

一. 介绍
本文将对OpenShift中共享jenkins的方式进行说明。共享jenkins主要针对默认的行为而言的,OpenShift默认情况下,在每个project中第一次创建pipeline都会自动运行一个jenkins实例,那么有没有一种方法实现多个project共用一个jenkins或者整个OCP平台使用一个jenkins呢?答案是肯定的。
为了便于描述,我们将OCP中多个project共用的jenkins称为共享jenkins。OpenShift中实现共享jenkins有两种方法:
方法一:在一个全局项目中部署jenkins,所有的pipeline创建在该项目中
方法二:在一个项目中创建jenkins,采集分布在不同project中的pipeline
在开始说明上述两种方法之前,先说明一点jenkins相关的配置。因为共享jenkins意味着jenkins中jobs会很多,需要配置更多的资源(CPU/MEM)来支撑job运行,否则jenkins经常会OOM错误退出。默认内存限制为512M,建议将JVM_ARCH设置为x86_64,内存限制设置为4G或者8G,增加MetaspaceSize(默认100m)的大小。
通过在jenkins的dc中增加环境变量OPENSHIFT_JENKINS_JVM_ARCH=x86_64来修改JVM_ARCH,增加环境变量JAVA_GC_OPTS=“-XX:+UseParallelGC -XX:MinHeapFreeRatio=20 -XX:MaxHeapFreeRatio=40 -XX:GCTimeRatio=4 -XX:AdaptiveSizePolicyWeight=90 -XX:MaxMetaspaceSize=1024m”设置MetaspaceSize大小。
更多OpenShift jenkins的参数设置,请参考官方说明。
本文所有测试在OCP 3.6验证通过,建议先阅读《不为人知的OpenShift Jenkins权限细节》理解OCP jenkins的权限再阅读本博客。
二. 禁止默认行为
在实现共享jenkins之前,先要禁用掉OCP的默认行为——也就是每个project在第一次创建jenkins的时候会自动创建一个jenkins实例。
默认行为解析:OpenShift在每个项目中,第一次创建pipeline时,会检测当前项目中是否存在名为jenkins的service,如果不存在,则会在openshift project中查找名为jenkins-ephemeral的template,并在当前project下实例化一个jenkins server,关于jenkins-ephemeral中的内容可查看模版的定义。
默认使用openshift项目下的jenkins-ephemeral模版进行实例化jenkins,这样管理员就可以通过修改jenkins-ephemeral模版来实现在jenkins实例化中创建一些其他的资源对象。当然这种默认行为是可以定义的,通过在master配置文件(/etc/origin/master/master-config.yaml)中设置如下参数:
12345678
jenkinsPipelineConfig: autoProvisionEnabled: true templateNamespace: openshift templateName: jenkins-ephemeral serviceName: jenkins parameters: key1: value1 key2: value2
