
作者:Vardan Agarwal
编译:ronghuaiyang
导读
深入研究所有不同EfficientNet结构的细节。
我在一个Kaggle竞赛中翻阅notebooks,发现几乎每个人都在使用EfficientNet 作为他们的主干,而我之前从未听说过这个。谷歌AI在这篇文章中:https://arxiv.org/abs/1905.11946介绍了它,他们试图提出一种更高效的方法,就像它的名字所建议的那样,同时改善了最新的结果。一般来说,模型设计得太宽,太深,或者分辨率太高。刚开始的时候,增加这些特性是有用的,但很快就会饱和,然后模型的参数会很多,因而效率不高。在EfficientNet中,这些特性是按更有原则的方式扩展的,也就是说,一切都是逐渐增加的。
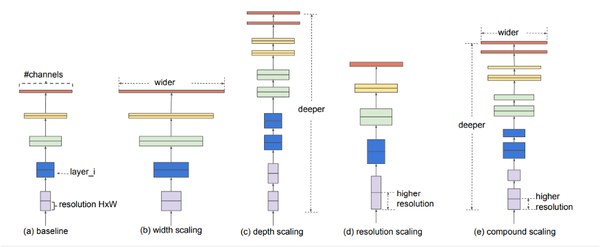
不明白发生了什么?不要担心,一旦看到了架构,你就会明白了。但首先,让我们看看他们得到了什么结果。
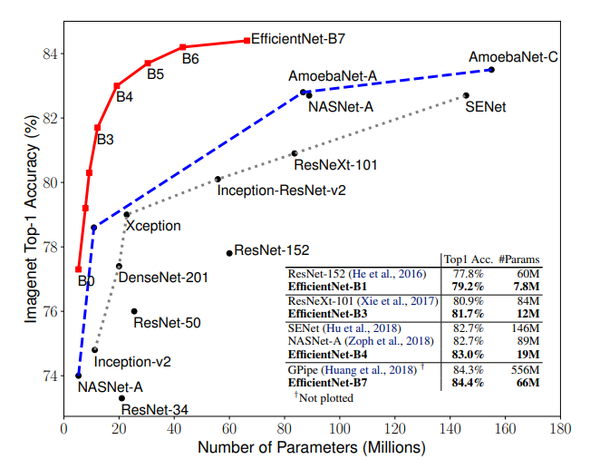
由于参数的数目相当少,这个模型族是非常高效的,也提供更好的结果。现在我们知道了为什么这些可能会成为标准的预训练模型,但是缺少了一些东西。
共同之处
首先,任何网络都以它为主干,在此之后,所有对架构的实验都以它为开始,这在所有8个模型和最后的层中都是一样的。
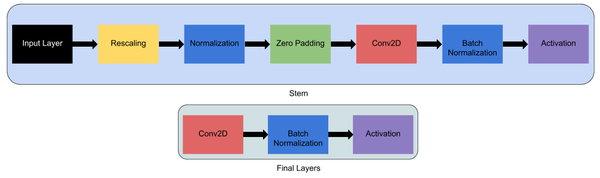
之后,每个主干包含7个block。这些block还有不同数量的子block,这些子block的数量随着EfficientNetB0到EfficientNetB7而增加。要可视化模型层,代码如下:
!pip install tf-nightly-gpu
import tensorflow as tf
IMG_SHAPE = (224, 224, 3)
model0 = tf.keras.applications.EfficientNetB0(input_shape=IMG_SHAPE, include_top=False, weights="imagenet")
