
点击上方“ Python爬虫与数据挖掘 ”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
少年心事当拂云。

1
前言
网路爬虫,一般爬取的东西无非也就四种:文字、图片、音乐、视频。
这是明面上,能想到的东西,除了这些还有一些危险的操作,容易被请喝茶的,就不讨论了。
咱们循序渐进,先谈谈如何下载文字内容。
PS:文中出现的所有代码,均可在我的 Github 上下载:
https://github.com/Jack-Cherish/python-spider/tree/master/2020
2
诡秘之主
说到下载文字内容,第一个想到的就是下载小说了。
在曾经的以《一念永恒》小说为例进行讲解的 CSDN 文章中,有网友留言道:

那么,今天我就再安利一本小说《诡秘之主》。
起点中文网,它的月票基本是月月第一。
这篇文章其实是在教大家如何白嫖,不过有能力支持正版的朋友,还是可以去起点中文网,支持一下作者的,毕竟创作不易。
3
准备工作
话不多说,直接进入我们今天的正题,网络小说下载。
1、背景介绍
小说网站,“新笔趣阁”:
盗版小说网站有很多,曾经爬过“笔趣看”,这回咱换一家,爬“新笔趣阁”,雨露均沾嘛!
“新笔趣阁”只支持在线浏览,不支持小说打包下载。本次实战就教大家如何“优雅”的下载一篇名为《诡秘之主》的网络小说。
2、爬虫步骤
要想把大象装冰箱,总共分几步?
要想爬取数据,总共分几步?
爬虫其实很简单,可以大致分为三个步骤:
发起请求:我们需要先明确如何发起 HTTP 请求,获取到数据。
解析数据:获取到的数据乱七八糟的,我们需要提取出我们想要的数据。
保存数据:将我们想要的数据,保存下载。
发起请求,我们就用 requests 就行,上篇文章已经介绍过。
解析数据工具有很多,比如xpath、Beautiful Soup、正则表达式等。本文就用一个简单的经典小工具,Beautiful Soup来解析数据。
保存数据,就是常规的文本保存。
3、Beautiful Soup
简单来说,Beautiful Soup 是 Python 的一个第三方库,主要帮助我们解析网页数据。
在使用这个工具前,我们需要先安装,在 cmd 中,使用 pip 或 easy_install 安装即可。
pip install beautifulsoup4
安装好后,我们还需要安装 lxml,这是解析 HTML 需要用到的依赖:
pip install lxml
Beautiful Soup 的使用方法也很简单,可以看下我在 CSDN 的讲解或者官方教程学习,详细的使用方法:
我的 Beautiful Soup 讲解:
https://blog.csdn.net/c406495762/article/details/71158264
官方中文教程:
https://beautifulsoup.readthedocs.io/zh\_CN/latest/
4
小试牛刀
我们先看下《诡秘之主》小说的第一章内容。
URL:https://www.xsbiquge.com/15\_15338/8549128.html
我们先用已经学到的知识获取 HTML 信息试一试,编写代码如下:
import requests
这也就是爬虫的第一步“发起请求”,得到的结果如下:
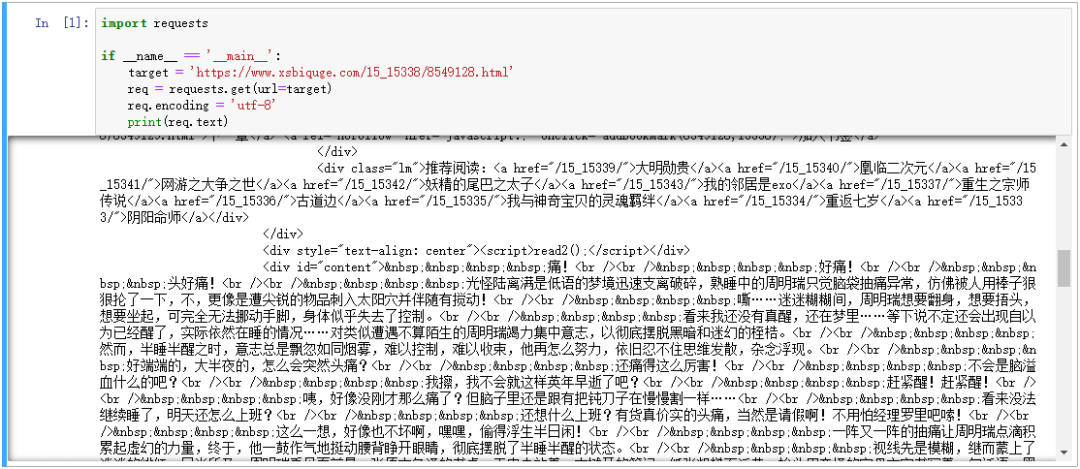
可以看到,我们很轻松地获取了 HTML 信息,里面有我们想要的小说正文内容,但是也包含了一些其他内容,我们并不关心 div 、br 这些 HTML 标签。
如何把正文内容从这些众多的 HTML 标签中提取出来呢?