参数说明:
1)autoProvisionEnabled:默认为true,如果设置为false,则表示不开启默认行为,第一次创建pipeline时,不会实例化jenkins。
2)templateNamespace:实例化jenkins使用的模版所在的namespace,默认为openshift。
3)templateName:实例化jenkins所使用的模版名称,默认为jenkins-ephemeral。
4)serviceName:第一次创建pipeline后检测jenkins service的名称,在实例化jenkins的模版中定义的service名称必须与该参数一致。
5)parameters:可以定义传入实例化jenkins模版的参数,需要在模版中预先定义好。
使用上述参数管理员完全可以自定义默认行为或者禁用自动实例化jenkins的行为。
实现共享jenkins的前提是通过设置autoProvisionEnabled=false禁用每个project自动启动jenkins实例的行为,其他参数保持默认即可。注意修改master配置文件之后必须重启master服务使得配置更改生效。
三. 方法一的实现
使用一个项目创建jenkins实例,将该项目做为一个全局项目,在该项目下创建所有的pipeline。下面描述操作过程:
1. 禁用默认行为
1)修改master配置文件,设置autoProvisionEnabled=false
1234567
# vi /etc/origin/master/master-config.yaml......jenkinsPipelineConfig: autoProvisionEnabled: false templateNamespace: openshift templateName: jenkins-ephemeral serviceName: jenkins
2)重启master服务
1
# systemctl restart atomic-openshift-master
注:高可用情况下,在所有master节点修改配置文件,重启atomic-openshift-master-api服务。
2. 创建一个项目,并实例化jenkins
1)创建名为share-jenkins的项目
12
# oc login -u system:admin # oc new-project share-jenkins
2)实例化jenkins server
可通过web界面和命令行实现,这里我们使用命令行
12
# oc project share-jenkins# oc new-app --template=jenkins-ephemeral --param=JVM_ARCH=x86_64 --param=MEMORY_LIMIT=4Gi -e JAVA_GC_OPTS="XX:+UsParallelGC -XX:MinHeapFreeRatio=20 -XX:MaxHeapFreeRatio=40 -XX:GCTimeRatio=4 -XX:AdaptiveSizePolicyWeight=90 -XX:MaxMetaspaceSize=1024m"
具体实例化jenkins的参数可根据需要设置,或部署之后再次修改dc文件均可,但必须保证创建的service名称为jenkins。
3. 设置项目为全局项目
1)设置用户可见性为全局
