
ES系列基于ElasticSearch6.4.x版本。
1、简介
ElasticSearch的存储设计天生就是分布式的。每个索引被分成多个分片(默认每个索引含5个主分片(primary shard)),每个主分片又可以有多个副本。当一个文档被添加或删除时(主分片中新增或删除),其对应的复制分片之间必须保持同步。如果我们不这样做,那么对于同一个文档的检索请求,得到的结果将不一致。保持分片副本同步和服务读取的过程就是我们所说的数据复制模型。
ElasticSearch的数据复制模型是基于主备份模型的。每一个复制组会有一个主分片,其他分片为复制分片。主分片服务器是所有索引操作的主要入口点(索引、更新、删除操作)。它负责验证它们并确保它们是正确的。一旦一个索引操作被主服务器接受,主服务器也负责将操作复制到其他副本。
2、基本写模型
ElasticSearch每个索引操作都首先被解析为一个使用路由的复制组,默认基于文档ID(routing),其基本算法为hash(routing) % (primary count)。一旦确定了复制组,则该操作将被转发到组的主分片(primary shard)。主分片负责验证操作并将其转发到其他副本。由于副本可以离线,所以不需要复制到所有副本。相反,弹性搜索维护一个应该接收操作的碎片副本列表。这个列表被称为in-sync副本,由主节点维护。正如其名称所暗示的,这些是一组“好”碎片副本,它们保证已经处理了所有已被用户认可的索引和删除操作。主负责维护这个不变式,因此必须将所有操作复制到这个集合中的每个副本。
主分片处理流程:
验证请求是否符合Elasticsearch的接口规范,如果不符合,直接拒绝。
在主分片上执行操作(例如索引、更新或删除一个文档)。如果执行过程中出错,直接返回错误。
将操作转发到当前同步副本集的每个副本。如果有多个副本,则并行执行。(in-sync当前可用、激活的副本)。
一旦所有的副本成功地执行了操作并对主服务器进行了响应,主服务器就会承认对客户机的请求的成功完成。
写请求的流程如下图所示(图片来源于《Elasticsearch权威指南》):
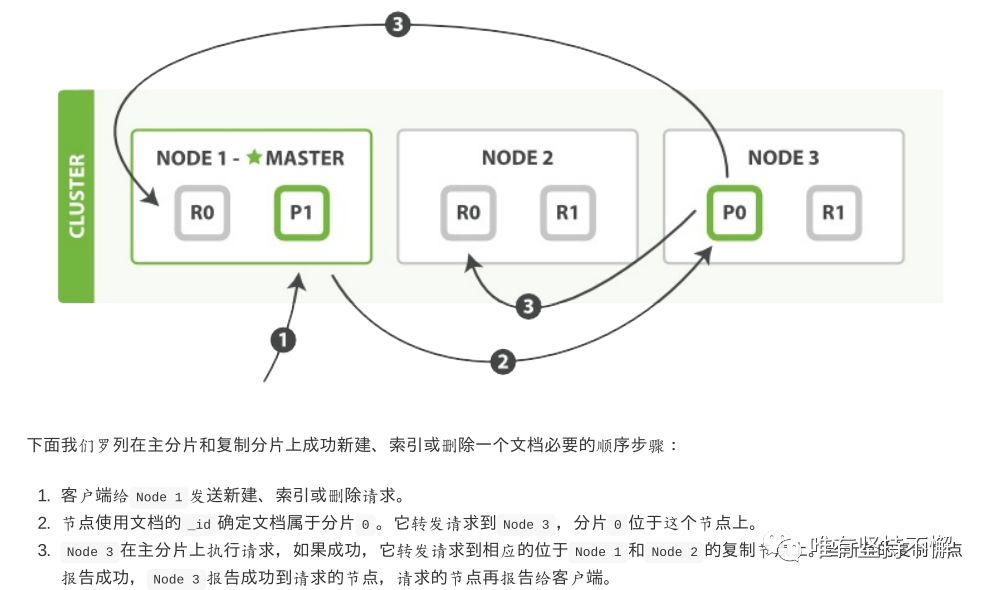
错误处理机制:
在索引过程中,许多事情可能会出错——磁盘可能会被破坏,节点可能彼此断开,或者一些配置错误可能导致一个副本的操作失败,尽管它在主服务器上是成功的。这些都是罕见的,但一旦发生将会引起同一复制组中各节点数据不一致情况发生,故主分片节点必须提供容错机制确保数据恢复到一致。
另外一种情况是如果主服务器不可用,托管主节点的节点将向集群master发送一条消息。索引操作将等待(默认情况下最多1分钟),以便master服务器将其中一个副本提升为一个新的主节点。然后,该操作将被转发到新的主服务器进行处理。请注意,主服务器(master)还监控各个节点的健康状况,并可能决定主动降级主节点。这通常发生在持有主节点的节点通过网络问题与集群隔离的情况下。为了更好的理解master服务器与主分片所在服务器的关系,下面给出一个ElasticSearch的集群说明图:
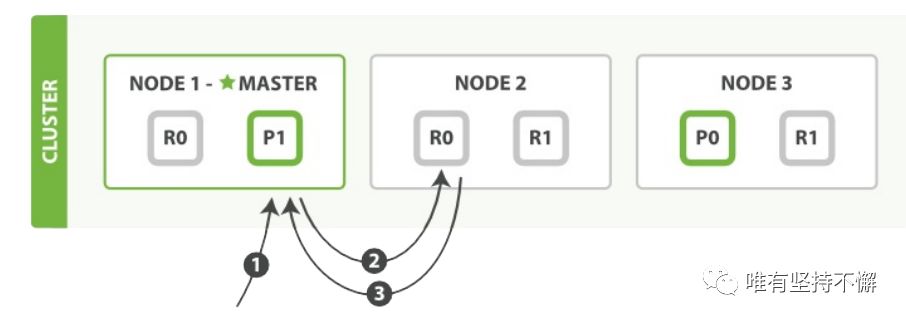
其中NODE1为整个集群的master服务器,而第一个复制组(P0,R0,RO,其主分片所在服务器NODE3),第二个复制组(P1,R1,R1,其主分片所在服务器NODE1)。(请重点理解两个角色,集群Master服务器、主分片服务器)。
一旦在主服务器上成功执行了操作,主服务器就必须确保数据最终一致,即使由于在副本上执行失败或由于网络问题导致操作无法到达副本(或阻止副本响应)造成的。为了避免数据在复制组内数据的不一致性(例如在主分片中执行成功,但在其中一两个复制分片中执行失败),主分片在如果未在指定时间内(默认一分钟)未收到复制分片的成功响应或是收到错误响应,主分片会向Master服务器发送一个请求,请求集群Master从同步副本中删除有问题的分片,只有在主分片服务器收到集群Master已将错误分片删除的结果后,才会完成本次操作。同时,集群master还会指示另一个节点开始构建新的分片副本,以便将系统恢复到一个健康状态。
主分片将一个操作转发到副本时,首先会使用副本数来验证它仍然是活动的主节点。如果由于网络分区(或长GC)而被隔离,那么在意识到它已经被降级之前,它可能会继续处理传入的索引操作并转发到从服务器。来自陈旧的主服务器的操作将会被副本服务器拒绝。当主接受到来自副本的响应为拒绝它的请求时,此时的主分片会向Master服务器发送请求,最终将知道它已经被替换了,后续操作将会路由到新的主分片服务器上。
如果没有副本,那会发生什么呢?