这就需要爬虫的第二部“解析数据”,也就是使用 Beautiful Soup 进行解析。
现在,我们使用上篇文章讲解的审查元素方法,查看一下我们的目标页面,你会看到如下内容:
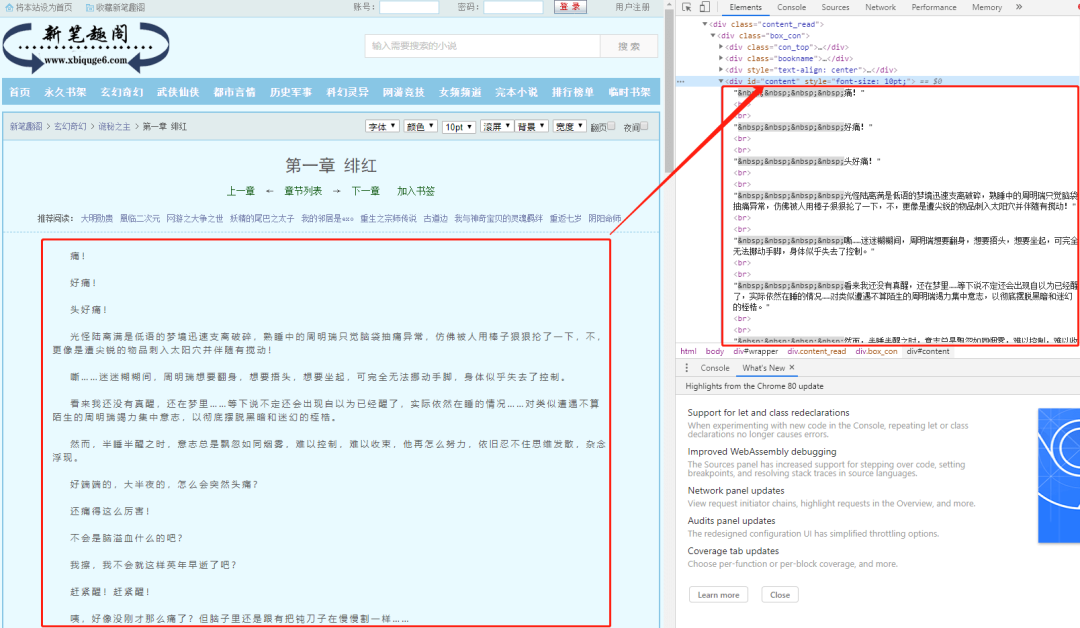
不难发现,文章的所有内容都放在了一个名为div的“东西下面”,这个"东西"就是 HTML 标签。HTML 标签是 HTML 语言中最基本的单位,HTML 标签是 HTML 最重要的组成部分。不理解,没关系,我们再举个简单的例子:
一个女人的包包里,会有很多东西,她们会根据自己的习惯将自己的东西进行分类放好。镜子和口红这些会经常用到的东西,会归放到容易拿到的外侧口袋里。那些不经常用到,需要注意安全存放的证件会放到不容易拿到的里侧口袋里。
HTML 标签就像一个个“口袋”,每个“口袋”都有自己的特定功能,负责存放不同的内容。显然,上述例子中的 div 标签下存放了我们关心的正文内容。这个 div 标签是这样的:
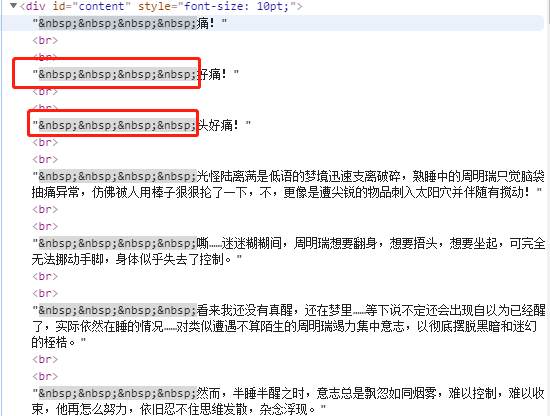
