
scrapy -->CrawlSpider 介绍
1、首先,通过crawl 模板新建爬虫:
scrapy genspider -t crawl lagou www.lagou.com
创建出来的爬虫文件lagou.py:


# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class LagouSpider(CrawlSpider):
name = 'lagou'
allowed_domains = ['www.lagou.com']
start_urls = ['http://www.lagou.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
lagou.py
2、CrawlSpider 概述及源码分析
1)CrawlSpider概述
CrawlSpider使用于取全站的话。CrawlSpider基于Spider,但是可以说是为全站爬取而生。CrawlSpiders是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类定义了一些规则(rule)来提供跟进link的方便的机制,从爬取的网页中获取link并继续爬取的工作更适合。
2)CrawlSpider的源码分析 → 方法介绍
①、当我们启动爬虫时,爬取url是从Spider(CrawlSpider继承于Spider)下的 start_requests 函数开始执行的,该方法中会逐个获取lagou.py中 start_urls列表中的url进行request爬取数据并yield出去
# Spider类
def start_requests(self):
cls = self.__class__
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead (see %s.%s)." % (
cls.__module__, cls.__name__
),
)
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
for url in self.start_urls:
yield Request(url, dont_filter=True)
②、上述每个url爬取完成时会自动调用回调函数:parse函数
parse函数作用:本来由parse函数处理start_urls中的url返回的数据,在CrawlSpider中的parse函数中,是将start_urls中的每个url的返回值response交由_parse_response函数进行处理, 同时设定 parse_start_url 为回调函数(parse_start_url在源码中只返回了空列表,也就是说如果我们要对start_urls中每个url的返回值做处理,重载parse_start_url函数并进行自己代码的编写就可以了。如上述中start_urls中只有一个url:www.lagou.com )↓
③、_parse_response函数作用:
1)如果回调函数是parse_start_url,执行该函数,yield request ; 如果回调函数是rules.callback,执行该函数并yield item转pipelines进行数据处理
2)到rules(规则)中查找follow是否为 True,True表示需要跟进,接着调用_requests_to_follow函数↓
需要注意的是:parse函数是CrawlSpider源码中已经定义好的函数,我们尽量不能重载这函数,避免出错。可以重载的是parse_start_url、process_results 这两个函数
④、_requests_to_follow函数作用:
1)根据用户自定义的rules规则,提取rules中的link链接,将其添加进set集合(避免重复)
2)调用_build_request函数,封装下一层url并进行数据爬取(首页url →下一层url) ,每个url数据爬取完毕后都调用回调函数:_response_downloaded↓
3)调用process_request,即_compile_rules函数下的:rule.process_request = get_method(rule.process_request) ,目的是将rule中的字符串表示的方法映射成真正的方法
⑤、_response_downloaded函数实际调用的是第③步的_parse_response函数:第二层(首层url是首页)每个url爬取完成后回调函数真正执行的地方,如果有第三层url(符号规则),则会继续深度式往第三层、第四层进行数据爬取。
#调用顺序:
# start_request → 1、 parse → 2、 _parse_response → 3、 parse_start_url → 4、process_results → 5&6、 同时,_parse_response调用_follow_lineks
# → 7、_build_request → 8、_response_downloaded → 返回执行2、_parse_response ,如此循环# 目的:通过start_request对拉勾网首页页面进行爬取,提取首页页面的所有url,并进行规则匹配。匹配成功则进入该url页面提取我们需要的目标数据
class CrawlSpider(Spider):
rules = ()
def __init__(self, *a, **kw):
super(CrawlSpider, self).__init__(*a, **kw)
self._compile_rules()
# 1、Spider中的start_request调用parse回调函数,parse函数直接调用parse_response函数
def parse(self, response):
return self._parse_response(response, self.parse_start_url, cb_kwargs={}, follow=True)
# 3、parse的回调函数
def parse_start_url(self, response):
return []
# 4、直接返回response对象
def process_results(self, response, results):
