
随着大数据技术的迅速发展以及对数据价值的认识逐渐加深,大数据已经融合到各行各业。据可靠权威数据显示,超过39.6%的企业正在应用数据并从中获益,超过89.6%的企业已经成立或计划成立相关的大数据分析部,超过六成的企业在扩大数据的投入力度度。在这样的大数据行业背景下AnalyticDB for MySQL3.0基础版发布了。AnalyticDB for MySQL3.0(以下简称ADB for MySQL3.0)基础版是在总结ADB for MySQL2.0产品研发与应用经验的基础上,匠心打磨推出的新一代分析型数据库,目前正在火热公测中。
ADB for MySQL3.0基础版融合了分布式、弹性计算与云计算的优势,对规模性、易用性、可靠性和安全性等方面进行了大规模的改进,充分满足不同场景数据仓库的需求。支持更大规模的并发访问、更快读写能力以及更智能的混合查询负载管理等,实现更精细化的资源利用和更低成本的投入,让用户能更加专注于业务发展,专注于数据价值。
相比于ADB for MySQL 2.0版本,3.0版本具有以下核心价值:
核心价值
简单易用
好用是数据库价值真正的体现,ADB for MySQL3.0基础版高度兼容MySQL,更好的MySQL协议兼容以及完整的SQL和语法支持,大多数场景无需修改代码即可用ADB for MySQL3.0版平滑替换MySQL,迁移使用成本极低。对于MySQL社区周边工具也可以无缝接入。
更高性价比
支持按量付费和包年包月,除了灵活的计费模式外还支持单独磁盘扩容。磁盘灵活扩缩对用户而言最直接红利是进一步降低了成本。新购时根据实际使用量购买相应磁盘空间,无需为固定的多余空间买单;当用户磁盘达到瓶颈时降低了由于翻倍扩容来带的额外成本。
除了支持磁盘灵活扩缩外,ADB for MySQL 3.0版本售价也大幅度降低。以C8规格为例,其售卖价格比2.0版本同等规格便宜最多21%。
云原生
OSS分层存储,冷热数据分离存储,历史数据无限保留;无缝对接云端海量算力(PolarDB和DLA等)。
更大规模和更快读写能力
基于强一致raft协议的副本同步机制以及轻量的索引构建方式,具有承载更大吞吐数据实时写入和读取能力。优化分布式混合计算引擎和优化器以达到更高的复杂计算能力。3.0版本写入性能是2.0版本同等规格的1.5倍,查询TPC-H (100g)是2.0版本的1.4倍。
更高可用/可靠性
服务秒级恢复,AZ内/跨AZ部署,可用性高于99.95%,自动故障检测、摘除和副本重搭。数据三副本存储、定时全量和增量备份,提供金融级别的数据可靠性保证。
