起步 - 关于版本控制 --介绍理论
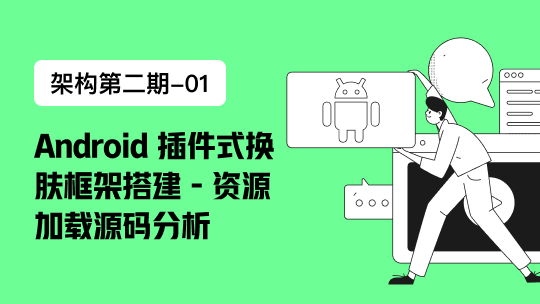
集中化的版本控制系统
SVN CVS
事分两面,有好有坏。这么做最显而易见的缺点是中央服务器的单点故障。如果宕机一小时,那么在这一小时内,谁都无法提交更新,也就无法协同工作。要是中央服务器的磁盘发生故障,碰巧没做备份,或者备份不够及时,就会有丢失数据的风险。最坏的情况是彻底丢失整个项目的所有历史更改记录,而被客户端偶然提取出来的保存在本地的某些快照数据就成了恢复数据的希望。但这样的话依然是个问题,你不能保证所有的数据都已经有人事先完整提取出来过。本地版本控制系统也存在类似问题,只要整个项目的历史记录被保存在单一位置,就有丢失所有历史更新记录的风险。

分布式版本控制系统
1、 客户端并不只提取最新版本的文件快照,而是把代码仓库完整地镜像下来。这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。因为每一次的提取操作,实际上都是一次对代码仓库的完整备份
Git 基础
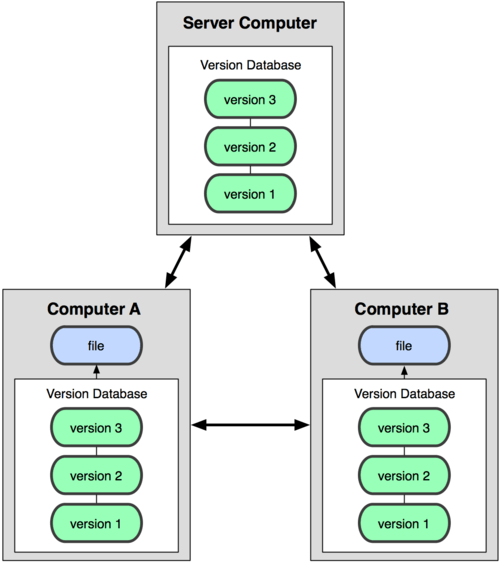
直接记录快照,而非差异比较
Git 和其他版本控制系统的主要差别在于,Git 只关心文件数据的整体是否发生变化,而大多数其他系统则只关心文件内容的具体差异。
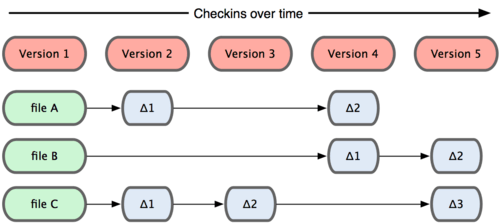
其他系统在每个版本中记录着各个文件的具体差异
Git 并不保存这些前后变化的差异数据。实际上,Git 更像是把变化的文件作快照后,记录在一个微型的文件系统中。每次提交更新时,它会纵览一遍所有文件的指纹信息并对文件作一快照,然后保存一个指向这次快照的索引。为提高性能,若文件没有变化,Git 不会再次保存,而只对上次保存的快照作一链接。Git 的工作方式

近乎所有操作都是本地执行
时刻保持数据完整性
多数操作仅添加数据
文件的三种状态
在 Git 内都只有三种状态:已提交(committed),已修改(modified)和已暂存(staged)。已提交表示该文件已经被安全地保存在本地数据库中了;已修改表示修改了某个文件,但还没有提交保存;已暂存表示把已修改的文件放在下次提交时要保存的清单中。

基本的 Git 工作流程如下:
在工作目录中修改某些文件。
对修改后的文件进行快照,然后保存到暂存区域。
提交更新,将保存在暂存区域的文件快照永久转储到 Git 目录中。
安装 Git 点击
Chapter 2 Git 基础
取得项目的 Git 仓库
有两种取得 Git 项目仓库的方法。第一种是在现存的目录下,通过导入所有文件来创建新的 Git 仓库。第二种是从已有的 Git 仓库克隆出一个新的镜像仓库来。
在工作目录中初始化新仓库
要对现有的某个项目开始用 Git 管理,只需到此项目所在的目录,执行
$ git init
初始化后,在当前目录下会出现一个名为 .git 的目录,所有 Git 需要的数据和资源都存放在这个目录中
如果当前目录下有几个文件想要纳入版本控制,需要先用 git add 命令告诉 Git 开始对这些文件进行跟踪,然后提交:
$ git add *.c
$ git add README
$ git commit -m 'initial project version'
从现有仓库克隆
Git 收取的是项目历史的所有数据(每一个文件的每一个版本),服务器上有的数据克隆之后本地也都有了。实际上,即便服务器的磁盘发生故障,用任何一个克隆出来的客户端都可以重建服务器上的仓库,回到当初克隆时的状态
克隆仓库的命令格式为 git clone [url]
$ git clone git://github.com/schacon/grit.git
如果希望在克隆的时候,自己定义要新建的项目目录名称,可以在上面的命令末尾指定新的名字:
$ git clone git://github.com/schacon/grit.git mygrit
2.2 Git 基础 - 记录每次更新到仓库
记录每次更新到仓库