<div id="content" style="font-size: 10pt;">
细心的朋友可能已经发现,除了 div 字样外,还有 id 。id 就是 div 标签的属性,content是属性值,一个属性对应一个属性值。
属性有什么用?它是用来区分不同的 div 标签的,因为 div 标签可以有很多,id 可以理解为这个 div 的身份。
这个 id 属性为 content 的 div 标签里,存放的就是我们想要的内容,我们可以利用这一点,使用Beautiful Soup 提取我们想要的正文内容,编写代码如下:
import requests
代码很简单,bf.find('div', id='content') 的意思就是,找到 id 属性为 content 的 div 标签。
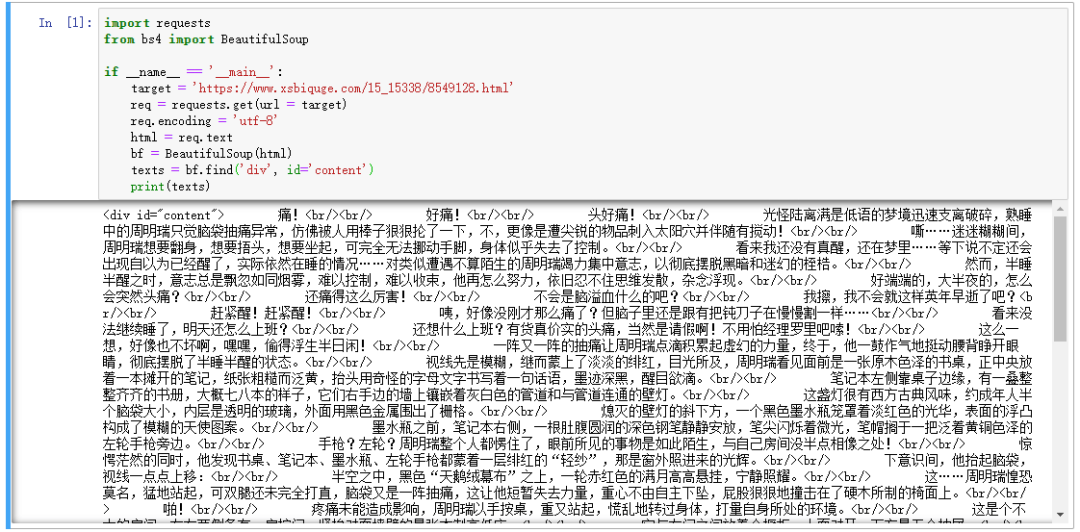
可以看到,正文内容已经顺利提取,但是里面还有一些 div 和 br 这类标签,我们需要进一步清洗数据。
import requests
