
1. 导读
作为DAU过亿的国民出行服务平台,高德地图每天为用户提供海量的检索、定位和导航服务,实现这些服务需要有精准的道路信息,比如电子眼位置、路况信息、交通标识位置信息等。读者是否会好奇,高德是如何感知到现实世界的道路信息,并提供这些数据给用户呢?
事实上,我们有很多的方法将现实世界的道路要素采集回收,并更新到高德地图App上。其中一种非常重要的方法是利用计算机视觉的手段,将视觉算法部署到客户端,通过对图片的检测识别,快速将道路的信息回收。
为了低成本,高实时性地实现道路要素回收,我们借助MNN引擎(一个轻量级的深度神经网络推理引擎),将卷积神经网络模型部署到客户端,在客户端进行端侧的模型推理,从而完成在计算能力低,内存小的客户端进行道路要素采集的任务。
传统的CNN(卷积神经网络)计算量非常大,且业务场景需要部署多个模型。如何在低性能的设备上部署多个模型,并在不影响实时性的情况下保证应用的"小而优"是一个非常大的挑战。本文将分享利用MNN引擎在低性能设备上部署深度学习应用的实战经验。
2. 部署
2.1 背景介绍
如Figure2.1.1所示,业务背景是将道路要素识别相关的CNN模型部署到客户端,在端侧进行模型推理,并提取道路要素的位置和矢量等信息。
由于该业务场景的需要,目前端上需同时部署10+甚至更多的模型,以满足更多的不同道路要素的信息提取需要,对于低性能设备来说是非常大的挑战。

Figure 2.1.1 高德数据采集
为了达到应用的"小而优",MNN引擎部署模型的过程中遇到了很多问题和挑战。下面就这些问题和挑战分享一些经验和解决办法。
2.2 MNN部署
2.2.1 内存占用
应用运行内存对于开发者来说是始终绕不开的话题,而模型推理产生的内存在应用运行内存中占有很大的比例。因此,为了使模型推理内存尽可能小,在模型部署的过程中,作为开发者必须清楚模型运行产生内存的主要来源。根据我们的部署经验,部署单模型的过程中,内存主要来源于以下四个方面:

Figure 2.2.1 单模型部署内存占用
ModelBuffer: 模型反序列化的buffer,主要存储模型文件中的参数和模型信息,其大小和模型文件大小接近。
FeatureMaps: Featuremaps的内存,主要存储模型推理过程中,每一层的输入和输出。
ModelParams: 模型参数的内存,主要存储模型推理所需的Weights, Bias, Op等内存。其中Weights占用了该部分的大部分内存。
Heap/Stack: 应用运行中产生的堆栈内存。
2.2.2 内存优化
知晓模型运行内存占用后,就能方便理解模型运行时的内存变化。经过多个模型部署实践, 为了降低部署模型的内存峰值,我们采取的措施如下:
- 模型反序列化(createFromFile)并创建内存(createSession)后,将模型Buffer释放(releaseModel), 避免内存累加。
- 处理模型输入,图像内存和inputTensor可内存复用。
- 模型后处理,模型输出Tensor和输出数据的内存复用。

Figure 2.2.2.1 MNN模型部署内存复用方案
经过内存复用,以部署1个2.4M的视觉模型为例,模型运行时从加载到释放,中间各阶段所占用内存变化可以用以下曲线表示:

Figure 2.2.2.2 单模型应用内存曲线(Android memoryinfo统计)
- 模型运行前,模型占用内存为0M。
- 在模型加载(createFromFile)和创建内存(createSession)后,内存升到5.24M, 来源于模型反序列化和Featuremaps内存创建。
- 调用releaseModel内存降低至3.09M,原因是释放了模型反序列化后的buffer。
- InputTensor和图像内存复用,应用内存增加到4.25M, 原因是创建了存储模型输入的Tensor内存。
- RunSession(),应用内存增加到5.76M,原因是增加了RunSession过程中的堆栈内存。
- 在模型释放后,应用恢复到了模型加载前的内存值。
经过多次模型部署的实践,下面总结了部署单模型到端的内存峰值预估公式:

MemoryPeak:单模型运行时内存峰值。
StaticMemory:静态内存,包括模型Weights, Bias, Op所占内存。
DynamicMemory:动态内存,包括Feature-maps所占内存。
ModelSize:模型文件大小。模型反序列化所占内存。
MemoryHS:运行时堆栈内存(经验取值0.5M-2M之间)。
2.2.3 模型推理原理
本章节分享模型推理原理,以便于开发者遇到相关问题时,快速定位和解决问题。
模型推理前模型的调度: MNN引擎推理保持了高度的灵活度。即可以指定模型不同的运行路径,也可以对不同的运行路径指定不同的后端,以提高异构系统的并行性。此过程主要是调度或者任务分发的过程。
对于分支网络,可以指定当前运行分支,也可以调度分支执行不同后端,提高模型部署的性能。图Figure2.2.3.1所示为一个多分支模型, 两个分支分别输出检测结果和分割结果。

Figure 2.2.3.1 多分支网络
部署时可做如下优化 :
- 指定模型运行的Path。当仅需检测结果时,只跑检测分支,无需跑完两个分支, 减小模型推理时间。
- 检测和分割指定用不同的后端。比如检测指定CPU, 分割指定OpenGL,提高模型并行性。
模型推理前的预处理: 本阶段会根据上一步的模型调度信息进行预处理,本质是利用模型信息和用户输入配置信息,进行Session(持有模型推理数据)的创建。
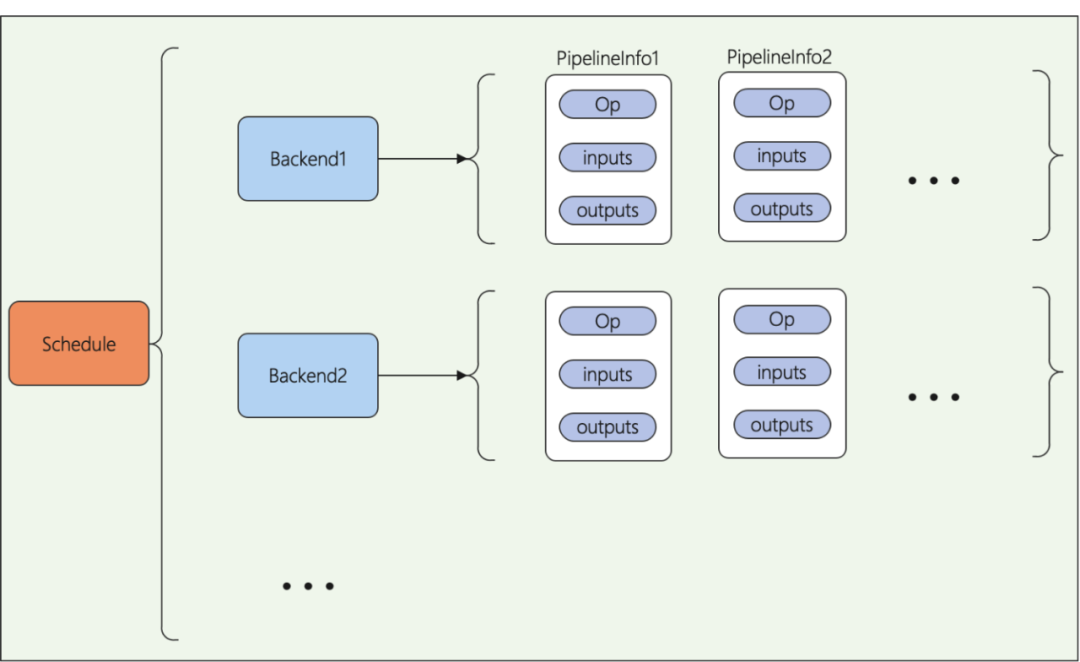
Figure 2.2.3.2 根据Schedule创建Session
本阶段根据模型反序列化的模型信息和用户调度配置信息来进行运算调度。用于创建运行的Piplines和对应的计算后端。如Figure2.2.3.3所示。

Figure 2.2.3.3 Session创建
模型的推理: 模型推理本质是根据上一步创建的Session,依次执行算子的过程。运算会根据预处理指定的模型路径和指定后端进行模型每层的运算。值得一提的是,算子在指定的后端不支持时,会默认恢复到备用后端执行计算。

