
第2章 ACT 与 Beetlsql 的搭配实战
上一节为了便利,我们使用 H2 做为示例数据库,本节我们将使用国内目前最多人使用的 MySQL,来实战一下.
在本节里我们一起学习:
- ACT里如何连接数据库及配置多个数据源
- ACT里如何配置特定的数据库连接池
- 项目的通用结构
- BeetlSQL 链式查询新姿势
同样的,您需要先下载示例项目: https://github.com/mailtous/act-eagle-allone
注意:这是本人写的示例项目,您可以当作是 ACT+BeetlSQL 的脚手架使用. 当然了一切的失误都跟 ACT 无关,都是本人水平的事. 附带的福利就是,在act-eagle-allone项目里,您同时收获了一套基本的后台权限管理. 相信我这套权限管理已经满足一般的小型企业的WEB网站的后台管理需求了.
如您所见,我们先来看一下项目的整体结构:
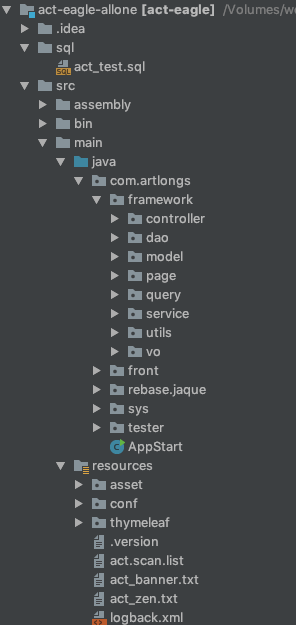
第一步: 您需要先把 SQL 目录下的SQL脚本在本地 MYSQL客户端上执行一下.
第二步: 打开/resources/conf/dev/db.properties 文件

如您所见,非常简单: db.instances=default,db2 代表我们可以使用多个数据库
而: db.default.datasource.provider 这项配置就是为了配置特定的数据库连接池的. 你也许会喜欢用 Druid CP. 不过呢,以 HikariCP 目前无敌的实力, ACT 官方以 HikariCP 做为默认的首选数据库连接池了.所以此项不配置也没关系的. ACT 开发的准则之一就是易用性.
细心如您,已经发现了 conf 目录下还有 common/dev/prod 子目录.他们代表了[通用/本地开发/线上]环境, 为什么要这样规划呢?
这样做的好处呢,就是部署时:设置 JVM 参数 -Dprofile=dev|sit|prod , ACT 自己就帮你搞定了.

更多的配置打开方式,参见: https://github.com/actframework/act-doc/blob/master/cn/configuration.md
你还需要留意 framework 这个目录: 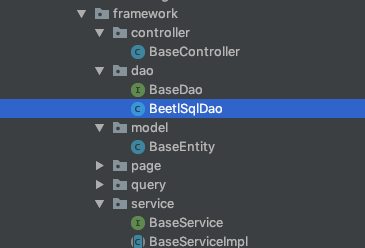
如您所见,强烈的 SPRING 老味道, 却是这个脚手架的核心点. 但我不得不说的事,您的项目经理会喜欢这种分层的.
重申: 以结上司之欢心,谋吾等码农之福利! 这点很重要的!
您注意到: BeetlSqlDao 这个基类吗? 这是我对 BeetlSql 做的一个小小的封装,以便更好的使用 CURD.
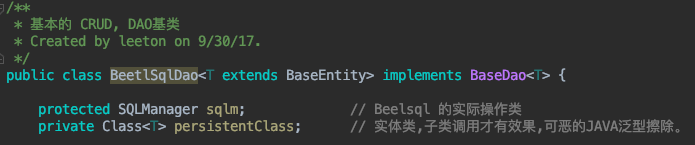
而 framework 的 API 将会在实际的 Sys 模块被使用到.
好了,说好的新姿势呢? 我已经看到猴急的同学已经脱下了TA的新裤子了! 瞧!TA在那大喊: 老东西,快点了! [我的大斧早已饥渴难耐了!]
广告:推荐大家看一下,烟雨江南的《狩魔手记》,我觉得他是新时代的金庸!
第二节,从这里开始, 以上的字节不收费,好吗?
其实新姿势就特么简单:
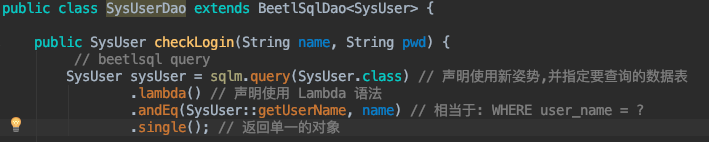
新姿势有什么好处呢?
- 真正的敏捷开发从这里开始
- 你无需编写 .md 文件并且在里面写 SQL 了
- SysUser::getUserName 这种引用字段的拼写方式,使得 SQL 不再有[硬代码].
- [硬代码]有什么危害? 相信有重构项目经验的同学会深有体会的.
- 更多的好处您慢慢体会,这里不接受争议.
写这个示例项目的时候,其实我并不知道 BeetlSQL 有链式查询的新姿势. 为此,我还在 /framework/query 目录下开发了一套链式查询工具. 真的只是个巧合,语法相近,但实现的方式却是不一样的.
后来我还把这个链式查询抽取出来做成了 Fluent-SQL 项目,写到这里请允许小生我带点私货:
https://github.com/mailtous/fluentsql
好了,下课了. 相信我,看到这里的您,已经成长为一位老司机了, 一起来一盘<<王者>>吧!
记住:猥琐发育别浪!














