
HashMap分析:
其主要特性:(key-value)存储,key-value可为NULL, 非线程安全。
其主要属性:
//默认容量微16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //最大容量2^30 static final int MAXIMUM_CAPACITY = 1 << 30; //默认装载因子0.75 static final float DEFAULT_LOAD_FACTOR = 0.75f; //空表 static final Entry[] EMPTY_TABLE = {}; //默认空表 transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; //元素个数 transient int size; //扩容阈值 int threshold; //装载因子:table中装入的元素/table的长度,超过此值会resize table final float loadFactor;
看看其构造函数:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init(); //空实现,子类可Override
}
HashMap中的元素就是通过Entry的数组实现,Entry为:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next; //后节点引用,HashMap采用链接表解决Hash冲突
int hash; //对应key的hash值
}
看看比较重要的put, get, remove等方法:
put方法实现:
图解即为:
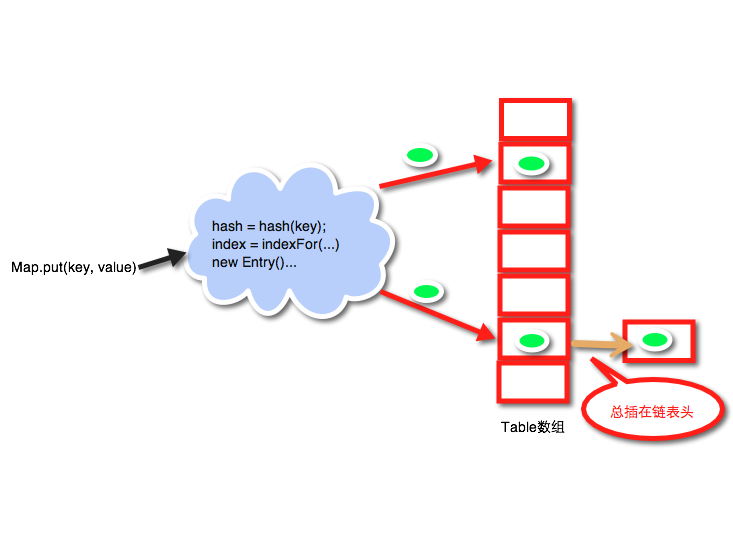
实现代码:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);//若为空表,就扩容
}
if (key == null)
return putForNullKey(value); //若key为null, hash值为0
int hash = hash(key); //根据key对象,算出其hash值
int i = indexFor(hash, table.length); //由hash值映射到table中某位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) { //是否有相同的key对象,有则替换原来的值,且返回旧值
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {//注意key类得Override equals,hashCode方法
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
看看inflateTable()方法:
private void inflateTable(int toSize) {
// 找到一个大于toSize,且为2的指数被的容量大小,方便hash值计算和元素索引计算
int capacity = roundUpToPowerOf2(toSize);
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
看看hash值怎么计算的:
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
得到了key对象hash值,还要算出其在table数组中的索引,看indexFor():
static int indexFor(int h, int length) {
//这里很巧,能保证无论hash值为多少,算出的索引都在数组索引范围内
return h & (length-1);
}
再看看怎么讲一个元素添加到table中的,addEntry()方法:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {//超过阈值,且table[butcketIndex]不为空
resize(2 * table.length); //扩容为原来2倍,HashMap没有提供定制扩容大小,怕你乱来
hash = (null != key) ? hash(key) : 0; //重新计算hash值
bucketIndex = indexFor(hash, table.length); //table变了,重新计算index
}
createEntry(hash, key, value, bucketIndex); //创建Entry
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e); //插入Entry, 相当于再链表头插入
size++;
}
对于get方法:
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key); //计算hash
for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null; e = e.next) {//遍历链表,比较
Object k;
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
对于remove方法:
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key); //计算hash
int i = indexFor(hash, table.length); //计算index
Entry<K,V> prev = table[i]; //链表头
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e) //删除的是链表头
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
这基本的HashMap分析。
HashTable分析:
对于HashTable,与HashMap原理基本一致,这里就说其与HashMap的不同之处:
HashTable对方法进行了synchronized, 因此线程安全,也是最大的区别;
默认容量不同:
public Hashtable() { this(11, 0.75f); //默认容量为11 }
key,value都不能为空, 扩容大小机制不同,Entry索引计算不同:
public synchronized V put(K key, V value) { // value不能为null if (value == null) { throw new NullPointerException(); } Entry tab[] = table; int hash = hash(key); //计算hash int index = (hash & 0x7FFFFFFF) % tab.length; //计算index for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { V old = e.value; e.value = value; return old; } }
modCount++; if (count >= threshold) { // Rehash the table if the threshold is exceeded rehash(); //扩容 tab = table; hash = hash(key); index = (hash & 0x7FFFFFFF) % tab.length; }
// Creates the new entry. Entry<K,V> e = tab[index]; tab[index] = new Entry<>(hash, key, value, e); count++; return null; }
其扩容函数rehash():
protected void rehash() {
int oldCapacity = table.length;
Entry<K,V>[] oldMap = table;
//扩容为2倍+1
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<K,V>[] newMap = new Entry[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
boolean rehash = initHashSeedAsNeeded(newCapacity);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) { //重新hash链表中的Entry到新table
for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
if (rehash) {
e.hash = hash(e.key);
}
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index];
newMap[index] = e;
}
}
}
hash算法不同:
private int hash(Object k) { return hashSeed ^ k.hashCode(); }
以后,就不用怕人问你HashMap和HashTable的区别,你就只知道同步问题,直接把代码写给他看,对于同步HashMap, 另外会分析ConcurrentHashMap的实现:http://my.oschina.net/indestiny/blog/209458
HashSet分析:
对于HashSet, 其实现完全分发给内部的HashMap成员变量,仅利用HashMap的key来实现, 从其属性便知:
private transient HashMap<E,Object> map;
//map的值都为这个对象
private static final Object PRESENT = new Object();
其add,remove方法都分发给了map对象:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
以上就简单分析了HashMap,HashTable,HashSet。
不吝指正。