Figure 2.2.3.4 模型推理计算图
2.2.4 模型部署时间
本部分统计了单模型部署过程各阶段耗时,方便开发者了解各阶段的耗时,以便更好的设计代码架构。(不同设备有性能差异,耗时数据仅供参考)
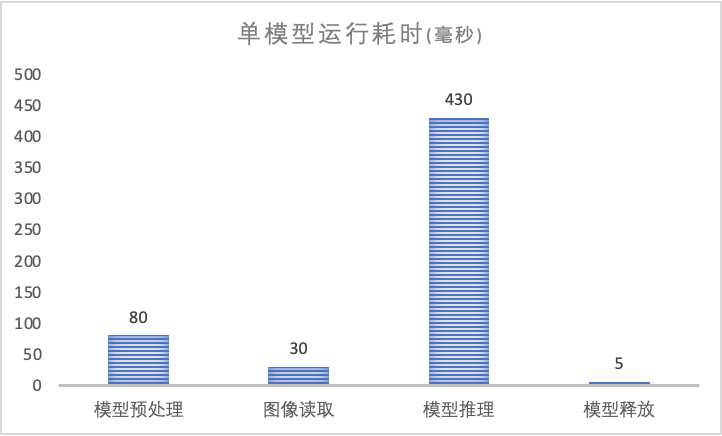
Figure 2.2.4.1 模型推理计算图
模型反序列化和Session创建相对耗时较长,进行多张图的推理时,尽量执行一次。
2.2.5 模型误差分析
模型部署时,开发者难免会遇到部署端和X86端(Pytorch, Caffe, Tensorflow)训练模型输出结果有偏差的情况。下面分享误差原因, 定位思路以及解决办法。
模型Inference示意图如Figure 2.2.5.1所示:

Figure 2.2.5.1 模型Inference示意图
模型误差的确定: 查看是否有模型误差最直观的方法是,固定部署端模型和X86端模型的输入值,分别推理,对比部署端模型和X86端模型输出值,可确认是否有误差。
模型误差的定位: 当确定有模型误差时,先排除因模型输入误差导致的模型输出误差。因为X86端和部分Arm设备浮点的表示精度不一致,输入误差在某些模型中会被累积,最终造成较大的输出误差。用什么方法来排除是输入误差导致的问题呢?我们提供一种方法是将模型输入设置为0.46875(原因是该值在X86设备和部分Arm设备表示一致,本质是1经过移位获得的浮点数在两种端上表示均一致)。然后观察输出是否一致即可。
模型误差的定位思路: 在排除模型输入误差导致模型输出误差(即模型输入一致时,模型输出不一致)的情况下,很可能是模型某些算子导致的误差了。如何定位模型哪个OP导致的误差呢?通过下述的步骤可以定位模型内部引起误差的原因:
1)通过runSessionWithCallBack来回调模型每个OP的中间计算结果。目的是定位模型从哪个Op开始出现误差。
2)定位到该层之后,即可定位到产生误差的算子。
3)定位到算子后,通过指定的后端信息即可定位到对应的算子执行代码。
4)定位到对应的执行代码后,调试定位产生误差的代码行,从而定位到产生模型误差的根本原因。
3. 总结
MNN引擎是一个非常好的端侧推理引擎,作为开发者来说,模型的端上部署和性能优化在关注业务逻辑优化的同时,也需关注对引擎计算过程,框架设计和模型加速的思想,反过来可以更好的优化业务代码,做出真正"小而优"的应用。
4.未来规划
随着设备性能的普遍提升,后续的业务会搭载到性能更高的设备,我们会利用更丰富的计算后端做模型的加速,比如OpenCL, OpenGL等, 从而加速模型的推理。
未来设备会搭载更多的模型到客户端,用于实现更多品类道路要素信息的回收,我们也会利用MNN引擎,探究更高效,更高实时性的代码部署框架,以更好的服务于地图采集业务。
我们是高德地图数据研发团队,团队中有大量HC,欢迎对Java后端、平台架构、算法端上工程化(C++)、前端开发感兴趣的小伙伴加入,请发送您的简历到 gdtech@alibaba-inc.com ,邮件标题格式: 姓名-技术方向-来自高德技术。我们求贤若渴,期待您的加入。