texts.text 是提取所有文字,然后再使用 strip 方法去掉回车,最后使用 split 方法根据 \xa0 切分数据,因为每一段的开头,都有四个空格。
程序运行结果如下:
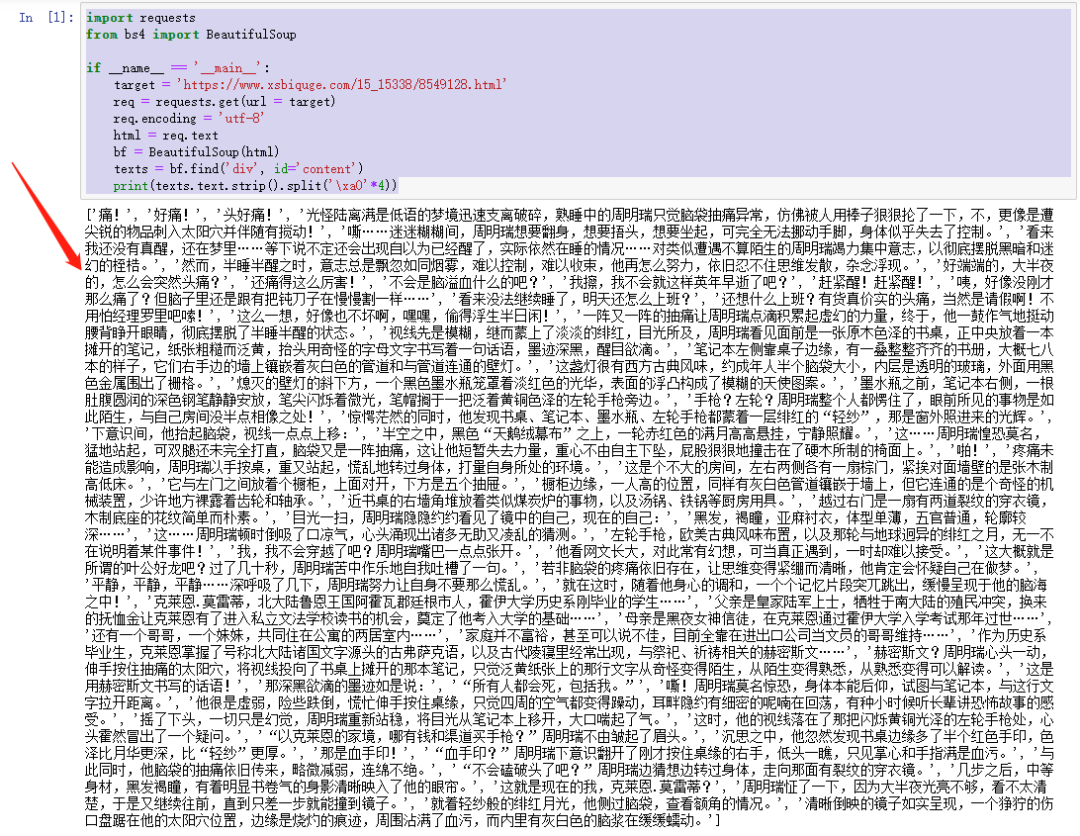
所有的内容,已经清洗干净,保存到一个列表里了。
小说正文,已经顺利获取到了。要想下载整本小说,我们就要获取每个章节的链接。我们先分析下小说目录:
URL:https://www.xsbiquge.com/15\_15338/
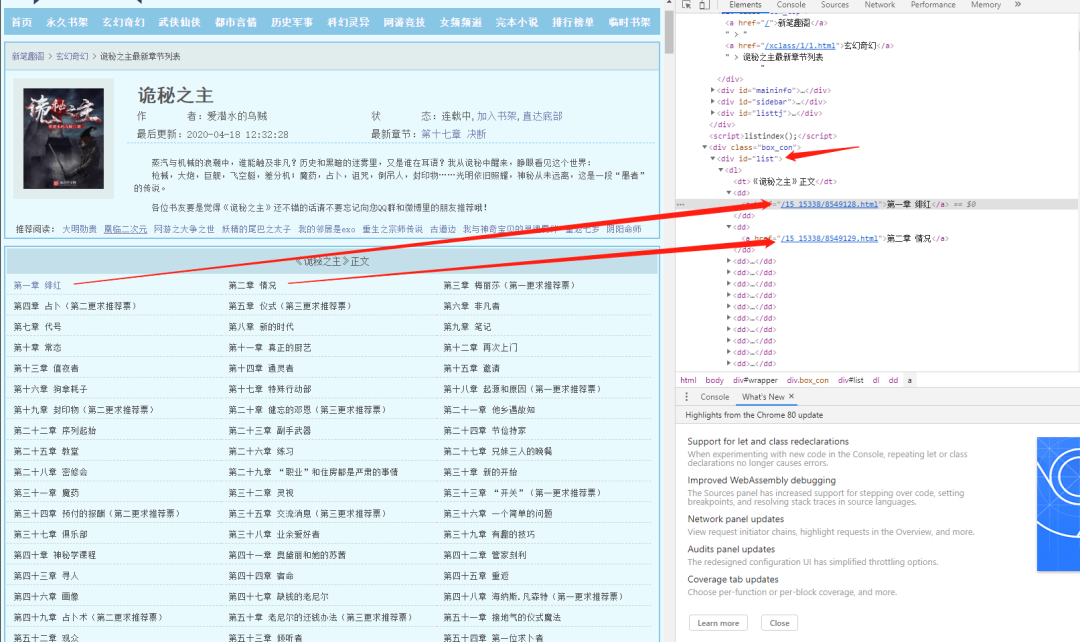
审查元素后,我们不难发现,所有的章节信息,都存放到了 id 属性为 list 的 div 标签下的 a 标签内,编写如下代码:
import requests
bf.find('div', id='list') 就是找到 id 属性为 list 的 div 标签,chapters.find_all('a') 就是在找到的 div 标签里,再提取出所有 a 标签,运行结果如下:
