
##前言 在 Linux 底下的连结档有两种,一种是类似 Windows 的快捷方式功能的文件,可以让你快速的链接到目标文件(或目录),这种是软链接; 另一种则是透过文件系统的 inode 连结来产生新档名,而不是产生新文件!这种称为硬链接 (hard link)。 这两种玩意儿是完全不一样的东西呢!现在就分别来谈谈。
###1. 实体链接 在目录下创建一个条目,记录着文件名与 inode 编号,这个 inode 就是源文件的 inode。
删除任意一个条目,文件还是存在,只要引用数量不为 0。
有以下限制:不能跨越文件系统、不能对目录进行链接。
# ln /etc/crontab .
# ll -i /etc/crontab crontab
34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 crontab
34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 /etc/crontab
###2. 符号链接 符号链接文件保存着源文件所在的绝对路径,在读取时会定位到源文件上,可以理解为 Windows 的快捷方式。
当源文件被删除了,链接文件就打不开了。
因为记录的是路径,所以可以为目录建立符号链接。
# ll -i /etc/crontab /root/crontab2
34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 /etc/crontab
53745909 lrwxrwxrwx. 1 root root 12 Jun 23 22:31 /root/crontab2 -> /etc/crontab
##说明
###Hard Link (实体链接, 硬式连结或实际连结) 在前一小节当中,我们知道几件重要的信息,包括:
每个文件都会占用一个 inode ,文件内容由 inode 的记录来指向; 想要读取该文件,必须要经过目录记录的文件名来指向到正确的 inode 号码才能读取。 也就是说,其实文件名只与目录有关,但是文件内容则与 inode 有关。那么想一想, 有没有可能有多个档名对应到同一个 inode 号码呢?有的!那就是 hard link 的由来。 所以简单的说:hard link 只是在某个目录下新增一笔档名链接到某 inode 号码的关连记录而已。
举个例子来说,假设我系统有个 /root/crontab 他是 /etc/crontab 的实体链接,也就是说这两个档名连结到同一个 inode , 自然这两个文件名的所有相关信息都会一模一样(除了文件名之外)。实际的情况可以如下所示:
[root@www ~]# ln /etc/crontab . <==创建实体链接的命令
[root@www ~]# ll -i /etc/crontab /root/crontab
1912701 -rw-r--r-- 2 root root 255 Jan 6 2007 /etc/crontab
1912701 -rw-r--r-- 2 root root 255 Jan 6 2007 /root/crontab
你可以发现两个档名都连结到 1912701 这个 inode 号码,所以您瞧瞧,是否文件的权限/属性完全一样呢? 因为这两个『档名』其实是一模一样的『文件』啦!而且你也会发现第二个字段由原本的 1 变成 2 了! 那个字段称为『连结』,这个字段的意义为:『有多少个档名链接到这个 inode 号码』的意思。 如果将读取到正确数据的方式画成示意图,就类似如下画面:
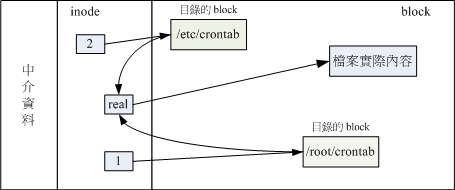
实体链接的文件读取示意图
上图的意思是,你可以透过 1 或 2 的目录之 inode 指定的 block 找到两个不同的档名,而不管使用哪个档名均可以指到 real 那个 inode 去读取到最终数据!那这样有什么好处呢?最大的好处就是『安全』!如同上图中, 如果你将任何一个『档名』删除,其实 inode 与 block 都还是存在的! 此时你可以透过另一个『档名』来读取到正确的文件数据喔!此外,不论你使用哪个『档名』来编辑, 最终的结果都会写入到相同的 inode 与 block 中,因此均能进行数据的修改哩!
一般来说,使用 hard link 配置链接文件时,磁盘的空间与 inode 的数目都不会改变! 我们还是由图 来看,由图中可以知道, hard link 只是在某个目录下的 block 多写入一个关连数据而已,既不会添加 inode 也不会耗用 block 数量哩!