tf.keras.utils.plot_model(model0) # to draw and visualize
model0.summary() # to see the list of layers and parameters
如果你计算EfficientNet-B0的总层数,总数是237层,而EfficientNet-B7的总数是813层!!但不用担心,所有这些层都可以由下面的5个模块和上面的主干组成。
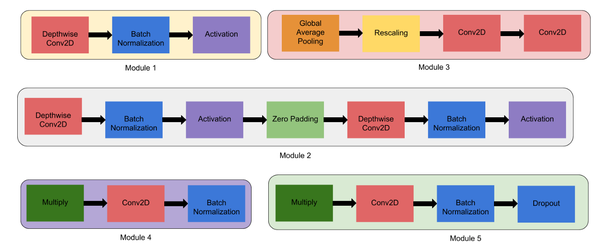
我们使用这5个模块来构建整个结构。
- 模块1 — 这是子block的起点。
- 模块2 — 此模块用于除第一个模块外的所有7个主要模块的第一个子block的起点。
- 模块3 — 它作为跳跃连接到所有的子block。
- 模块4 — 用于将跳跃连接合并到第一个子block中。
- 模块5 — 每个子block都以跳跃连接的方式连接到之前的子block,并使用此模块进行组合。
这些模块被进一步组合成子block,这些子block将在block中以某种方式使用。
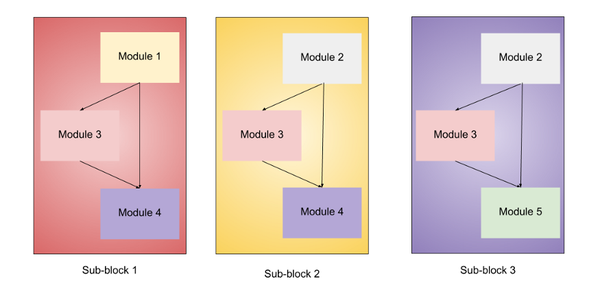
- 子block1 — 它仅用于第一个block中的第一个子block。
- 子block2 — 它用作所有其他block中的第一个子block。
- 子block3 — 用于所有block中除第一个外的任何子block。
到目前为止,我们已经指定了要组合起来创建EfficientNet模型的所有内容,所以让我们开始吧。
EfficientNet-B0
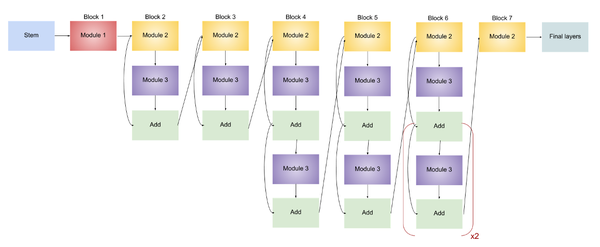
EfficientNet-B0架构。(x2表示括号内的模块重复两次)
EfficientNet-B1
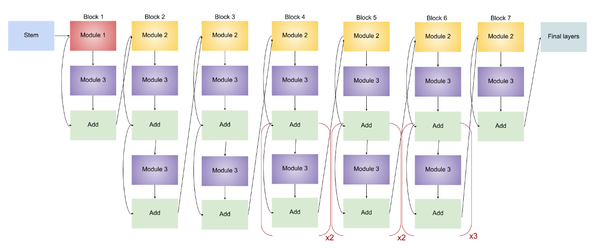
EfficientNet-B1的结构
EfficientNet-B2
它的架构与上面的模型相同,唯一的区别是特征图(通道)的数量不同,增加了参数的数量。
