
1.软件简介
Rsync 是一个本地或远程数据同步工具,基于RSync算法,这个算法是澳大利亚人Andrew Tridgell发明的;可通过 LAN/WAN 快速同步多台主机间的文件。Rsync 本来是用以取代rcp 的一个工具,它当前由 Rsync.samba.org 维护。Rsync 使用所谓的“Rsync 演算法”来使本地和远程两个主机之间的文件达到同步,这个算法第一次全量传送,第二次增量传送两个文件的不同部分,而不是每次都整份传送,因此速度相当快。
运行 Rsync server 的机器也叫 backup server,一个 Rsync server 可同时备份多个 client 的数据;也可以多个Rsync server 备份一个 client 的数据。
Rsync 可以搭配 rsh 或 ssh 甚至使用 daemon 模式。Rsync server 会打开一个873的服务通道(port),等待对方 Rsync 连接。连接时,Rsync server 会检查口令是否相符,若通过口令查核,则可以开始进行文件传输。第一次连通完成时,会把整份文件传输一次,下一次就只传送二个文件之间不同的部份。
Rsync 支持大多数的类 Unix 系统,无论是 Linux、Solaris 还是 BSD 上都经过了良好的测试。此外,它在windows 平台下也有相应的版本,比较知名的有 cwRsync 和 Sync2NAS。
2.Rsync 的基本特点
2.1 优点
#支持拷贝普通文件与特殊文件如链接文件,设备等。
#可以有排除指定文件或目录同步的功能,相当于打包命令tar的排除功能。
tar zcvf backup_1.tar.gz /opt/data -exclude=dadong
说明:在打包/opt/data时就排除了dadong命令的目录和文件、
#可以做到保持源文件和目录的权限,时间,软硬链接,属主,组等所有属性均不变-p
可以实现增量同步,既只同步发生变化的数据,因此数据传输效率很高。(tar -N)
下面的命令将备份/home 目录昨天以来修改过的文件。
##tar -N $(date -d yesterday "+%F") -zcvf /backup/in-backup_$(date +%F).tar.gz /home
添加文件到已经压缩的文件
#tar -fr dadong.tar *.gif
说明:这个命令是将所有.gif的文件增加到dadong.tar的包里面去,-r是增加文件的意思。
#可以使用rcp,rsh,ssh等方式来配合进行隧道加密传输文件(rsync本身不对数据加密)
可以通过socket(进程方式)传输文件和数据
支持匿名的或认证(无需系统用户)的进程模式传输,可以实现方便安全的进行数据备份和镜像。
2.2、缺点
#大量小文件同步的时候,比对时间较长,有的时候,同步过程中,rsync过程可能会停止,僵死。
#同步大文件,10G这样的大文件有时会出现问题,中断。未完整同步前,是隐藏文件,可以通过续传(--partial)等参数实现传输。
#一次性远程拷贝可以用scp,大量小文件要打成一个包再拷贝。
3.rsync原理说明
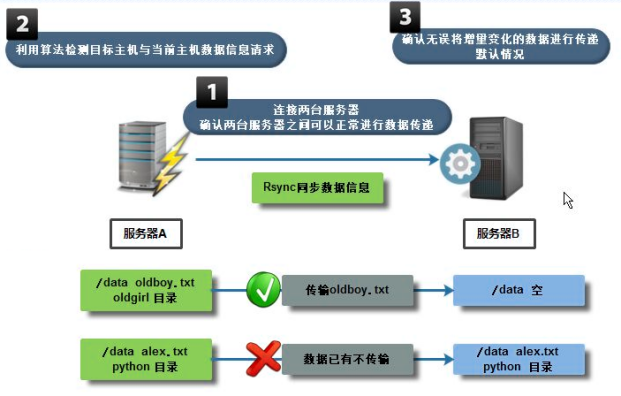
图示说明:
使用rsync进行数据同步时,涉及到增量备份和完全备份。
当服务器B上没有服务器A的要备份的文件内容,就进行完整备份;完整备份就是将源服务器上的信息完整的备份到目标服务器上。
当服务器B上存在服务器A上要备份的文件内容,只是有部分不一样时,就将进行增量备份;增量备份就是将源服务器上变动的内容备份到目标服务器上。
3.1 rsync原理解析
当Rsync通过一个远端SHELL和一个没有启动守护程序的服务器通讯的时候,Rsync所使用的启动方法是在远端系统上派生一个远端SHELL,然后使用这个远端SHELL启动一个Rsync进程。Rsync的客户机和服务器通过远端SHELL的管道进行通讯.在这种模式下, Rsync服务器选项被传送给命令行,用于启动远端SHELL。
当Rsync和一个守护程序通讯的时候, 它直接和网络插口通讯. 这是唯一一种可以被称为涉及网络的的Rsync通讯. 在这种模式下, Rsync的选项必须发送到网络插口上。 下面是具体的描述:
开始通信:
客户机和服务器最开始通讯的时候, 他们各自发送自己所支持的最高的协议版本号给对方. 两边会使用其中的小的版本作为用来传输的协议版本.