备注: hard link 的制作中,其实还是可能会改变系统的 block 的,那就是当你新增这笔数据却刚好将目录的 block 填满时,就可能会新加一个 block 来记录文件名关连性,而导致磁盘空间的变化!不过,一般 hard link 所用掉的关连数据量很小,所以通常不会改变 inode 与磁盘空间的大小喔!
由上图其实我们也能够知道,事实上 hard link 应该仅能在单一文件系统中进行的,应该是不能够跨文件系统才对! 因为上图就是在同一个 filesystem 上嘛!所以 hard link 是有限制的:
不能跨 Filesystem; 不能 link 目录。
不能跨 Filesystem 还好理解,那不能 hard link 到目录又是怎么回事呢?这是因为如果使用 hard link 链接到目录时, 链接的数据需要连同被链接目录底下的所有数据都创建链接,举例来说,如果你要将 /etc 使用实体链接创建一个 /etc_hd 的目录时,那么在 /etc_hd 底下的所有档名同时都与 /etc 底下的檔名要创建 hard link 的,而不是仅连结到 /etc_hd 与 /etc 而已。 并且,未来如果需要在 /etc_hd 底下创建新文件时,连带的, /etc 底下的数据又得要创建一次 hard link ,因此造成环境相当大的复杂度。 所以啰,目前 hard link 对于目录暂时还是不支持的啊!
###Symbolic Link (符号链接,亦即是快捷方式) 相对于 hard link , Symbolic link 可就好理解多了,基本上, Symbolic link 就是在创建一个独立的文件,而这个文件会让数据的读取指向他 link 的那个文件的档名!由于只是利用文件来做为指向的动作, 所以,当来源档被删除之后,symbolic link 的文件会『开不了』, 会一直说『无法开启某文件!』。实际上就是找不到原始『档名』而已啦!
举例来说,我们先创建一个符号链接文件链接到 /etc/crontab 去看看:
[root@www ~]# ln -s /etc/crontab crontab2
[root@www ~]# ll -i /etc/crontab /root/crontab2
1912701 -rw-r--r-- 2 root root 255 Jan 6 2007 /etc/crontab
654687 lrwxrwxrwx 1 root root 12 Oct 22 13:58 /root/crontab2 -> /etc/crontab
由上表的结果我们可以知道两个文件指向不同的 inode 号码,当然就是两个独立的文件存在! 而且连结档的重要内容就是他会写上目标文件的『文件名』, 你可以发现为什么上表中连结档的大小为 12 bytes 呢? 因为箭头(-->)右边的档名『/etc/crontab』总共有 12 个英文,每个英文占用 1 个 byes ,所以文件大小就是 12bytes了!
关于上述的说明,我们以如下图示来解释:
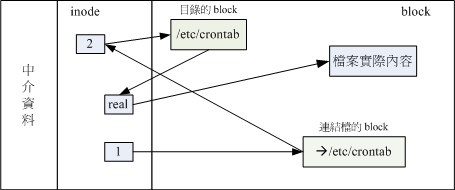
符号链接的文件读取示意图
由 1 号 inode 读取到连结档的内容仅有档名,根据档名链接到正确的目录去取得目标文件的 inode , 最终就能够读取到正确的数据了。你可以发现的是,如果目标文件(/etc/crontab)被删除了,那么整个环节就会无法继续进行下去, 所以就会发生无法透过连结档读取的问题了!
这里还是得特别留意,这个 Symbolic Link 与 Windows 的快捷方式可以给他划上等号,由 Symbolic link 所创建的文件为一个独立的新的文件,所以会占用掉 inode 与 block 喔!
由上面的说明来看,似乎 hard link 比较安全,因为即使某一个目录下的关连数据被杀掉了, 也没有关系,只要有任何一个目录下存在着关连数据,那么该文件就不会不见!举上面的例子来说,我的 /etc/crontab 与 /root/crontab 指向同一个文件,如果我删除了 /etc/crontab 这个文件,该删除的动作其实只是将 /etc 目录下关于 crontab 的关连数据拿掉而已, crontab 所在的 inode 与 block 其实都没有被变动!