return results
# 7、封装url并进行数据爬取,爬取完成后调用回调函数:_response_downloaded
def _build_request(self, rule, link):
r = Request(url=link.url, callback=self._response_downloaded)
r.meta.update(rule=rule, link_text=link.text)
return r
# 6、根据用户自定义的rules规则,提取符合rules规则的每个第二层url,存进links列表,同时将每个url都添加进set集合(避免重复)
def _requests_to_follow(self, response):
if not isinstance(response, HtmlResponse):
return
seen = set()
# 抽取rules中LinkExtractor -->allow的规则内容,n为index值,rule为allow中的正则匹配内容,如上面lagou.py中:LinkExtractor(allow=r'Items/')里面的r'Items/'
for n, rule in enumerate(self._rules):
# 在当前页面,将所有符合规则的url(且不在seen中)都添加进links列表,用于跟进时,取出每个url进行数据爬取。如果在seen中则不添加不爬取,起到去重的作用
links = [lnk for lnk in rule.link_extractor.extract_links(response)
if lnk not in seen]
if links and rule.process_links:
# 使用用户自定义的process_links处理url,默认不处理
links = rule.process_links(links)
for link in links:
seen.add(link) # 添加到set集合,去重
# 调用_build_request函数,将
r = self._build_request(n, link)
# 对每个Request调用process_request()函数。该函数默认为indentify即不做处理。
yield rule.process_request(r)
# 8、执行_build_request 数据爬取完成后的回调函数,实际上是调用第2步中的_parse_response函数,来执行回调函数,然后又返到第3步进行处理,如此循环。
def _response_downloaded(self, response):
# 找到当前对应的rules规则
rule = self._rules[response.meta['rule']]
# rule.callback:当前rules规则的callback函数,让_parse_response执行
return self._parse_response(response, rule.callback, rule.cb_kwargs, rule.follow)
# 2、parse、rule下的回调函数的实际执行函数,及是否跟进的判断
def _parse_response(self, response, callback, cb_kwargs, follow=True):
if callback:
# 回调函数有两种:
# 1)parse函数的回调函数(parse_start_url()),用parse_start_url()处理response对象,返回Request对象
# 2)如果是rules规则中调用的callback函数,则返回的是Item对象
cb_res = callback(response, **cb_kwargs) or ()
cb_res = self.process_results(response, cb_res)
for requests_or_item in iterate_spider_output(cb_res):
yield requests_or_item # yield request:执行的是parse的回调函数。 or yield item:表示该url数据爬取完毕,转到pipelines进行数据处理
# 5、每个url爬取后,可能会爬取出一些url,通过下面判断是否跟进对这些url进行下一层数据爬取
if follow and self._follow_links:
# 需要跟进下一层url的爬取,调用_follow_lineks函数进行处理
for request_or_item in self._requests_to_follow(response):
yield request_or_item
def _compile_rules(self):
# 将rule中的字符串表示的方法映射成真正的方法
def get_method(method):
if callable(method):
return method
elif isinstance(method, six.string_types):
return getattr(self, method, None)
self._rules = [copy.copy(r) for r in self.rules]
for rule in self._rules:
rule.callback = get_method(rule.callback)
rule.process_links = get_method(rule.process_links)
rule.process_request = get_method(rule.process_request)
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = super(CrawlSpider, cls).from_crawler(crawler, *args, **kwargs)
spider._follow_links = crawler.settings.getbool(
'CRAWLSPIDER_FOLLOW_LINKS', True)
return spider
def set_crawler(self, crawler):
super(CrawlSpider, self).set_crawler(crawler)
