关键字参数
前面在传入额外的参数时没有指明参数名,直接传入参数值即可,但是还可以指定参数名,此时称为可变关键字参数,形式为**kwargs。
如下:
def print_kwargs(**kwargs):
print('Keyword args:', kwargs)
print_kwargs(1,2)此时会报错:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-81-fbc2fa215023> in <module>
2 print('Keyword args:', kwargs)
3
----> 4 print_kwargs(1,2)
TypeError: print_kwargs() takes 0 positional arguments but 2 were given此时需要指定参数名,如下:
def print_kwargs(**kwargs):
print('Keyword args:', kwargs)
print_kwargs(fst=1,scd=2)输出:
Keyword args: {'fst': 1, 'scd': 2}可以看到,可变关键字参数被解析为字典。
可变位置参数和可变关键字参数可以结合使用。 如下:
def print_all_args(req1, req2, *args, **kwargs):
print('required args:', req1, req2)
print('Positonal args:', args)
print('Keyword args:', kwargs)
print_all_args(1,2,3,4,s='hello')输出:
required args: 1 2
Positonal args: (3, 4)
Keyword args: {'s': 'hello'}
在定义和调用函数时,需要注意3种参数的位置顺序: 必填参数位于最前,可变位置参数次之,可变关键字参数位于最后。
3.函数定义和查看文档字符串
在系统自定义的函数一般都有文档字符串,用来描述该函数的参数、用法注意事项等。
例如:
?print运行后,会在页面下方弹出框,内容为:
Docstring:
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
Type: builtin_function_or_method其中,第一部分就是内部定义的文档字符串。
自定义的函数也可以实现该功能,如下:
def odd_or_even(num):
'''
Return True id num is even,
or return False if num is odd
'''
return num % 2 == 0
?odd_or_even此时弹框中内容为:
Signature: odd_or_even(num)
Docstring:
Return True id num is even,
or return False if num is odd
File: XXX\<ipython-input-85-b86074aa0e21>
Type: function可以看到,是通过三对引号将文档字符串包裹起来的形式定义的,相当于注释作用,但是也是文档字符串。
还可以通过help()函数实现查看函数文档:
help(odd_or_even)输出:
Help on function odd_or_even in module __main__:
odd_or_even(num)
Return True id num is even,
or return False if num is odd或者使用函数对象的__doc__属性,如下:
print(odd_or_even.__doc__)输出:
Return True id num is even,
or return False if num is odd5.函数作为参数
函数本身也可以作为参数传递到另一个函数中,进行调用。
如下:
def ask():
print('Do you love Python?')
def answer():
print('Yes, I do')
def run_sth(func):
func()
run_sth(ask)
run_sth(answer)输出:
Do you love Python?
Yes, I do可以看到,也能正常执行。
还可以传递参数:
def bin_op(func, op1, op2):
return func(op1, op2)
def add(op1, op2):
return op1 + op2
def sub(op1, op2):
return op1 - op2
print('1 + 2 =', bin_op(add, 1,2))
print('1 - 2 =', bin_op(sub, 1,2))输出:
1 + 2 = 3
1 - 2 = -1还能定义嵌套函数。 如下:
def exp_factory(n):
def exp(a):
return a ** n
return exp
sqr = exp_factory(2)
print(type(sqr))
print(sqr(3))输出:
<class 'function'>
9可以看到,调用exp_factory(2)时返回的是exp()函数,其内部为return a ** 2,即求一个数的平方,所以再调用sqr(3)时,即是调用exp(3),所以返回3**2=9.
此即工厂函数模式,可以生产出具有特定功能的函数。 再如:
cube = exp_factory(3)
cube(3)输出:
276.装饰器
函数可以使用装饰器,实现单独使用函数所不能实现的额外功能。
简单地说:装饰器就是修改其他函数的功能的函数,其有助于让代码更简短,也更Pythonic。
例如:
def should_log(func):
def func_with_log(*args, **kwargs):
print('Calling:', func.__name__)
return func(*args, **kwargs)
return func_with_log
add_with_log = should_log(add)
add_with_log(2,3)输出:
Calling: add
5可以看到,通过传递函数到should_log()函数中,使得函数具有了其他功能,例如打印日志;
__name__属性用于获取函数的名字。
但是显得不太方便,此时可进一步简化如下:
@should_log
def add(op1, op2):
return op1 + op2
@should_log
def sub(op1, op2):
return op1 * op2
add(1, 2)
sub(1, 2)输出:
Calling: add
Calling: sub
2此时用更简单的方式实现了需要的功能,这就是装饰器,经常适用于授权和日志等方面。
7.匿名函数-lambda表达式
之前定义函数都是通过特定的形式定义出来的,如下:
def mul(op1, op2):
return op1 * op2可以看到,该函数通过def关键字定义,有函数名为mul,同时还有两个参数和返回值,但是实际上实现的功能很简单,就是求出两个数的乘积并返回,显然,如果用到该函数的地方较少或者与当前代码相隔较远就不太合适。
此时就可以使用匿名函数,即没有函数名的函数,也叫lambda表达式,可以实现函数的功能。
如下:
bin_op(lambda op1, op2:op1*op2, 2,4)输出:
8lambda表达式一般用于功能不复杂且使用不多的地方。
8.异常处理
很多时候,因代码逻辑的不正确会报错,也就是抛出异常,可以进行捕获和处理,从而使程序继续运行。
此时需要使用到try...except...语句。
如下:
def div(op1, op2):
try:
return op1 / op2
except ZeroDivisionError:
print('Division by zero')
div(5, 0)输出:
Division by zero可以看到,此时除数为0,但是并没有抛出异常,而是执行了except中的语句;
如果try代码块中无异常,则正常执行该代码块,否则执行except块中的代码。
还可以结合finally使用。
如下:
def div(op1, op2):
try:
return op1 / op2
except:
print('Division by zero')
finally:
print('finished')
div(5, 0)输出:
Division by zero
finished此时无论执行的是try还是except中的语句,最终都会执行finally中的语句。
异常处理可以提高程序的稳定性,尽可能降低异常对程序的影响。
还有额外的代码结构的练习,如有需要,可以直接点击加QQ群
本文原文首发来自博客专栏数据分析,由本人转发至https://www.helloworld.net/p/Mne4cgaiw7Ij8,其他平台均属侵权,可点击https://blog.csdn.net/CUFEECR/article/details/108751537查看原文,也可点击https://blog.csdn.net/CUFEECR浏览更多优质原创内容。