此操作目的是让所有需要使用jenkins的用户都可以访问该项目,通常是将特定的用户或组指定为项目的view或edit。这里我们直接将所有认证用户赋予view权限,权限控制后续在jenins中实现。
1
# oc policy add-role-to-group view system:authenticated
2)设置jenkins可操作其他项目
这种方式需要赋予serviceaccount jenkins对其他所有项目有操作权限,因为该项目中的pipeline要对其他项目执行操作。
如果项目数量相对固定,那么可以单独对这几个项目设置权限
1
# oc policy add-role-to-user edit system:serviceaccount:share-jenkins:jenkins -n [other_project]
如果项目数量不固定,则可以设置为将serviceaccount jenkins赋予cluster-admin的role
1
# oadm policy add-cluster-role-to-user cluster-admin -z jenkins
4. 创建测试pipeline
为了后续测试pipeline,我们创建两个pipeline,并实现简单操作其他项目。
1)创建测试项目demo-dev和demo-uat
12
# oc project demo-dev # oc project demo-uat
如果使用对单独项目赋权,则执行如下操作:
12
# oc policy add-role-to-user edit system:serviceaccount:share-jenkins:jenkins -n demo-dev# oc policy add-role-to-user edit system:serviceaccount:share-jenkins:jenkins -n demo-uat
2)创建演示pipeline
创建两个pipeline,用于演示,分别操作demo-dev和demo-uat中的资源 ,实际应用中pipeline根据具体的场景编写。
在share-jenkens项目中创建名为dev-mariadb的演示pipeline,内容如下:
12345678910111213
node('maven') {def project_name = 'demo-dev' stage('clean mariadb') { sh "oc project ${project_name}" sh "oc delete dc,svc,secret -l app=mariadb-ephemeral -n ${project_name}" } stage('create mariadb') { sh "oc new-app --template=mariadb-ephemeral -n ${project_name}" } stage('complate') { echo "deploy complate" }}
同样在share-jenkens项目中创建名为uat-mariadb的演示pipeline,内容与dev-mariadb一致,只需要把project_name设置为demo-uat即可。创建之后就可以在jenkins中看到两个job,如下图所示:
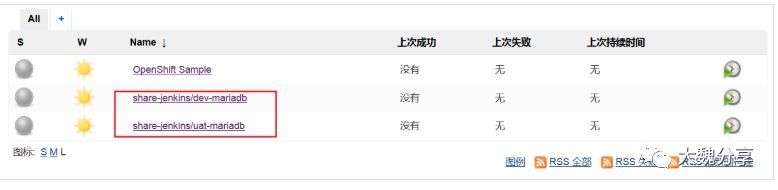
测试运行两个job,可以看看到均正确运行,且分别在demo-dev和demo-uat项目中创建了mariadb的容器。
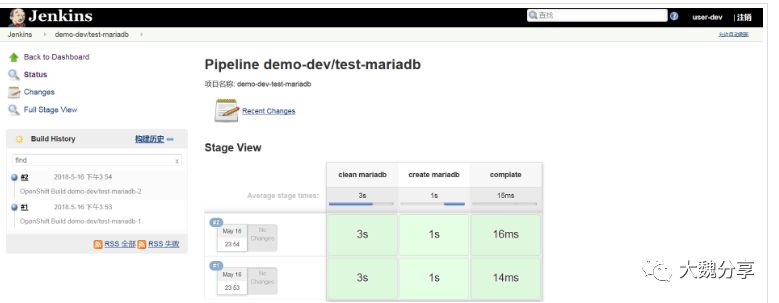
