认识Lucene
下面是百科对Lucene的描述:
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
Lucene突出的优点
Lucene作为一个全文检索引擎,其具有如下突出的优点:
(1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即可使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search[11])、分组查询等等。
面对已经存在的商业全文检索引擎,Lucene也具有相当的优势。
首先,它的开发源代码发行方式(遵守Apache Software License[12]),在此基础上程序员不仅仅可以充分的利用Lucene所提供的强大功能,而且可以深入细致的学习到全文检索引擎制作技术和面向对象编程的实践,进而在此基础上根据应用的实际情况编写出更好的更适合当前应用的全文检索引擎。在这一点上,商业软件的灵活性远远不及Lucene。
其次,Lucene秉承了开放源代码一贯的架构优良的优势,设计了一个合理而极具扩充能力的面向对象架构,程序员可以在Lucene的基础上扩充各种功能,比如扩充中文处理能力,从文本扩充到HTML、PDF[13]等等文本格式的处理,编写这些扩展的功能不仅仅不复杂,而且由于Lucene恰当合理的对系统设备做了程序上的抽象,扩展的功能也能轻易的达到跨平台的能力。
最后,转移到apache软件基金会后,借助于apache软件基金会的网络平台,程序员可以方便的和开发者、其它程序员交流,促成资源的共享,甚至直接获得已经编写完备的扩充功能。最后,虽然Lucene使用Java语言写成,但是开放源代码社区的程序员正在不懈的将之使用各种传统语言实现(例如.net framework[14]),在遵守Lucene索引文件格式的基础上,使得Lucene能够运行在各种各样的平台上,系统管理员可以根据当前的平台适合的语言来合理的选择。
入门前的准备
了解一些关键字的概念:
Documen****t ??
Document 是用来描述文档的,这里的文档可以指一个 HTML 页面,一封电子邮件,或者是一个文本文件。一个 Document 对象由多个 Field 对象组成的。可以把一个 Document 对象想象成数据库中的一个记录,而每个 Field 对象就是记录的一个字段。?
Field ?
Field 对象是用来描述一个文档的某个属性的,比如一封电子邮件的标题和内容可以用两个 Field 对象分别描述。 ?
Analyze****r ??
在一个文档被索引之前,首先需要对文档内容进行分词处理,这部分工作就是由 Analyzer 来做的。Analyzer 类是一个抽象类,它有多个实现。针对不同的语言和应用需要选择适合的 Analyzer。Analyzer 把分词后的内容交给 IndexWriter 来建立索引。 ?
IndexWriter ??
IndexWriter 是 Lucene 用来创建索引的一个核心的类,他的作用是把一个个的 Document 对象加到索引中来。 ?
Directory ??
这个类代表了 Lucene 的索引的存储的位置,这是一个抽象类,它目前有两个实现,第一个是 FSDirectory,它表示一个存储在文件系统中的索引的位置。第二个是 RAMDirectory,它表示一个存储在内存当中的索引的位置。?
Query ?
这是一个抽象类,他有多个实现,比如 TermQuery, BooleanQuery, PrefixQuery. 这个类的目的是把用户输入的查询字符串封装成 Lucene 能够识别的 Query。?
IndexSearcher ??
IndexSearcher 是用来在建立好的索引上进行搜索的。它只能以只读的方式打开一个索引,所以可以有多个 IndexSearcher 的实例在一个索引上进行操作。
Hits ?
Hits 是用来保存搜索结果的。 ?? ?
我的浅显理解
使用Lucene分为几个步骤,都是围绕索引展开的:
1.写索引 IndexWriter
2.读索引 IndexReader
3.查索引 IndexSearcher
4.封装查询条件,想到于写数据库的sql ?QueryParser
5.查询已查到的索引得到结果集 TopDocs ,可以得到Document的一个集合 ?
? ? ? ? ? ? ??
? ? ? ? ? ?
正式入****门,直接上代码???????????????????????????????
