
一.所需软件
虚拟机:Vmware10.0.2.46408,通过百度可自行进行下载,也可通过http://pan.baidu.com/s/1eQtgi1k进行下载
Linux镜像:Centos,可通过下载ios进行安装系统,也可通过http://pan.baidu.com/s/1eQgoXQ6进行下载(该资源为我已经安装好之后的系统文件,解压缩后可通过打开CentOS.vmx来运行,用户名为root,密码为hadoop)
Hadoop版本: hadoop-1.1.2.tar.g,同样,即可自行下载,也可通过我的网盘进行下载http://pan.baidu.com/s/16L1eQ(版本可以自己选择,不同版本之间差异不是特别大,当然建议初学者选用和我相同的版本)
JDK版本:jdk-6u24-linux-i586.bin,JDK是Java运行所需的环境,由于是在虚拟机的Linux中安装Jdk,所以应该下载对应的系统的安装文件(而不是大家常用的windows下的安装文件),下载地址:http://pan.baidu.com/s/1dDq0sHr
其他软件(非必须,但建议使用,可以方便操作):Pietty,Winsap.其中Pietty是在windows平台下可以登录虚拟机的Linux系统(大家在使用虚拟机的时候,需要经常切换到windows环境中,而且如果是同时开3个虚拟机,切换起来很不方便,通过Pietty可以相当于windows下开启多个窗口,来控制不同的linux虚拟机)。Winsap是方便windows与虚拟机之间进行文件的传递http://pan.baidu.com/s/1hqxLMNq,http://pan.baidu.com/s/1ntwpDZb
二.配置网络
1、我采用的是虚拟机默认的模式,即仅主机模式(Host-only)。Vmvare安装好了之后,会在自己电脑网络适配器设置中多出两个连接

2、右击VMnet1,选择Properties,配置IPV4,我用的是192.168.80.1(当然这个也是可以更改的,不一定要和我相同)
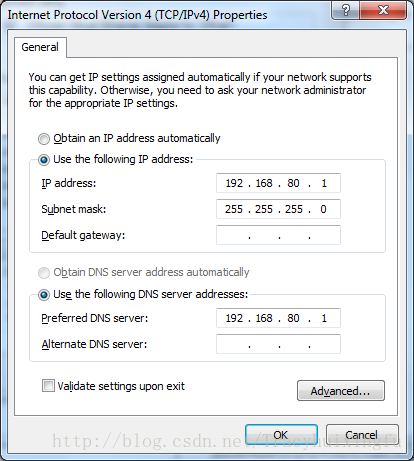
3、通过虚拟机打开安装之后的Linux系统,配置该Linux的网络设置(如果是通过我提供的网盘下载的,可以通过我下面介绍的方法来设置)
右击右上角的小电脑,Edit Conn...然后选中Edit(第一次打开可能还会有一个System的连接,删掉即可),按照下图同样配置该IPV4(选择静态的,其中Address可按照自己的来设置,但Gateway必须要和你之前设置的Vmnet1的IP地址相同)

4、配置好之后,打开终端,输入
service network restart
在windows下打开cmd命令,ping一下该虚拟机的IP地址,如果能ping通,代表已经配置好了。
由于我们是完全分布式的安装,我们准备使用三台虚拟机来构成这个集群,所以要开启三个虚拟机,每个虚拟机的网络都要进行设置,比如我的三个虚拟机的网络设置分别为:192.168.80.101,192.168.80.102,192.168.80.103
三.修改主机名
为啥要修改主机名?主机名类似于域名,比较容易记忆
1、如果以上配置好了之后,我们就可以最小化虚拟机了,然后通过Pietty来登录了。
打开软件之后,输入想要登录的IP地址(比如我想登录第一台虚拟机,对应输入192.168.80.101),其余不用修改,输入用户名密码之后即可登录
2、通过以下命令可以修改主机名为hadoop1,当然主机名也是可以按照自己的来修改
hostname hadoop1
但通过这种方式修改的,仅仅是当前会话生效,在关闭重新打开之后就会还原,所以我们还需要修改一个配置文件
vi /etc/sysconfig/network
修改成HOSTNAME=hadoop1,当然,对应到其他两台虚拟机,也可通过这种方式进行修改主机名。我修改之后的主机名分别为hadoop1,hadoop2,hadoop3
3、配置hosts文件,将主机名和IP绑定
vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.80.101 hadoop1
192.168.80.102 hadoop2
192.168.80.103 hadoop3
将主机名与IP地址对应起来。每个虚拟机都要进行绑定,不仅仅是绑定自己的IP和主机名,也要绑定另外两个,这个时候,就可以通过ping+主机名来互相ping通了。
四.关闭防火墙
关闭防火墙,并设置防火墙不自动开启
service iptables stop
chkconfig iptables off
五.配置SSH免密码登入
关于SSH免密码登入的原理在这就不多说,大家可以查阅一下资料。配置之后可以免密码连入其他的服务器(虚拟机),比如说hadoop1在连入hadoop2的时候就不需要输入密码。
1、通过cd进入root目录,运行命令,一直回车回车~
[root@hadoop1 ~]# ssh-keygen -t rsa
2、完成之后进入.ssh目录,复制pub中的内容到一个新的文件(文件名一定不能出错)
[root@hadoop1 .ssh]# cp id_rsa.pub authorized_keys
3、按照以上操作,对三个虚拟机都采用相同的操作,复制产生authorized_keys这个文件
4、这一步相当的关键,一定要操作对~将三个节点的authorized_keys的内容互相拷贝到对方的此文件中,然后就可以免密码彼此ssh连入了。注意:是每个节点的这个文件都要拷贝,操作完成之后三个节点的authorized_keys的内容应该是相同的。
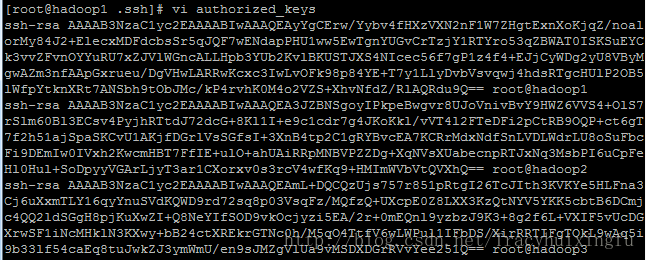
5、验证
[root@hadoop1 .ssh]# ssh hadoop2
回车,然后输入yes,就可登入hadoop2了。
六.安装JDK和Hadoop
1、打开winsap软件,输入hostname,username,password