更高安全
相比2.0版本,具有更完善和细化的权限体系模型,白名单和集群级别RAM控制,回收站730天超长保存,审计与合规记录所有SQL操作。
AnalyticDB for MySQL典型应用场景
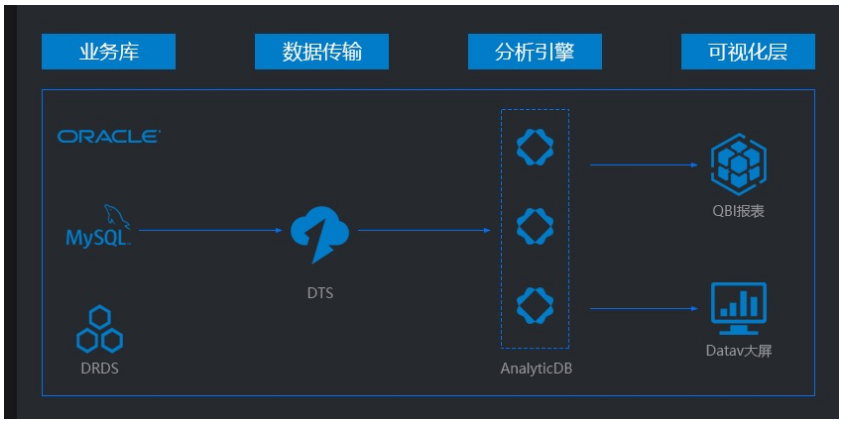
场景一 数据仓库场景
ADB for MySQL给MySQL技术栈公司带来福音,是业界唯一一款完全兼容MySQL协议的数据仓库产品。通过ADB for MySQL企业客户可以低成本且快速搭建大数据平台,其实时特性又可以助力企业快速发展。
- 相比离线数仓方案,成本降低55%。相比ADB for MySQL2.0方案,成本降低约15%;
- 相比离线数仓方案,报表数据延时从天级别缩短至秒级。相比ADB for MySQL2.0方案,数据延时更短;
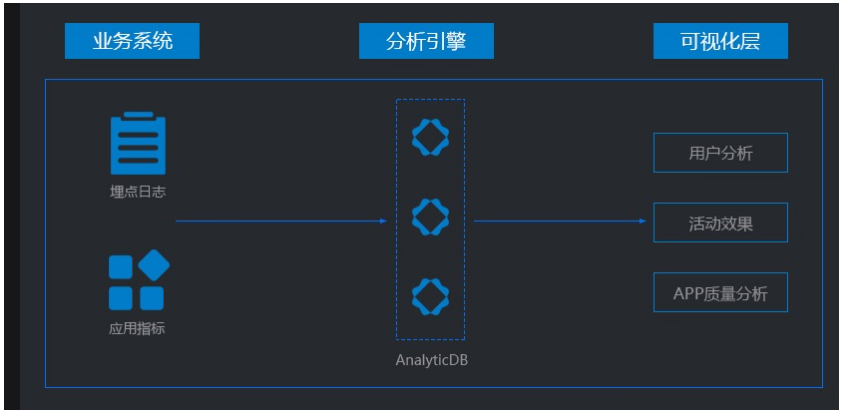
场景二 实时运营场景
在互联网行业精益化运营的背景下,数据分析已成为运营的标配,大家都希望通过精细的分析来提高运营的效率。拿移动App行业为例,移动App行业面临以下两个主要问题:
- 营销推广困难
移动APP推 困难, 户下载少,留存率低。如何提高下载量及留存率成为每个移动应用开发企业关注的核心问题 - 缺少运营分析能
终端种类多,适配量大。综合性能和户体验等问题是移动APP产品从开发到上线需要一直关注并迭代改进。
ADB for MySQL的实时和海量大数据高并发复杂查询特性,最适合做精细化运营。具体到App行业,ADB for MySQL的写入和数据实时特性可以很好的解决移动App行业面临的问题。
- 海量埋点以及指标数据实时写入,ADB for MySQL3.0写入更快,单表最大4PB;
- 实时洞察用户行为、App终端各种指标透视分析;
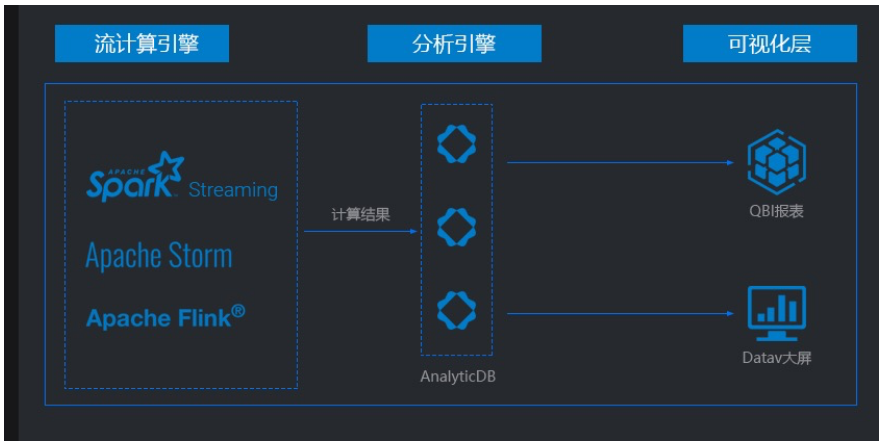
场景三 实时计算清洗回流
在实时计算的某些场景下,客户通常会将流计算清洗结果数据回流至MySQL等单机数据库,作为报表库来查询使用。当单机数据量或者单表数据量非常大时,传统的关系型数据库会出现报表查询卡顿的问题。ADB for MySQL能够很好地解决卡顿的问题,支持实时计算单表数据数千亿条,快速查询分析PB级别的实时报表,无需分库分表。
写在最后
AnalyticDB for MySQL3.0基础版火热公测中,免费提供首席专家服务,名额有限快来申请。
原文链接
本文为云栖社区原创内容,未经允许不得转载。