请记住,工作目录下面的所有文件都不外乎这两种状态:已跟踪或未跟踪。已跟踪的文件是指本来就被纳入版本控制管理的文件,在上次快照中有它们的记录,工作一段时间后,它们的状态可能是未更新,已修改或者已放入暂存区。而所有其他文件都属于未跟踪文件。它们既没有上次更新时的快照,也不在当前的暂存区域。初次克隆某个仓库时,工作目录中的所有文件都属于已跟踪文件,且状态为未修改。
在编辑过某些文件之后,Git 将这些文件标为已修改。我们逐步把这些修改过的文件放到暂存区域,直到最后一次性提交所有这些暂存起来的文件,如此重复。

文件的状态变化周期
检查当前文件状态
$ git status On branch master nothing to commit, working directory clean
这说明你现在的工作目录相当干净。换句话说,所有已跟踪文件在上次提交后都未被更改过。
跟踪新文件
使用命令 git add 开始跟踪一个新文件。
$ git status On branch master Changes to be committed: (use "git reset HEAD
只要在 “Changes to be committed” 这行下面的,就说明是已暂存状态。如果此时提交,那么该文件此时此刻的版本将被留存在历史记录中
其实 git add 的潜台词就是把目标文件快照放入暂存区域,也就是 add file into staged area,同时未曾跟踪过的文件标记为需要跟踪。这样就好理解后续 add 操作的实际意义了。
暂存已修改文件
忽略某些文件
一般我们总会有些文件无需纳入 Git 的管理,也不希望它们总出现在未跟踪文件列表。通常都是些自动生成的文件,比如日志文件,或者编译过程中创建的临时文件等。我们可以创建一个名为 .gitignore 的文件,列出要忽略的文件模式。来看一个实际的例子:
$ cat .gitignore
*.[oa]
*~
第一行告诉 Git 忽略所有以 .o 或 .a 结尾的文件。一般这类对象文件和存档文件都是编译过程中出现的,我们用不着跟踪它们的版本。第二行告诉 Git 忽略所有以波浪符(~)结尾的文件,许多文本编辑软件(比如 Emacs)都用这样的文件名保存副本。此外,你可能还需要忽略 log,tmp 或者 pid 目录,以及自动生成的文档等等。要养成一开始就设置好 .gitignore 文件的习惯,以免将来误提交这类无用的文件。
文件 .gitignore 的格式规范如下:
所有空行或者以注释符号
#开头的行都会被 Git 忽略。可以使用标准的 glob 模式匹配。
匹配模式最后跟反斜杠(
/)说明要忽略的是目录。要忽略指定模式以外的文件或目录,可以在模式前加上惊叹号(
!)取反。
所谓的 glob 模式是指 shell 所使用的简化了的正则表达式。星号(*)匹配零个或多个任意字符;[abc]匹配任何一个列在方括号中的字符(这个例子要么匹配一个 a,要么匹配一个 b,要么匹配一个 c);问号(?)只匹配一个任意字符;如果在方括号中使用短划线分隔两个字符,表示所有在这两个字符范围内的都可以匹配(比如 [0-9] 表示匹配所有 0 到 9 的数字)。
我们再看一个 .gitignore 文件的例子:
# 此为注释 – 将被 Git 忽略
# 忽略所有 .a 结尾的文件
*.a
# 但 lib.a 除外
!lib.a
# 仅仅忽略项目根目录下的 TODO 文件,不包括 subdir/TODO
/TODO
# 忽略 build/ 目录下的所有文件
build/
# 会忽略 doc/notes.txt 但不包括 doc/server/arch.txt
doc/*.txt
# ignore all .txt files in the doc/ directory
doc/**/*.txt
查看已暂存和未暂存的更新
要查看尚未暂存的文件更新了哪些部分,不加参数直接输入 git diff:
提交更新
$ git commit
另外也可以用 -m 参数后跟提交说明的方式,在一行命令中提交更新:
$ git commit -m "Story 182: Fix benchmarks for speed"
跳过使用暂存区域
尽管使用暂存区域的方式可以精心准备要提交的细节,但有时候这么做略显繁琐。Git 提供了一个跳过使用暂存区域的方式,只要在提交的时候,给 git commit 加上 -a 选项,Git 就会自动把所有已经跟踪过的文件暂存起来一并提交,从而跳过 git add 步骤:
$ git status On branch master Changes not staged for commit: (use "git add
看到了吗?提交之前不再需要 git add 文件 benchmarks.rb 了。
移除文件
要从 Git 中移除某个文件,就必须要从已跟踪文件清单中移除(确切地说,是从暂存区域移除),然后提交。可以用 git rm 命令完成此项工作,并连带从工作目录中删除指定的文件,这样以后就不会出现在未跟踪文件清单中了。
如果只是简单地从工作目录中手工删除文件,运行 git status 时就会在 “Changes not staged for commit” 部分(也就是_未暂存_清单)看到:
$ rm grit.gemspec
$ git status
On branch master
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
deleted: grit.gemspec
no changes added to commit (use "git add" and/or "git commit -a")
然后再运行 git rm 记录此次移除文件的操作:
$ git rm grit.gemspec
rm 'grit.gemspec'
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
deleted: grit.gemspec
最后提交的时候,该文件就不再纳入版本管理了。如果删除之前修改过并且已经放到暂存区域的话,则必须要用强制删除选项 -f(译注:即 force 的首字母),以防误删除文件后丢失修改的内容。
另外一种情况是,我们想把文件从 Git 仓库中删除(亦即从暂存区域移除),但仍然希望保留在当前工作目录中。换句话说,仅是从跟踪清单中删除。比如一些大型日志文件或者一堆 .a 编译文件,不小心纳入仓库后,要移除跟踪但不删除文件,以便稍后在 .gitignore 文件中补上,用 --cached 选项即可:
$ git rm --cached readme.txt
后面可以列出文件或者目录的名字,也可以使用 glob 模式。比方说:
$ git rm log/\*.log
注意到星号 * 之前的反斜杠 \,因为 Git 有它自己的文件模式扩展匹配方式,所以我们不用 shell 来帮忙展开(译注:实际上不加反斜杠也可以运行,只不过按照 shell 扩展的话,仅仅删除指定目录下的文件而不会递归匹配。上面的例子本来就指定了目录,所以效果等同,但下面的例子就会用递归方式匹配,所以必须加反斜杠。)。此命令删除所有 log/ 目录下扩展名为 .log 的文件。类似的比如:
$ git rm \*~
会递归删除当前目录及其子目录中所有 ~ 结尾的文件。
移动文件
不像其他的 VCS 系统,Git 并不跟踪文件移动操作。如果在 Git 中重命名了某个文件,仓库中存储的元数据并不会体现出这是一次改名操作。不过 Git 非常聪明,它会推断出究竟发生了什么,至于具体是如何做到的,我们稍后再谈。
既然如此,当你看到 Git 的 mv 命令时一定会困惑不已。要在 Git 中对文件改名,可以这么做:
$ git mv file_from file_to
它会恰如预期般正常工作。实际上,即便此时查看状态信息,也会明白无误地看到关于重命名操作的说明:
$ git mv README.txt README
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
renamed: README.txt -> README
其实,运行 git mv 就相当于运行了下面三条命令:
$ mv README.txt README
$ git rm README.txt
$ git add README
如此分开操作,Git 也会意识到这是一次改名,所以不管何种方式都一样。当然,直接用 git mv 轻便得多,不过有时候用其他工具批处理改名的话,要记得在提交前删除老的文件名,再添加新的文件名。