登录之后,左边是你的本地的资源,右边是登入的linux系统的目录,可以将下载好的jdk和hadoop安装包直接拖到右边的linux下,我在这将文件拖到root目录下的Downloads文件夹,当然大家也可以自己随意选择。
拷贝到linux之后,我们就可以通过pietty查看到这两个文件了。
2、进入usr目录,新建一个文件夹作为jdk和hadoop的安装目录,
[root@hadoop1 ~]# cd /usr
[root@hadoop1 usr]# mkdir lh
[root@hadoop1 usr]# cd lh
3、将安装包拷贝到该文件夹(当前目录)
[root@hadoop1 lh]# cp /root/Downloads/* .
4、安装jdk,首先要给予jdk安装包执行权限,然后通过“.”来进行安装
[root@hadoop1 lh]# chmod u+x jdk-6u24-linux-i586.bin
[root@hadoop1 lh]# ./jdk-6u24-linux-i586.bin
安装完成之后,目录下会多了一个文件夹,就是安装之后的jdk,这个文件夹名字有点长,不利于以后操作,所以我将其修改为jdk
[root@hadoop1 lh]# mv jdk1.6.0_24 jdk
5、安装hadoop,首先解压hadoop,然后将其文件夹名改为hadoop
[root@hadoop1 lh]# tar -xzvf hadoop-0.20.2.tar.gz
[root@hadoop1 lh]# mv hadoop-0.20.2 hadoop
6、【灰常关键】设置jdk和hadoop的环境变量,这个类似于windows下安装jdk,因为jdk的命令是位于bin目录下,所以我们需要执行的话需要进入到bin下,但如果设置了环境变量,在其他地方也可以执行。hadoop也是如此
vi一下profile文件,然后在空白处输入以下内容,当然目录也是要根据自己的实际情况来,不要直接照抄
[root@hadoop1 lh]# vi /etc/profile
export JAVA_HOME=/usr/lh/jdk
export HADOOP_HOME=/usr/lh/hadoop
export PATH=.:$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
7、验证,输入以下命令
[root@hadoop1 lh]# hadoop version
如果能够打印出hadoop的版本,代表已经配置好了,就可以进行下一步了。同样,我们可以在其他的节点中安装jdk,但hadoop我们可以先不用再其他节点中安装,因为有很多配置文件需要配置,我们可以在一个节点配置好了之后复制到另外的节点,节省工作量。
七.修改hadoop配置文件
1、修改hadoop-env.sh,取掉export JAVA_HOME....前边的#,并且将值修改为你的jdk目录
<span style="white-space:pre"> </span>export JAVA_HOME=/usr/local/jdk/
2、修改core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/lh/tmp</value>
</property>
</configuration>
其中第一个property的value应该修改成你对应的主机名的,比如说hdfs://hadoop1:9000,其中hadoop1为我准备用于作为namenode的主机名,9000是端口,一般不用修改
3、修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
4、修改mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop1:9001</value>
<description>change your own hostname</description>
</property>
</configuration>
5、修改masters和slaves文件(这一点不同于伪分布式)
[root@hadoop1 conf]# vi masters
hadoop1
masters中输入你作为namenode的节点,
[root@hadoop1 conf]# vi slaves
hadoop2
hadoop3
slaves中输入作为datanode的节点
6、复制hadoop到其他节点,不要忘记到其他节点验证一下hadoop有木有安装成功~
[root@hadoop1 lh]# scp -r ./hadoop hadoop2:/usr/lh
[root@hadoop1 lh]# scp -r ./hadoop hadoop3:/usr/lh
八.格式化 分布式文件系统
[root@hadoop1 lh]# hadoop namenode -format
每个节点都要进入此操作。
八.启动进程
<span style="font-family: Arial, Helvetica, sans-serif; font-size: 12px;"><span style="white-space:pre"> </span>[root@hadoop1 lh]# start-all.sh</span>
1、通过该命令启动,可能会需要你问你yes/no,果断yes如果没其他情况,会输出一堆信息,然后就启动成功了
2、检测进程启动情况
[root@hadoop1 lh]# jps
30543 Jps
26850 JobTracker
26785 SecondaryNameNode
26649 NameNode
在主节点输入jsp,如果看到这几个进程,代表你启动成功了~然后到另外的节点,输入jsp,会看到Datanode节点。就代表你这个安装已经搞定了。
好了,以上就是hadoop的完全分布式安装步骤~希望大家转载的时候注明出处!谢谢