如果是一个守护模式连接,Rsync的参数会被从客户机发送给服务器. 然后, 排出列表会被传送. 然后,客户机服务器的关系就只和错误和日志发送有关了.
本地的Rsync任务(原地址和目标地址都是本地挂载的文件系统)就像一个推送.客户机:作为发送端, 派生一个服务器进程去行使服务器的功能. 客户机/发送端和服务器/接收端通过管道相互通讯。
文件列表:
文件列表不仅包括路径名,也包括所有者,模式, 读写权限, 大小和修改时间. 如果设置了--checksum选项, 文件列表还要包括文件的校验值.
Rsync启动完成后的第一件事, 发送端会建立文件列表. 在建立过程中, 每个条目都会通过一种优化的网络传送方式发送给接收方,传输结束后, 两侧会以目录对基础目录的相关性来编排顺序. (具体的算法会和每次传输实用的协议版本有关). 一旦排序开始, 所有关于文件的指向都是使用他们在文件列表中的目录顺序,如果必要, 发送者遵从文件列表中用户和组的id->name对应表, 接收者会使用它来为文件列表中的每个文件作id->name->id翻译, 接收端收到完全的文件列表, 会派生出一个生成器, 和接收端一起建立一个完整的管道。
管道
Rsync严重依赖於管道. 这意味着一组进程间的的单向通讯. 一旦文件列表被共享, 管道就表现为如下的形式: 生成器->发送端->接收端
生成器的输出是发送端的输入, 发送端的输出是接收端的输入. 每个进程独立的运行, 只有在管道延迟,或者等待硬盘读写或CPU资源的时候才会有延迟.
生成器
生成器比较文件列表和本地目录树. 如果设置了--delete参数, 在开始它的主要工作前, 它首先会甄别在本地存在而在发送端上不存在的文件, 然后在接收端删除它们.
接下来生成器会开始遍历文件列表. 每个文件都被检查, 以确定是否需要同步. 大多数情况下如果修改时间和大小不同, 文件需要同步. 如果设置了--checksum, 文件校验会被计算并比较. 目录, 设备文件和链结不会被跳过. 缺失的目录会被创建。
如果一个文件需要同步, 在接收端的任何版本的该文件都会被作为一个传输的"基础文件"."基础文件"作为一个数据源,两侧比较下来一致的数据就不需要被传输了. 为了更有效的在远端匹配数据, 基础文件的块校验被计算, 并和文件的目录号一起送给发送端.如果设置了--whole-file, 空的块校验值用于新文件.块大小, 以及在后期的版本中块校验的大小, 是基于每个文件的大小计算的,发送端进程一次从生成器读一组文件号和相关联的块校验。
对每一个生成器发送的文件号, 发送端会存储块校验, 并建立一个哈希索引以快速检索,接着本地文件会被读取, 生成一个从文件的第一个字节开始的块作的校验,这个校验会和生成器发过来的校验比较, 如果不相符, "不匹配"的字节会被加入到不匹配的数据中, 接着比较下一个字节的块. 这被称为"循环校验"。
如果一个块的校验匹配就会被认为是一个匹配的块, 已经积累的不匹配块会被发送给接收端, 一起发送的还有块的偏移量和在接受端文件中的匹配块的长度. 块校验生成器会提前去检查匹配字节后面的一个字节,即使块的顺序或者偏移量不同,以这种方法匹配的块也能够被确认. 这个程序是Rsync最核心的算法.通过这种方式, 发送者告诉接收端如何重组源文件成为一个目标文件. 这些指令包括所有的可以从基础文件拷贝的数据(如果存在的话), 和任何本地没有的新的数据, 的细节. 在处理末尾, 一个全文件的校验会被发送, 然后发送端去处理下一个文件,生成循环校验以及在校验中找到匹配的数据, 对CPU的能力有很大的需求. 在所有的Rsync进程中,发送端是最消耗CPU资源的.