5. 设置jenkins中job权限
可以看到这种方式已经实现了共享jenkins,但是默认jenkins中的job,普通用户是没办法呢运行和编辑的,因为普通用户在该项目中被赋予的是view权限。需要解决jenkins中job的权限问题,可参考上一篇博客《不为人知的OpenShift Jenkins权限细节》了解原理,这里我们直接说明操作过程。
1)在OCP中增加测试用户
创建两个用于测试的用户user-dev和user-uat
12
# htpasswd /etc/origin/master/htpasswd user-dev# htpasswd /etc/origin/master/htpasswd user-uat
赋予user-dev对project demo-dev为edit role,赋予user-uat对project demo-uat为edit role;这样使用user-dev登录OCP后可以看到项目demo-dev和share-jenkins,使用user-uat登录OCP后可以看到项目demo-uat和share-jenkins,但是对share-jenkins项目只有view权限。
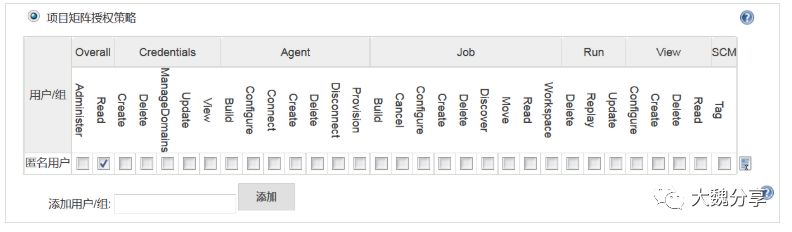
2)修改jenkins权限为“项目矩阵授权策略”
使用管理员登录jenkins,进入“系统管理——Configure Global Security”,将授权策略设置为“项目矩阵授权策略”,并开启匿名用户的overall/read权限
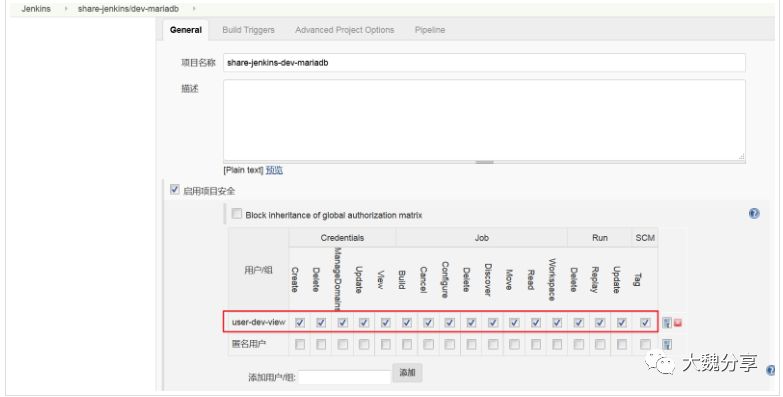
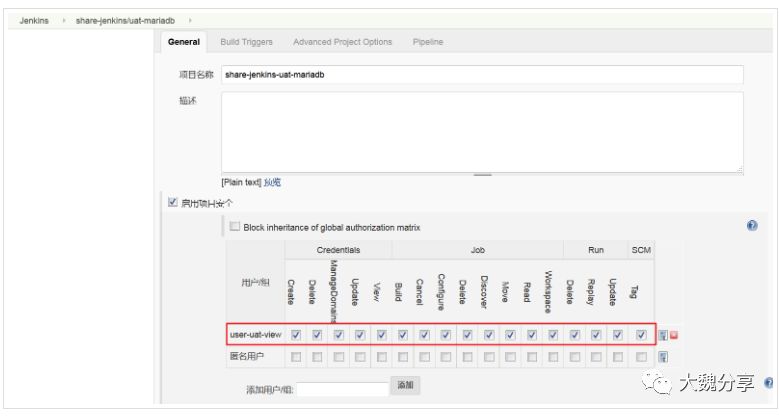
3)分别赋予user-dev和user-uat对应的job权限
分别进入jenkins job中,设置user-dev对job dev-mariadb有读写权限,设置user-uat对job uat-mariadb有读写权限。
6. 分别登录用户测试
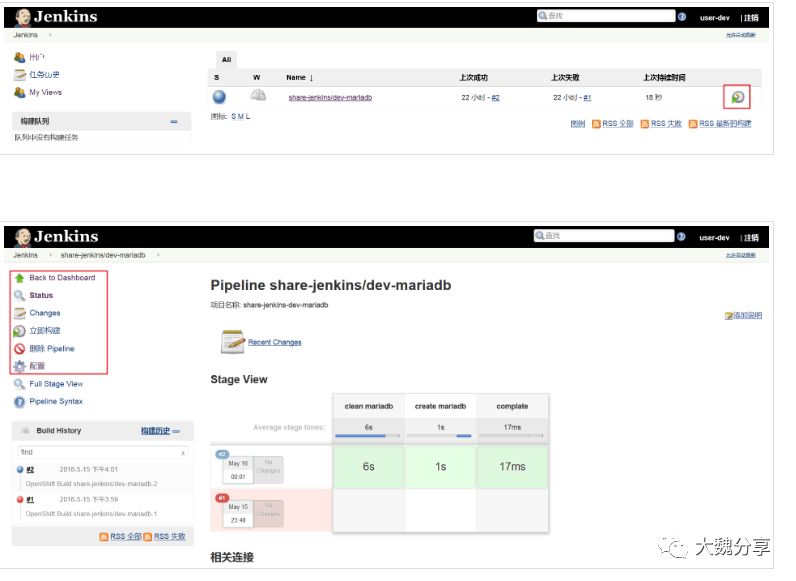
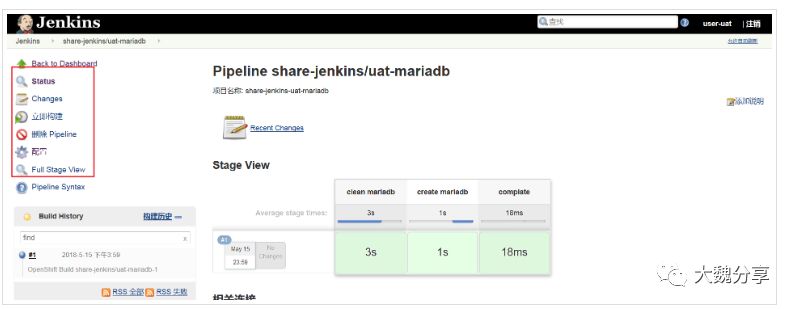
使用user-dev登录jenkins,可以看到jenkins中所有的job,但是仅对job dev-mariadb有构建和修改的权限,其余均为只读权限。用户user-uat也是类似的。
到此为止,已经完成了共享jenkins的配置,这种方法的优缺点如下:
优点:
1)实现了jenkins job层面的权限控制 2)实现和配置过程相对简单 3)权限统一由jenkins控制,简化了赋权操作
缺点:
1)所有pipeline需要由管理员统一创建,增加管理员负担 2)所有pipeline在一个项目中,未做到pipeline的隔离
四. 方法二的实现
使用一个项目创建jenkins实例,使用jenkins plugins——[OpenShift sync](https://github.com/jenkinsci/openshift-sync-plugin)来同步不同project中的pipeline。
下面描述操作过程(最好将方法一中环境删除避免冲突):
1. 禁用默认行为
1)修改master配置文件,设置autoProvisionEnabled=false
123456