写索引:
package com.kl.luceneDemo;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.RAMDirectory;
import java.io.File;
import java.io.FileReader;
import java.nio.file.Paths;
/**
* @author kl by 2016/3/14
* @boke www.kailing.pub
*/
public class Indexer {
public IndexWriter writer;
/**
* 实例化写索引
*/
public Indexer(String indexDir)throws Exception{
Analyzer analyzer=new StandardAnalyzer();//分词器
IndexWriterConfig writerConfig=new IndexWriterConfig(analyzer);//写索引配置
//Directory ramDirectory= new RAMDirectory();//索引写的内存
Directory directory= FSDirectory.open(Paths.get(indexDir));//索引存储磁盘位置
writer=new IndexWriter(directory,writerConfig);//实例化一个写索引
}
/**
* 关闭写索引
* @throws Exception
*/
public void close()throws Exception{
writer.close();
}
/**
* 添加指定目录的所有文件的索引
* @param dataDir
* @return
* @throws Exception
*/
public int index(String dataDir)throws Exception{
File[] files=new File(dataDir).listFiles();//得到指定目录的文档数组
for(File file:files){
indexFile(file);
}
return writer.numDocs();
}
public void indexFile(File file)throws Exception{
System.out.println("索引文件:"+file.getCanonicalPath());//打印索引到的文件路径信息
Document document=getDocument(file);//得到一个文档信息,相对一个表记录
writer.addDocument(document);//写入到索引,相当于插入一个表记录
}
/**
* 返回一个文档记录
* @param file
* @return
* @throws Exception
*/
public Document getDocument(File file)throws Exception{
Document document=new Document();//实例化一个文档
document.add(new TextField("context",new FileReader(file)));//添加一个文档信息,相当于一个数据库表字段
document.add(new TextField("fileName",file.getName(), Field.Store.YES));//添加文档的名字属性
document.add(new TextField("filePath",file.getCanonicalPath(),Field.Store.YES));//添加文档的路径属性
return document;
}
public static void main(String []ages){
String indexDir="E:\\LuceneIndex";
String dataDir="E:\\LuceneTestData";
Indexer indexer=null;
int indexSum=0;
try {
indexer=new Indexer(indexDir);
indexSum= indexer.index(dataDir);
System.out.printf("完成"+indexSum+"个文件的索引");
}catch (Exception e){
e.printStackTrace();
}finally {
try {
indexer.close();
}catch (Exception e){
e.printStackTrace();
}
}
}
}
读查索引
package com.kl.luceneDemo;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import java.nio.file.Paths;
/**
* @author kl by 2016/3/14
* @boke www.kailing.pub
*/
public class Searcher {
public static void search(String indexDir,String q)throws Exception{
Directory dir= FSDirectory.open(Paths.get(indexDir));//索引地址
IndexReader reader= DirectoryReader.open(dir);//读索引
IndexSearcher is=new IndexSearcher(reader);
Analyzer analyzer=new StandardAnalyzer(); // 标准分词器
QueryParser parser=new QueryParser("context", analyzer);//指定查询Document的某个属性
Query query=parser.parse(q);//指定查询索引内容,对应某个分词
TopDocs hits=is.search(query, 10);//执行搜索
System.out.println("匹配 "+q+"查询到"+hits.totalHits+"个记录");
for(ScoreDoc scoreDoc:hits.scoreDocs){
Document doc=is.doc(scoreDoc.doc);
System.out.println(doc.get("fileName"));//打印Document的fileName属性
}
reader.close();
}
public static void main(String[] args) {
String indexDir="E:\\LuceneIndex";
String q="Muir";
try {
search(indexDir,q);
} catch (Exception e) {
e.printStackTrace();
}
}
}
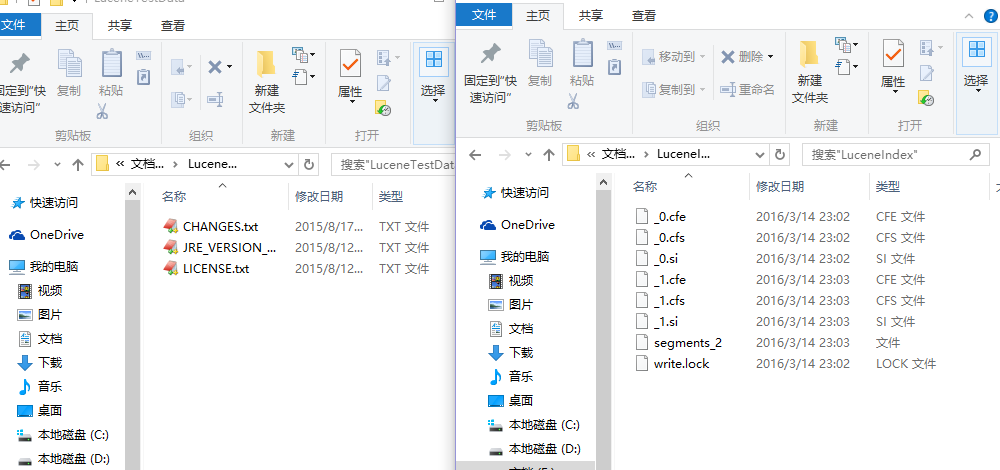
以下图片是我的文件目录和Lucene生成的索引文件
 ?????????????????
?????????????????
**ps:博主这里使用的是目前最新的Lucene版本5.5.0 ,各个版本 实例化相关对象的方式可能话不一样,具体可参考官方说明
**
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?? ? ?
本文同步分享在 博客“kailing”(other)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。