接收端
接收端会从发送端的数据中读取由文件索引号确认的文件. 然后打开本地文件(被称为基础文件), 建立一个临时文件.
接收端会读取非匹配数据和匹配数据, 并按顺序重组他们成为最终文件. 当非匹配数据被读取, 它会被写入到临时文件. 当收到一个块匹配记录, 接收端会寻找这个块在基础文件中的偏移量, 将这个块拷贝到临时文件. 通过这种方式, 临时文件被从头到尾建立起来, 建立临时文件的时候生成了文件的校验. 重建文件结束后, 这个校验和来自发送端的校验比较. 如果校验不符, 临时文件会被删除. 如果失败一次, 文件会再被处理一次. 如果失败第二次, 一个错误会被报告,临时文件建立后, 所有者, 权限和修改时间会被设置. 然后它会被重命名已替代基础文件,
从基础文件拷贝数据到临时文件,使接收端成为所有进程中对硬盘要求最高的一个. 小文件还有可能在缓存中, 可以减轻对硬盘的压力; 但是对于大文件,在生成器去处理下一个文件的时候,或者还有由发送端造成的时延, 缓存中已经无法容纳更多的数据,只能清除掉旧的. 另外,数据是随机的从一个文件中读取, 并被写入另外一个, 如果读写的数据超过了硬盘缓存空间, 一个所谓的"寻找风暴"有可能发生,会进一步的损害性能.
守护程序
守护程序, 向所有的其他守护进程一样, 为每一个连接派生子进程. 启动的时候, 它解释rsyncd.conf, 以确认存在的模块, 并设置一些全局变量.
当接收到一个对已经定义的模块的连接时, 守护进程派生一个子进程去处理这个连接. 这个子进程然后去读取rsyncd.conf,
为被请求的模块设置变量, 这个工作有可能改变模块的root路径, 或者抛弃已设定的用户号和组号. 然后, 它就像其他的Rsync服务进程一样,或者作为发送端, 或者作为接收端.
4.rsync软件参数介绍
命令****参数
参数说明
**-**v ,--verbose
详细****模式输出,传输时的进度等信息
**-**z , --compress
*传输时进行压缩以提高传输效率,--compress-level=NUM可*按级别压缩
**-**a, --archive
归档****模式,表示以递归方式传输文件,并保持所有文件属性,等于-rtopgDl
-r, --recursive 归类于-a参数
对****子目录以递归模式,即目录下的所有目录都同样传输,注意是小写r
t ,--times 归类****于-a参数
保持****文件时间信息
*-o, --owner 归类于-a参数*
保持****文件属主信息
*-p,--perms 归类于-a参数*
保持****文件权限
*-g,--group 归类于*-a参数
保持****文件属组信息
**-**P,--progress
显示****同步的过程及传输时的进度等信息
*-D,--devices 归类于*-a参数
保持设备****文件信息
*-l,--links 归类于-a参数*
保留****软链接
**-**e,--rsh=COMMAND
使用的信道协议(re**mote shell),指定**替代rsh的shell程序。列如:ssh
--exclude****=PATTERN
指定排除不需要传输的文件信息(和tar参数类似)
**-**-exclude-from=file
文件名所在目录文件,****可以实现排除多个文件。
**-**-bwlimit=RATE
限速****功能。案例:某DBA做数据同步,带宽占满,导致用户无法访问网站
**-**-delete
让目标****目录SRC和源目录数据DST一致,即无差异同步数据。