# vi /etc/origin/master/master-config.yaml jenkinsPipelineConfig: autoProvisionEnabled: false templateNamespace: openshift templateName: jenkins-ephemeral serviceName: jenkins
2)重启master服务
1
# systemctl restart atomic-openshift-master
注:高可用情况下,在所有master节点修改配置文件,重启atomic-openshift-master-api服务。
2. 创建一个项目,并实例化jenkins
1)创建名为share-jenkins的项目
12
# oc login -u system:admin # oc new-project share-jenkins
2)实例化jenkins server
可通过web界面和命令行实现,这里我们使用命令行
12
# oc project share-jenkins# oc new-app --template=jenkins-ephemeral --param=JVM_ARCH=x86_64 --param=MEMORY_LIMIT=4Gi -e JAVA_GC_OPTS="XX:+UsParallelGC -XX:MinHeapFreeRatio=20 -XX:MaxHeapFreeRatio=40 -XX:GCTimeRatio=4 -XX:AdaptiveSizePolicyWeight=90 -XX:MaxMetaspaceSize=1024m"
具体实例化jenkins的参数可根据需要设置,或部署之后再次修改dc文件均可,但必须保证创建的service名称为jenkins。
3. 设置项目为全局项目
1)设置用户可见性为全局
此操作目的是让所有需要使用jenkins的用户都可以访问该项目,通常是将特定的用户或组指定为项目的view或edit。这里我们直接将所有认证用户赋予view权限,权限控制后续在jenins中实现。
1
# oc policy add-role-to-group view system:authenticated
2)设置jenkins可操作其他项目
这种方式需要赋予serviceaccount jenkins对其他所有项目有操作权限,因为该项目中的pipeline要对其他项目执行操作。
如果项目数量相对固定,那么可以单独对这几个项目设置权限
1
# oc policy add-role-to-user edit system:serviceaccount:share-jenkins:jenkins -n [other_project]
如果项目数量不固定,则可以设置为将serviceaccount jenkins赋予cluster-admin的role
1
# oadm policy add-cluster-role-to-user cluster-admin -z jenkins
4. 创建测试项目
1)创建测试项目demo-dev和demo-uat
12
# oc project demo-dev # oc project demo-uat
2)分别设置user-dev和user-uat有项目edit权限
12
# oc policy add-role-to-user edit user-dev -n demo-dev# oc policy add-role-to-user edit user-uat -n demo-uat
3)赋予jenkins sa可操作权限