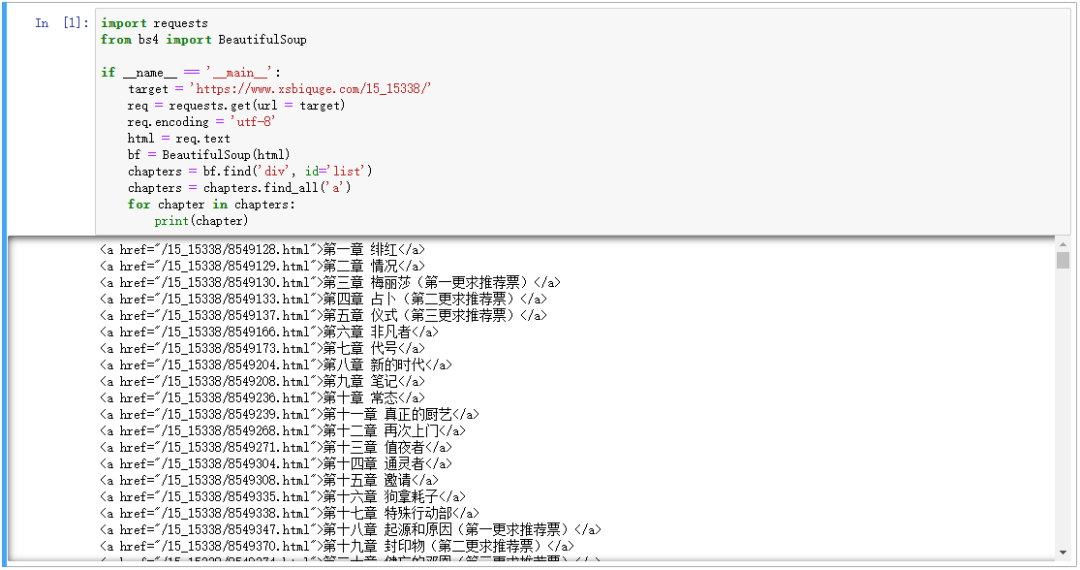
可以看到章节链接和章节名我们已经提取出来,但是还需要进一步解析,编写如下代码:
import requests
可以看到,chapter.get('href') 方法提取了 href 属性,并拼接出章节的 url,使用 chapter.string 方法提取了章节名。
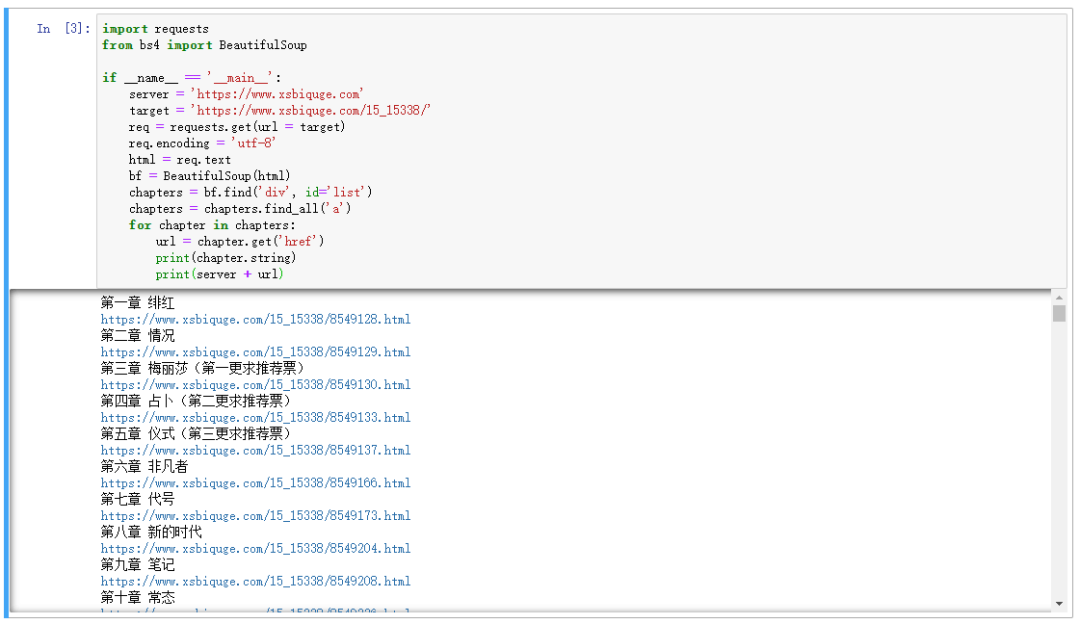
每个章节的链接、章节名、章节内容都有了。接下来就是整合代码,将内容保存到txt中即可。编写代码如下:
import requests
下载过程中,我们使用了 tqdm 显示下载进度,让下载更加“优雅”,如果没有安装 tqdm,可以使用 pip 进行安装,运行效果:
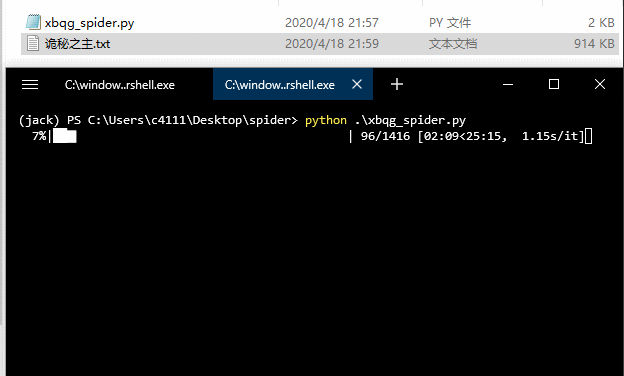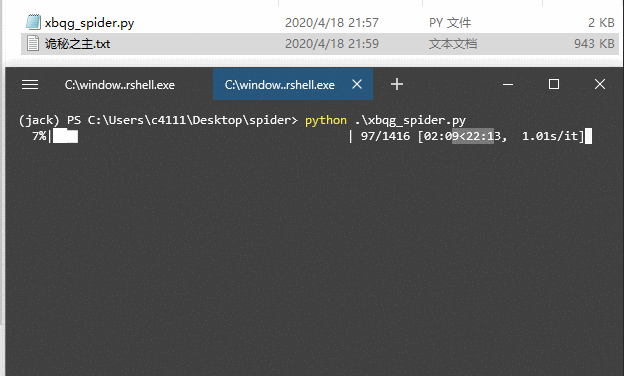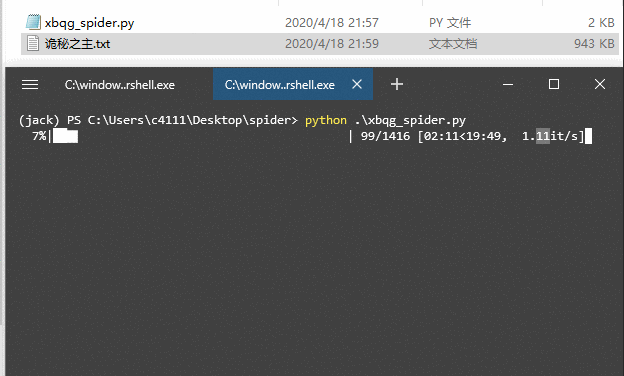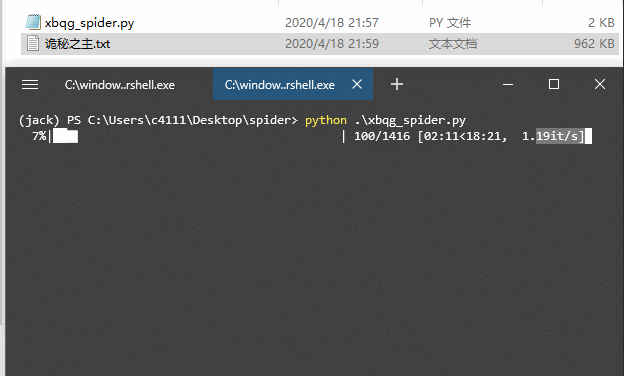