self._follow_links = crawler.settings.getbool('CRAWLSPIDER_FOLLOW_LINKS', True)
图解析:
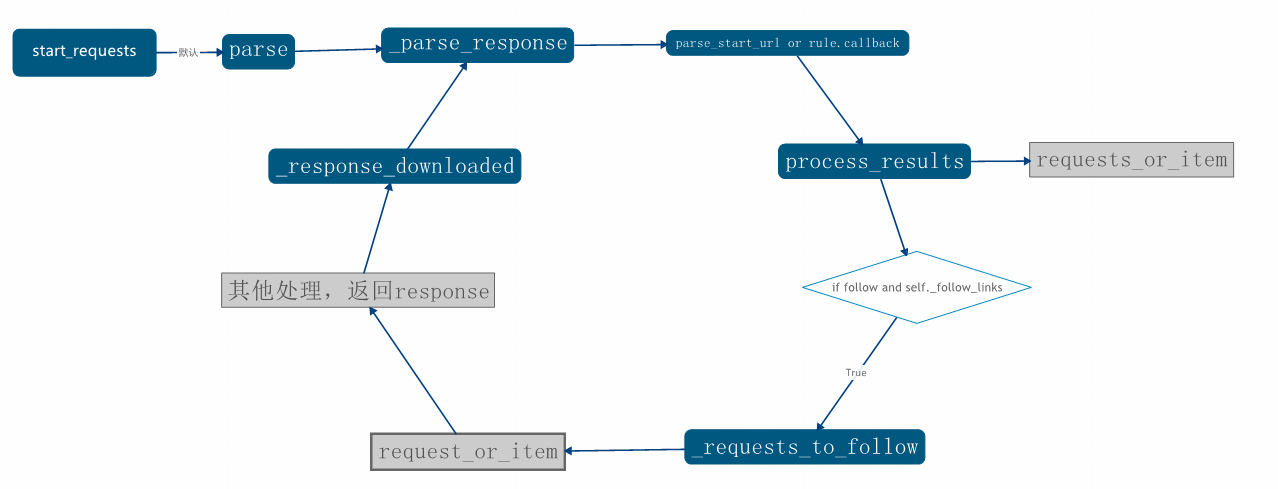
以上是对CrawlSpider源码的分析,已经尽量细化讲解,如果有错误的地方,欢迎指正。
接下来简单介绍下Rules类:
class Rule(object):
def __init__(self, link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=identity):
self.link_extractor = link_extractor
self.callback = callback
self.cb_kwargs = cb_kwargs or {}
self.process_links = process_links
self.process_request = process_request
if follow is None:
self.follow = False if callback else True
else:
self.follow = follow
参数介绍:
- link_extractor:是一个Link Extractor对象。其定义了如何从爬取到的页面提取链接的规则。
- callback:是一个callable或string(该Spider中同名的函数将会被调用)。从link_extractor中每获取到链接时将会调用该函数。该回调函数接收一个response作为其第一个参数,并返回一个包含Item以及Request对象(或者这两者的子类)的列表。
- cb_kwargs:包含传递给回调函数的参数(keyword argument)的字典类型。
- follow:是一个boolean值,指定了根据该规则从response提取的链接是否需要跟进。如果callback为None,follow默认设置True,否则默认False,当follow为True时表示跟进。另外:CRAWLSPIDER_FOLLOW_LINKS默认为True(setting中可配置为False),只有这两个都为True时爬虫才会深度跟进url进行下一层数据爬取
- process_links:是一个callable或string(该Spider中同名的函数将会被调用)。从link_extrator中获取到链接列表时将会调用该函数。该方法主要是用来过滤。
- process_request:是一个callable或string(该spider中同名的函数都将会被调用)。该规则提取到的每个request时都会调用该函数。该函数必须返回一个request或者None。用来过滤request。
LinkExtractor对象 →LxmlLinkExtractor类
class LxmlLinkExtractor(FilteringLinkExtractor):
def __init__(self, allow=(), deny=(), allow_domains=(), deny_domains=(), restrict_xpaths=(),
tags=('a', 'area'), attrs=('href',), canonicalize=False,
unique=True, process_value=None, deny_extensions=None, restrict_css=(),
strip=True):
tags, attrs = set(arg_to_iter(tags)), set(arg_to_iter(attrs))
tag_func = lambda x: x in tags
attr_func = lambda x: x in attrs
lx = LxmlParserLinkExtractor(
tag=tag_func,
attr=attr_func,
unique=unique,
process=process_value,
strip=strip,
canonicalized=canonicalize
)
......
LinkExtractor是从网页(scrapy.http.Response)中抽取会被follow的链接的对象。
LinkExtractor在CrawlSpider类(在Scrapy可用)中使用, 通过一套规则,但你也可以用它在你的Spider中,即使你不是从CrawlSpider继承的子类, 因为它的目的很简单: 提取链接。每个LinkExtractor有唯一的公共方法是 extract_links(),它接收一个 Response 对象,并返回一个 scrapy.link.Link 对象。Link Extractors要实例化一次,并且 extract_links 方法会根据不同的 response 调用多次提取链接。
主要参数:
- allow:满足括号中”正则表达式”的值会被提取,如果为空,则全部匹配。
- deny:与这个正则表达式(或正则表达式列表)不匹配的url一定不提取
- allow_domains:会被提取的连接的domains
- deny_domains:一定不会被提取链接的domains。
- deny_extensions: 需要忽略的url扩展名列表,如"bmp", "gif", "jpg", "mp3", "wav", "mp4", "wmv"。默认使用在模块scrapy.linkextractors中定义的IGNORED_EXTENSIONS。
- restrict_xpaths:指定提取URL的xpath(或xpath列表)。若不为空,则只使用该参数去提取URL。和allow共同作用过滤链接。
- restrict_css:指定提取URL的css列表。若不为空,则只使用该参数去提取URL
- tags:指定提取URL的页面tag列表。默认为('a','area')
- attrs:从tags参数中指定的tag上提取attrs。默认为('href')
- canonicalize:是否标准化每个URL,使用scrapy.utils.url.canonicalize_url。默认为True。
- unique:是否过滤提取过的URL
- process_value:处理tags和attrs提取到的URL