这是一个有效的场景,可能由于配置而发生,或者是因为所有的副本都失败了。在这种情况下,主分片要在没有任何外部验证的情况下处理操作,这可能看起来有问题。另一方面,主分片服务器不能自己失败其他的分片(副本),而是请求master服务器代表它这样做。这意味着master服务器知道主分片是该复制组唯一的可用拷贝。因此,我们保证master不会将任何其他(过时的)分片副本提升为一个新的主分片,并且任何索引到主分片服务器的操作都不会丢失。当然这样意味着我们只使用单一的数据副本,物理硬件问题可能导致数据丢失。请参阅Wait For Active Shards,以获得一些缓解选项,(该参数项将在下一节中详细描述)。
注:在一个ElasticSearch集群中,存在两个维度的选主。Master节点的选主、各个复制组主分片的选主。详细的原理分析将在源码分析篇深入学习。
3、基本读模型
在Elasticsearch中,可以通过ID进行非常轻量级的查找,也可以使用复杂的聚合来获取非凡的CPU能力。主备份模型的优点之一是它使所有的分片副本保持相同(除了异常情况恢复中),非常适合负载均衡。通常,一个同步副本就足以满足读取请求。
当一个节点接收到read请求时,该节点根据路由规则负责将其转发给相应的数据节点,对响应进行整理,并对客户端作出响应。我们称该节点为该请求的协调节点。基本流程如下:
将读请求路由到到相关的分片节点。注意,由于大多数搜索条件中不包含分片字段,所以它们通常需要从多个分片组中读取数据,每个分片代表一个不同的数据子集(默认5个数据子集,因为ElasticSearch默认的主分片个数为5个)。
从每个分片复制组中选择一个副本。读请求可以是复制组中的主分片,也可以是其副本分片。在默认情况下,ElasticSearch分片组内的读请求负载算法为轮询。
根据第二步选择的各个分片,向选中的分片发送请求。
汇聚各个分片节点返回的数据,然后返回个客户端,注意,如果带有分片字段的查询,将之后转发给一个节点,该步骤可省略。
异常处理:
当一个碎片不能响应一个read请求时,协调节点将从同一个复制组中选择另一个副本,并将碎片级搜索请求发送给该副本。重复的失败会导致没有碎片副本可用。在某些情况下,比如搜索,ElasticSearch会更倾向于快速响应,返回成功的分片数据给客户端 ,并在响应包中指明哪些分片节点发生了错误。
4、Elasticsearch主备模型隐含含义
在正常操作下,每个读取操作一次为每个相关的复制组执行一次。只有在失败条件下,同一个复制组的多个副本执行相同的搜索。
由于数据首先是在主分片上进行索引后,然后才转发请求到副本,在转发之前数据已经在主分片上发生了变化,所以在并发读时,如果读请求被转发到主分片节点上,那该数据在它被确认之前(主分片再等待所有副本全部执行成功)就已经看到了变化。【有点类似于数据库的读未提交】。
主备模型的容错能力为两个分片(1主分片,1副本)。
5、ElasticSearch 读写模型异常时可造成的影响
在失败的情况下,以下是可能的:
- 1个分片节点可能减慢整个集群的索引性能
因为在每次操作期间(索引),主分片在本地成功执行索引动作后,会转发请求到期复制分片节点上,此时主分片需要等待所有同步副本节点的响应,单个慢分片可以减慢整个复制组的速度。当然,一个缓慢的分片也会减慢那些被路由到它的搜索。
- 脏读
一个孤立的主服务器可以公开不被承认的写入。这是由于一个孤立的主节点只会意识到它在向副本发送请求或向主人发送请求时被隔离。在这一点上,操作已经被索引到主节点,并且可以通过并发读取读取。Elasticsearch可以通过在每秒钟(默认情况下)对master进行ping来减少这种风险,并且如果没有已知的主节点,则拒绝索引操作。
本文详细介绍了ElasticSearch文档的读写模型的设计思路,涉及到写模型及其异常处理、读模型及其异常处理、主备负载模型背后隐含的设计缺陷与ElasticSearch在异常情况带来的影响。各实现细节将在源码分析篇深入学习。
下一篇开始学习Document API Index API(文档索引API)。
关注公众号可查看更多文章:

本文分享自微信公众号 - 中间件兴趣圈(dingwpmz_zjj)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。