可以看到,小说内容保存到“诡秘之主.txt”中,小说一共 1416 章,下载需要大约 20 分钟,每秒钟大约下载 1 个章节。
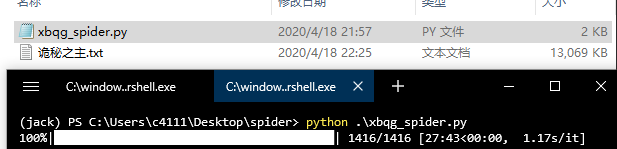
下载完成,实际花费了 27 分钟。
20 多分钟下载一本小说,你可能感觉太慢了。想提速,可以使用多进程,大幅提高下载速度。如果使用分布式,甚至可以1秒钟内下载完毕。
但是,我不建议这样做。
我们要做一个友好的爬虫,如果我们去提速,那么我们访问的服务器也会面临更大的压力。
以我们这次下载小说的代码为例,每秒钟下载 1 个章节,服务器承受的压力大约 1qps,意思就是,一秒钟请求一次。
如果我们 1 秒同时下载 1416 个章节,那么服务器将承受大约 1416 qps 的压力,这还是仅仅你发出的并发请求数,再算上其他的用户的请求,并发量可能更多。
如果服务器资源不足,这个并发量足以一瞬间将服务器“打死”,特别是一些小网站,都很脆弱。
过大并发量的爬虫程序,相当于发起了一次 CC 攻击,并不是所有网站都能承受百万级别并发量的。
所以,写爬虫,一定要谨慎,勿给服务器增加过多的压力,满足我们的获取数据的需求,这就够了。
你好,我也好,大家好才是真的好。
5
总结
本文讲解了网络爬虫的三个步骤:发起请求、解析数据、保存数据。
注意并发量,勿给服务器带来过多的压力。
参考链接(我参考我自己):
**********---**--****-------------- End **********---**--****--------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,****感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~
本文分享自微信公众号 - Python爬虫与数据挖掘(crawler_python)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。