如果使用单独项目赋权,则执行如下命令:
12
# oc policy add-role-to-user edit system:serviceaccount:share-jenkins:jenkins -n demo-dev# oc policy add-role-to-user edit system:serviceaccount:share-jenkins:jenkins -n demo-uat
5. 配置共享jenkins
1)创建jenkins service
根据OCP查找jenkins server的原理可知,在项目中创建pipeline时,会查找名为jenkins的service,所以我们手动创建service,并使用cname将访问service请求转发到share-jenkins项目中的jenkins server。
使用如下service定义文件创建jenkins service。
12345678910
cat > jenkins-svc.yaml << EOFkind: "Service"apiVersion: "v1"metadata: name: "jenkins"spec: type: ExternalName externalName: jenkins.share-jenkins.svc.cluster.localselector: {}>>EOF
分别在demo-dev和demo-uat中创建jenkins service
12
# oc create -f jenkins-svc.yaml -n demo-dev# oc create -f jenkins-svc.yaml -n demo-uat
2)创建route
123456789101112131415
cat > jenkins-route.yaml << EOFapiVersion: v1kind: Routemetadata: creationTimestamp: null name: jenkinsspec: host: jenkins-share-jenkins.apps.cloud.com to: kind: Service name: jenkins weight: 100 wildcardPolicy: Nonestatus: {} >>EOF
分别在demo-dev和demo-uat中创建jenkins route
12
# oc create -f jenkins-route.yaml -n demo-dev# oc create -f jenkins-route.yaml -n demo-uat
注意:必须创建route对象,并将hostname指定为share-jenkins中对应的jenkins域名,否则无法通过点击view log跳转到jenkins server中。因为此处hostname已被share-jenkins项目的jenkins server使用,所以web console中会出现如下警告提示,忽略即可。
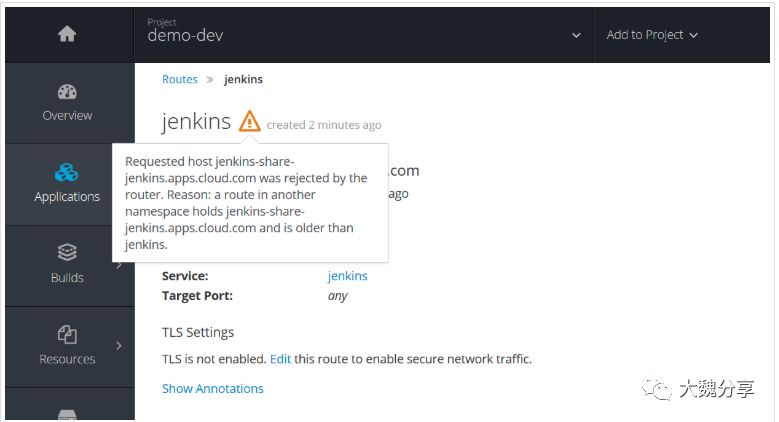
3)配置jenkins pipeline同步插件
默认OpenShift Jenkins Sync的插件仅会同步当前project的pipeline,我们手动在插件中添加需要同步的project。
使用管理员登录jenkins,切换到“系统管理——系统设置”,配置OpenShift Jenkins Sync插件,添加创建的演示项目demo-dev和demo-uat,如下图:
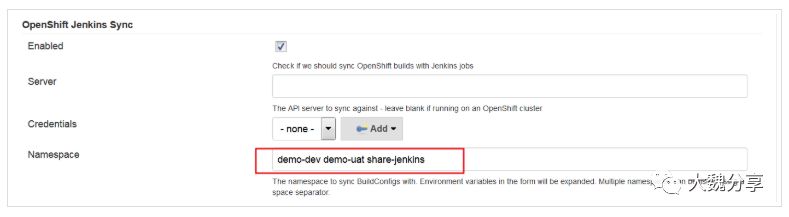
如图所示,多个项目使用空格分隔。
6. 创建演示pipeline
1)在demo-dev下创建pipeline
使用user-dev登录OCP,在demo-dev项目下创建名为test-mariadb的演示pipeline,内容如下:
123456789101112
def project_name = 'demo-dev' node('maven') { stage('clean mariadb') { sh "oc delete dc,svc,secret -l app=mariadb-ephemeral -n ${project_name}" } stage('create mariadb') { sh "oc new-app --template=mariadb-ephemeral -n ${project_name}" } stage('complate') { echo "deploy complate" }}
2)在demo-uat下创建pipeline
同样使用user-uat登录OCP,在demo-uat项目下创建名为test-mariadb的演示pipeline,内容与demo-dev中的基本一致,仅需要修改project_name=’demo-uat’。
7. 测试共享jenkins
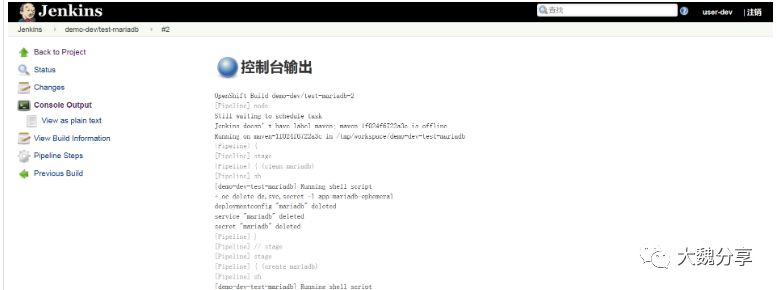
创建完成之后,使用user-dev登录jenkins,可以看到所有pipeline已经同步到jenkins job中了,如下图所示:
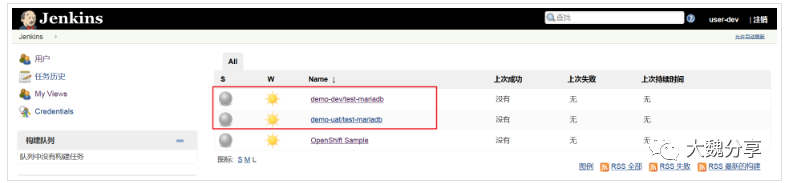
从图中可以看出对user-dev对所有job为只读权限,无法构建job。
注意:OpenShift Jnekins Sync插件配置多个项目后,会有一定的延迟(同步周期为5分钟),请内心等待数分钟。
以user-dev登录OCP,在项目demo-dev中,切换到pipeline界面,点击“start pipeline”按钮,pipeline开始构建,并且状态同步到jenkins中。
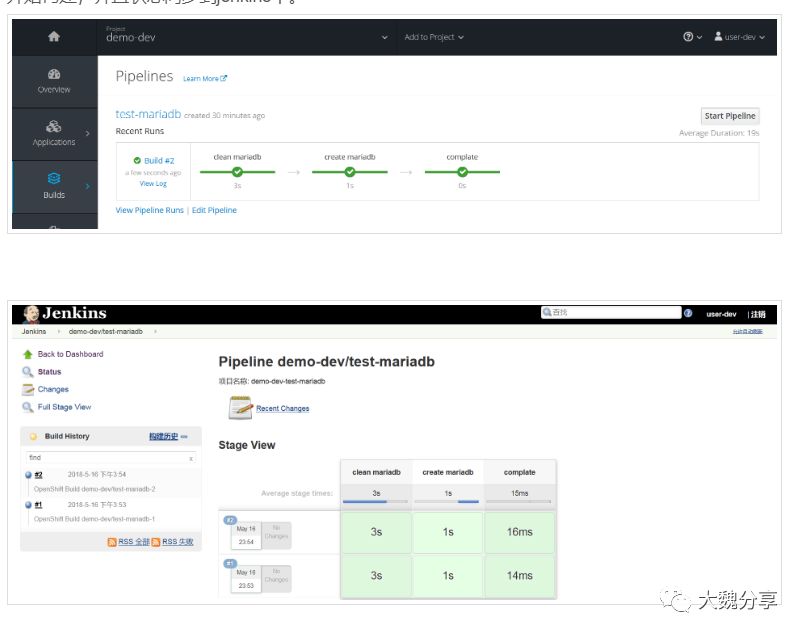
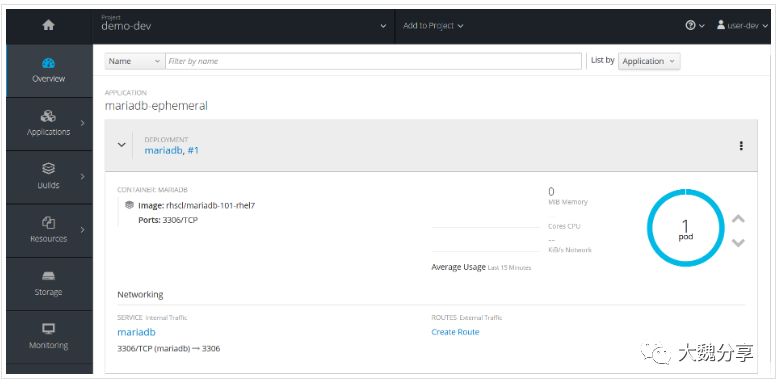
点击pipeline中的“view log”按钮,可以正常的跳转到share-jenkins项目中的jenkins server查看构建日志。
同样的可以使用user-uat登录测试。可以发现,user-uat登录之后,同样在jenkins中对job只有只读权限。用户只可以在OCP中启动pipeline,修改pipeline以及查看构建日志等。实际上,用户也完全没有对jenkins job有任何操做权限的必要。
另外在这种实现方法中,想要使用共享jenkins,每次新建一个project就需要在project中创建jenkins的service和route对象,如果project数目对固定,则手动创建即可,如果project名称不固定,则可以使用project-template实现自动创建。
到此为止,已经完成了共享jenkins的配置,这种方法的优缺点如下:
优点:
1)实现了pipeline的隔离 2)不同项目的pipeline由用户自己创建维护,无需管理员参与 3)jenkins中所有job为只读权限,安全性更高