EfficientNet-B3
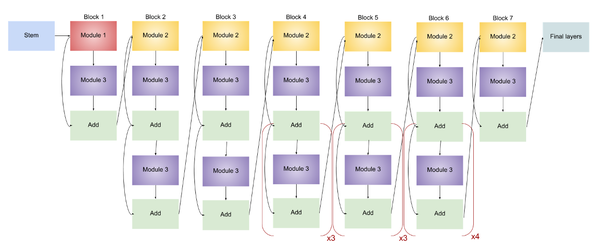
EfficientNet-B3的结构
EfficientNet-B4
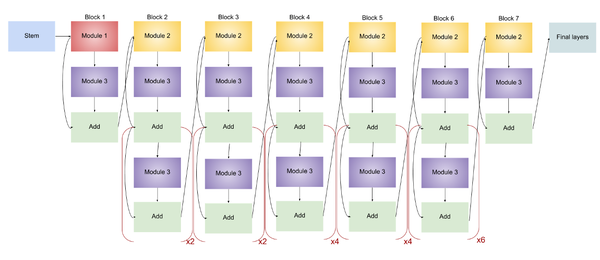
EfficientNet-B4的结构
EfficientNet-B5
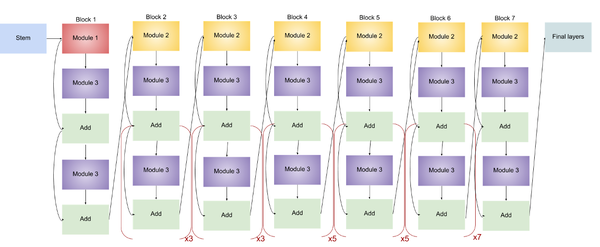
EfficientNet-B5的结构
EfficientNet-B6
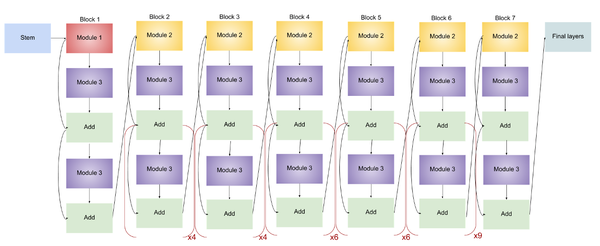
EfficientNet-B6的结构
EfficientNet-B7
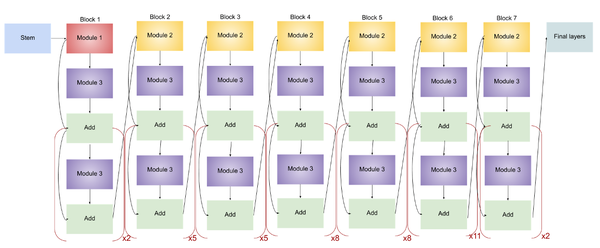
EfficientNet-B7的结构
很容易看出各个模型之间的差异,他们逐渐增加了子block的数量。如果你理解了体系结构,我鼓励你将任意的模型打印出来,并仔细阅读它以更彻底地了解它。下面的表表示了EfficientNet-B0中卷积操作的内核大小以及分辨率、通道和层。
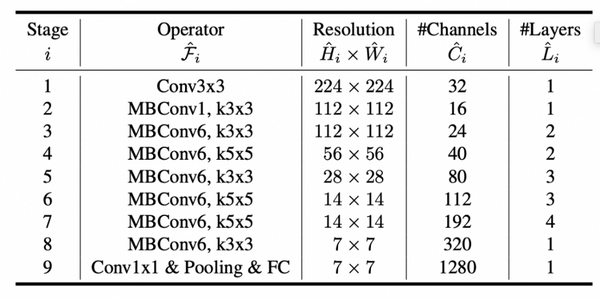
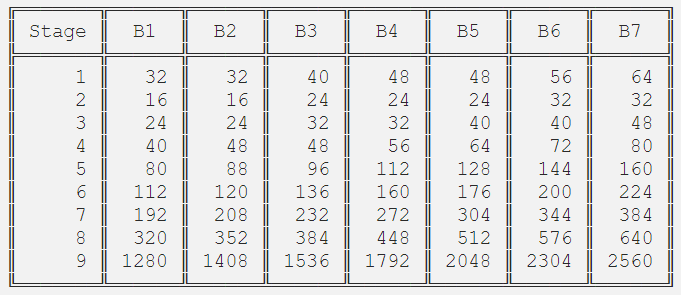
此表已包含在原始论文中。对于整个模型族来说,分辨率是一样的。我不确定卷积核的大小是否改变了。层的数量已经在上面的图中显示了。通道数量是不同的,它是根据从每个型号的摘要中看到的信息计算出来的,如下所示:
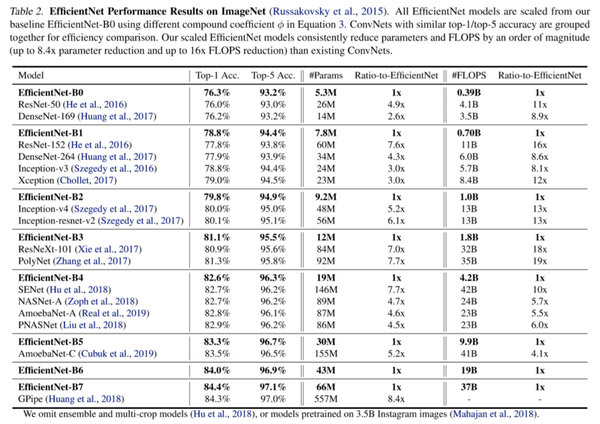
在结束之前,我附上了另一个图像,来自它的研究论文,显示了它与其他的SOTA的performance的比较,还有减少的参数的数量和所需的FLOPS。

—END—
英文原文:https://towardsdatascience.com/complete-architectural-details-of-all-efficientnet-models-5fd5b736142