2.3 Git 基础 - 查看提交历史
查看提交历史
git log 有许多选项可以帮助你搜寻感兴趣的提交,接下来我们介绍些最常用的。
我们常用 -p 选项展开显示每次提交的内容差异,用 -2 则仅显示最近的两次更新:
git log -p -2
但最有意思的是 format,可以定制要显示的记录格式,这样的输出便于后期编程提取分析,像这样:
$ git log --pretty=format:"%h - %an, %ar : %s" ca82a6d - Scott Chacon, 11 months ago : changed the version number 085bb3b - Scott Chacon, 11 months ago : removed unnecessary test code a11bef0 - Scott Chacon, 11 months ago : first commit
表 2-1 列出了常用的格式占位符写法及其代表的意义。
选项说明
%H提交对象(commit)的完整哈希字串
%h提交对象的简短哈希字串
%T树对象(tree)的完整哈希字串
%t树对象的简短哈希字串
%P父对象(parent)的完整哈希字串
%p父对象的简短哈希字串
%an作者(author)的名字
%ae作者的电子邮件地址
%ad作者修订日期(可以用 -date= 选项定制格式)
%ar作者修订日期,按多久以前的方式显示
%cn提交者(committer)的名字
%ce提交者的电子邮件地址
%cd提交日期
%cr提交日期,按多久以前的方式显示
%s提交说明
你一定奇怪_作者(author)_和_提交者(committer)_之间究竟有何差别,其实作者指的是实际作出修改的人,提交者指的是最后将此工作成果提交到仓库的人。所以,当你为某个项目发布补丁,然后某个核心成员将你的补丁并入项目时,你就是作者,而那个核心成员就是提交者。
表 2-2 还列出了一些其他常用的选项及其释义。
选项说明
-p按补丁格式显示每个更新之间的差异。
--word-diff按 word diff 格式显示差异。
--stat显示每次更新的文件修改统计信息。
--shortstat只显示 --stat 中最后的行数修改添加移除统计。
--name-only仅在提交信息后显示已修改的文件清单。
--name-status显示新增、修改、删除的文件清单。
--abbrev-commit仅显示 SHA-1 的前几个字符,而非所有的 40 个字符。
--relative-date使用较短的相对时间显示(比如,“2 weeks ago”)。
--graph显示 ASCII 图形表示的分支合并历史。
--pretty使用其他格式显示历史提交信息。可用的选项包括 oneline,short,full,fuller 和 format(后跟指定格式)。
--oneline--pretty=oneline --abbrev-commit 的简化用法。
表 2-3 还列出了其他常用的类似选项。
-(n)仅显示最近的 n 条提交
--since, --after仅显示指定时间之后的提交。
--until, --before仅显示指定时间之前的提交。
--author仅显示指定作者相关的提交。
--committer仅显示指定提交者相关的提交
下面的命令列出所有最近两周内的提交:
$ git log --since=2.weeks
来看一个实际的例子,如果要查看 Git 仓库中,2008 年 10 月期间,Junio Hamano 提交的但未合并的测试脚本(位于项目的 t/ 目录下的文件),可以用下面的查询命令:
$ git log --pretty="%h - %s" --author=gitster --since="2008-10-01" \ --before="2008-11-01" --no-merges -- t/
2.4 Git 基础 - 撤消操作
撤消操作
修改最后一次提交
有时候我们提交完了才发现漏掉了几个文件没有加,或者提交信息写错了。想要撤消刚才的提交操作,可以使用 --amend 选项重新提交:
$ git commit --amend
取消已经暂存的文件
git reset HEAD