缺点:
1)实现和配置过程相对复杂 2)在同步多个项目的pipeline时,效率偏低,第一次同步延迟在分钟级别
五. 方法一和方法二的对比
1)方法一中pipeline构建权限由jenkins控制,方法二中pipeline构建权限由OCP控制
2)方法一无法做到pipeline隔离,所有pipeline均在同一个项目中;尽管在jenkins中可以实现隔离 ,但是用户依然可以在OCP的项目中查看所有pipeline,但无法执行任何操作。方法二完美的实现了pipeline的隔离。
3)方法一所有的pipeline首次必须由管理员创建模版,后续可以由用户自行在jenkins中修改,而方法二pipeline完全交由用户管理,交给用户自己管理就有可能出现乱用。
4)方法一相对于方法二更健壮,在同步pipeline上出错的可能性更小,主要由于OpenShift Jenkins Sync插件的不稳定性导致。
六. 方法一与方法二的结合
由两种方法对比可以看出,都可以实现共享jenkins的目的,主要的区别在权限以及pipeline隔离性上。用户可以根据实际场景选择合适的方式。
下面我们尝试能否将方法一与方法二结合,理论上是可行的。我们在方法二的基础上,引入方法一中的job权限隔离,似乎是一种完美的方案。大致过程如下:
1)首先完成方法二的所有配置
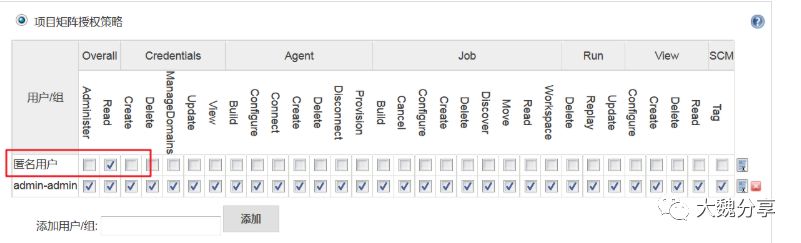
2)切换jenkins认证策略为“项目矩阵授权策略”,开启匿名用户的overall/read权限,如下图:
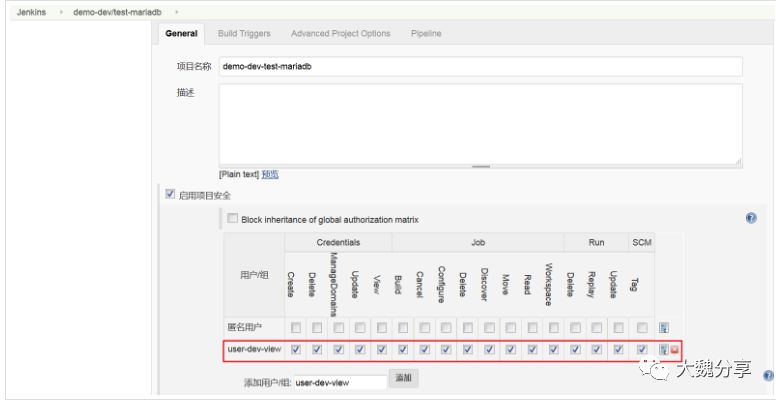
3)开启指定job的项目权限,并赋予特定的人
4)登录测试job可见性及操作权限
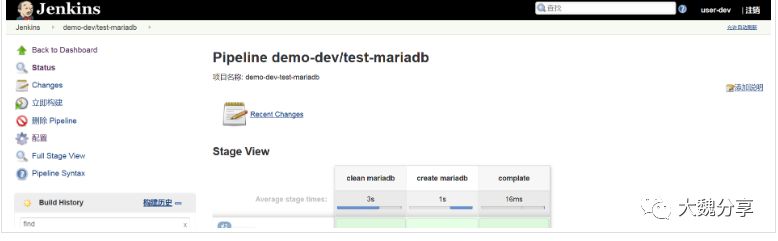
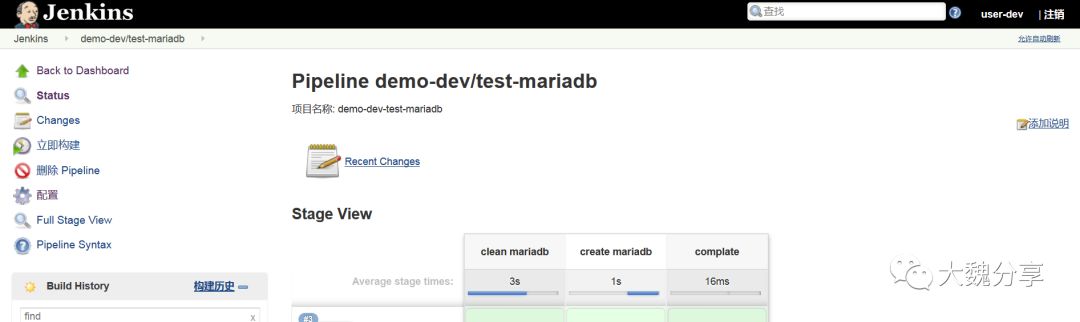
用户user-dev仅对job demo-dev/test-mariadb可见,而且有操作权限。
虽然可以将两种方法的优势都结合起来,但是引入了更多复杂性,如果单独使用方法一或方法二就能满足需求,则直接单独使用方法一或方法二即可。
七. 总结
本文通过不同的方法实现OCP中共享jenkins,分析了优缺点,并尝试将二者的优势结合在一起。用户可以根据具体的场景需求选择合适的方案。
八. 遇到的问题
第二种方法中不同project中的pipeline通过service设定的cname连接jenkins server,在初始中,可能会出现启动pipeline/job缓慢的问题,此时pipeline的状态new,如下图:
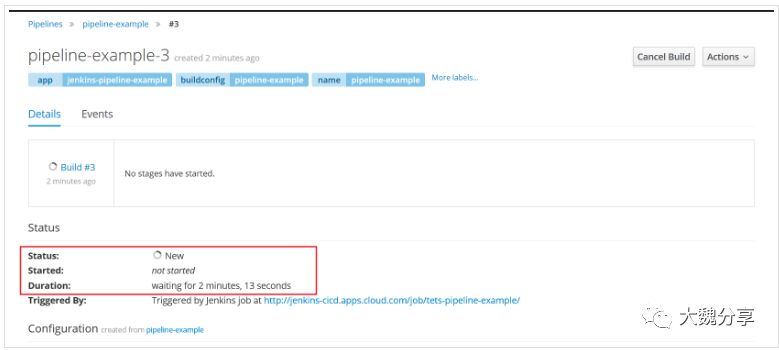
这种情况不用担心,该现象只是出现在刚开始的阶段,也可能不会出现。
魏新宇
"大魏分享"运营者、红帽资深解决方案架构师
专注开源云计算、容器及自动化运维在金融行业的推广
拥有MBA、ITIL V3、Cobit5、C-STAR、TOGAF9.1(鉴定级)等管理认证。
拥有红帽RHCE/RHCA、VMware VCP-DCV、VCP-DT、VCP-Network、VCP-Cloud、AIX、HPUX等技术认证
本文分享自微信公众号 - 大魏分享(david-share)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











