
主题
(使用 pika 0.9.8 Python客户端)
在前一篇教程中,我们改进了我们的logging系统。我们使用了一个direct exchange来替换只能简单地广播消息的fanout exchange,并获得了选择性地接收消息的能力。
尽管使用direct exchange改进了我们的系统,但它仍然有限制- 它不能基于多个条件来路由。
在我们的logging系统中,我们可能不仅仅想要基于severity来订阅logs,而也想要基于log产生源来订阅。你也许已经知道这个概念来自于syslog unix工具,它同时基于severiry (info/warn/crit...)和设备 (auth/cron/kern...)来路由logs。
那将给我们非常大的灵活性 - 我们可能想要只监听来自于'cron'和'kern'的所有critical errors的logs。
要在我们的logging系统中实现那一点,我们需要学习一下更复杂的topic exchange的东西。
Topic exchange
被发送给topic exchange的消息可以没有任意的routing_key - 它必须是一个单词的列表,由点号分割。单词可以是任何东西,但通常它们描述了与消息相关的一些特征。一些有效的routing key的例子如:**"stock.usd.nyse","nyse.vmw","quick.orange.rabbit"**routin key中可以有任意多个单词,但上限是255字节。
binding key必须采用相同的形式。topic exchange背后的逻辑与direct的相似 - 一条带有特定的routing key的消息,将被发送给所有绑定时所用的binding key与之完全匹配的所有的队列。然而binding key有两种重要的特殊情况。
- * (星号)可以精确地替代一个单词。
- # (井号)可以替代0个或多个单词。
用一个例子来解释最简单:
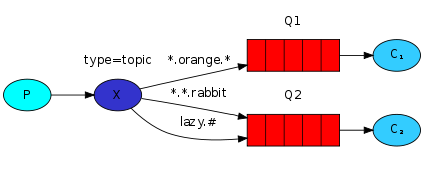
在这个例子中,我们将发送的所有消息都是描述动物的。这些消息在发送时都会带一个由三个单词(两个点号)组成的routing key。routing key中的第一个单词将描述一个celerity,第二个是一个颜色,而第三个是一个物种:"
我们将创建三个绑定:Q1以binding key "*.orange.*"来绑定,Q2以"*.*.rabbit"和"lazy.#"。
这些绑定可被总结为:
- Q1对所有颜色为orange的动物感兴趣。
- Q2想要听到所有关于rabbits及lazy的动物的东西。
一个routing key被设置为**"quick.orange.rabbit"的消息将被发送到这两个队列。消息"lazy.orange.elephant"也将进入这两个队列。而另一方面,"quick.orange.fox"将只进入地一个队列,"lazy.brown.fox"将只进入第二个。而"lazy.pink.rabbit"将只被发送到第二个队列一次,尽管它匹配了两个绑定。"quick.brown.fox"**不匹配任何绑定,故而它将被丢弃。
但如果我们破坏了规矩,发送了带有一个或四个单词的消息,将会发生什么呢,比如"orange"或"quick.orange.male.rabbit"?那么,这些消息不匹配任何绑定,而会丢失。
另一个方面,"lazy.orange.male.rabbit",尽管它有四个单词,但它将匹配最后一个绑定,并将被发送给第二个队列。
Topic exchange
Topic exchange非常强大,并可以有像其它exchanges那样的行为。
但一个队列以"#" (井号)为binding key来绑定时 - 它将接收所有的消息,而不管routing key是什么 - 像一个fanout exchange。
当没有在绑定中使用特殊字符 "*" (星号) and "#" (井号)时,topic exchange的行为将像一个direct一样。
完整代码
我们将在我们的logging系统中使用一个topic exchange。我们首先有一个假设,即logs的routing keys将有两个单词:"
这份代码几乎与前一篇教程的一样。
emit_log_topic.py的代码:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print " [x] Sent %r:%r" % (routing_key, message)
connection.close()
receive_logs_topic.py 的代码:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
print >> sys.stderr, "Usage: %s [binding_key]..." % (sys.argv[0],)
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
print ' [*] Waiting for logs. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] %r:%r" % (method.routing_key, body,)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
要接收所有的消息执行:
python receive_logs_topic.py "#"
要接收所有来自于facility "kern"的消息则:
python receive_logs_topic.py "kern.*"
或者如果你只想监听"critical" logs:
python receive_logs_topic.py "*.critical"
你可以创建多个绑定:
python receive_logs_topic.py "kern.*" "*.critical"
要发送一条routing key "kern.critical"类型的log则:
python emit_log_topic.py "kern.critical" "A critical kernel error"
尽情地享受这些程序带来的乐趣吧。注意,那些代码本身不对routing或binding key做任何假设,你可能想要用多于两个的routing key参数来玩一下。
一些难题:
- "*"绑定会捕获以一个空routing key发送的消息吗?
- "#."会捕获以一个字符串".."作为key的消息吗?它会捕获以一个单独的单词为key的消息吗?
- "a.*.#"与"a.#"有何不同?
(emit_logs_topic.py和receive_logs_topic.py的完整的代码)
进入tutorial 6来学习RPC吧。
Done
原文地址。