取消对文件的修改
git checkout --
记住,任何已经提交到 Git 的都可以被恢复。即便在已经删除的分支中的提交,或者用 --amend 重新改写的提交,都可以被恢复(关于数据恢复的内容见第九章)。所以,你可能失去的数据,仅限于没有提交过的,对 Git 来说它们就像从未存在过一样。
2.5 Git 基础 - 远程仓库的使用
远程仓库的使用
要查看当前配置有哪些远程仓库,可以用 git remote 命令,它会列出每个远程库的简短名字。在克隆完某个项目后,至少可以看到一个名为 origin 的远程库,Git 默认使用这个名字来标识你所克隆的原始仓库
也可以加上 -v 选项(译注:此为 --verbose 的简写,取首字母),显示对应的克隆地址:
$ git remote -v bakkdoor git://github.com/bakkdoor/grit.git cho45 git://github.com/cho45/grit.git defunkt git://github.com/defunkt/grit.git koke git://github.com/koke/grit.git origin git@github.com:mojombo/grit.git
这样一来,我就可以非常轻松地从这些用户的仓库中,拉取他们的提交到本地
添加远程仓库
要添加一个新的远程仓库,可以指定一个简单的名字,以便将来引用,运行 git remote add [shortname] [url]:
$ git remote
origin
$ git remote add pb git://github.com/paulboone/ticgit.git
$ git remote -v
origin git://github.com/schacon/ticgit.git
pb git://github.com/paulboone/ticgit.git
从远程仓库抓取数据
现在可以用字符串 pb 指代对应的仓库地址了。比如说,要抓取所有 Paul 有的,但本地仓库没有的信息,可以运行 git fetch pb:
$ git fetch pb
remote: Counting objects: 58, done.
remote: Compressing objects: 100% (41/41), done.
remote: Total 44 (delta 24), reused 1 (delta 0)
Unpacking objects: 100% (44/44), done.
From git://github.com/paulboone/ticgit
* [new branch] master -> pb/master
* [new branch] ticgit -> pb/ticgit
推送数据到远程仓库
项目进行到一个阶段,要同别人分享目前的成果,可以将本地仓库中的数据推送到远程仓库。实现这个任务的命令很简单: git push [remote-name] [branch-name]。如果要把本地的 master 分支推送到origin 服务器上(再次说明下,克隆操作会自动使用默认的 master 和 origin 名字),可以运行下面的命令:
$ git push origin master
只有在所克隆的服务器上有写权限,或者同一时刻没有其他人在推数据,这条命令才会如期完成任务。如果在你推数据前,已经有其他人推送了若干更新,那你的推送操作就会被驳回。你必须先把他们的更新抓取到本地,合并到自己的项目中,然后才可以再次推送。
查看远程仓库信息
我们可以通过命令 git remote show [remote-name] 查看某个远程仓库的详细信息,比如要看所克隆的 origin 仓库,可以运行:
$ git remote show origin * remote origin URL: git://github.com/schacon/ticgit.git Remote branch merged with 'git pull' while on branch master master Tracked remote branches master ticgit