

对于搜索引擎,大家不会感到陌生,我们每天都在用。
我们在百度、谷歌上搜索我们想要的信息。比如,在输入框里输入关键字查询后,会返回很多和关键字相关的内容。
或者在电商网站输入想要购买的商品名称后,就立即能查到我们想要购买的商品信息。
但是大家有没有思考过,为什么网站能快速检索到我们想要看到的信息?这里其实用到了倒排索引技术。
简单的介绍一下倒排索引
举个例子,我们小时候背诵过的古诗,当我们看到一首诗的题目时,可以很快速的背诵诗的内容。但是如果我们看到一句诗时,却很难快速说出诗的题目。
或者我们看到诗的上半句,一般会很轻松的背诵出诗的下半句。但是根据诗的下半句,很难快速想到诗的上半句。
这是因为,我们大脑存储的诗词,是通过正排索引的方式组织起来的,类似于关系型数据库一样,通过id很快能查到详细内容。但是要通过内容反查id,就不是那么容易了。
再比如,我们的电脑里有很多文件,我们能搜索到一个文件里有什么词,但是我们统计某个词在哪些文件里出现过,以及出现的次数,就不是那么容易了。
下面内容,用Flink实时构建倒排索引,实现一个全文检索的功能。
需求:有大量文本文件,需要构建索引。输入某个关键字,输出关键字在哪些文件里出现过,以及在文件里出现的次数。
思路:批量读取磁盘上的文件内容,将文件内容发送给kafka,Flink从kafka消费数据,将数据内容分词,记录每次词出现的词频和所在的文件名,然后通过Flink sql实时统计每个单词所在的文件,和在每个文件中出现的次数,写入到下游存储。
关键代码如下:
1、收集文件内容并发送给kafka
这是个很简单的程序,通过递归读取目录下的全部文件,将文件信息发送给kafka。
public static void main(String[] args) throws Exception {
2、Flink消费kafka的数据,并对原始数据做ETL转化。
flatMap算子中的操作是,将上报的数据特殊中的特殊字符过滤并封装成Word类发送给下游。
方便起见,这里采用关键字+文件名的hashCode作为一行数据的唯一id,后续根据这个id实时更新倒排索引。
public static void main(String[] args) throws Exception {
public class Word {
3、最关键的一步,构建倒排索引,将收集的数据封装成Word发送到下游算子后,下游算子通过Flink sql实时统计每个单词出现的次数以及所在的文件,并将数据实时更新到MySQL中,代码如下:
private static void buildIndexAndSink(StreamTableEnvironment tabEnv) {
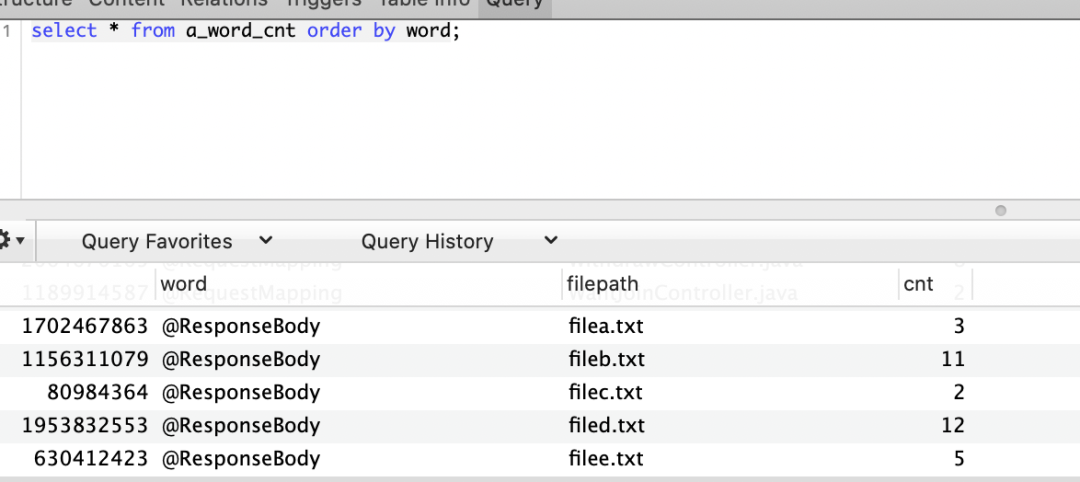
通过上面代码,我们可以将目录下的所有文件,构建倒排索引。然后将索引信息写入MySQL,查到的效果如下,可以看到,某个词在哪些文件里出现过,以及出现的次数。
拓展:
我们是不是可以做个简易的搜索引擎呢?原理与上面的案例类似,需要把文件名替换成url。
本文分享自微信公众号 - OutOfMemoryError(backend_technology)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











