10月30日,全球权威数据调研机构IDC正式发布《IDCMarketScape: 中国DevOps云市场2019,厂商评估》报告。京东云凭借丰富的场景和实践能力,以及高质量的服务交付和平台稳定性,取得优异的成绩, 跻身“Major Players”(核心厂商)位置。
京东云DevOps能力起源于自身的业务实践,针对京东集团的复杂业务场景打造并经受住多次618、11.11电商大促的严峻考验,保证了高效高质的交付和对变化的灵活应对。能够支持复杂场景的自动化运维需求、实现工具链产品与平台化产品结合,帮助客户根据不同的需求灵活定制方案。
前两次的专题内容中,我们分别与大家分享了大型企业级监控系统的设计以及监控系统的可观测性与数据存储。今天,我们将通过介绍京东云DevOps落地实践,和大家继续分享DevOps中另一个重要内容:日志查询服务。
日志查询服务,是构建软件项目的基石之一,是系统稳定运行必不可少的一部分,已然成为DevOps中的标配选项。这里,我们来聊一聊京东云翼DevOps平台的日志查询服务实践。
本着客户为先,全心全意为用户服务的原则,云翼日志查询服务的发展分以下几个阶段解决用户的日志需求:
场景一:用户需要查看自己的应用日志,以此来判断自己的应用程序当前运行是否正常,或者在遇到问题时,需要通过查看应用输出的日志信息来定位问题。
针对用户的这个需求,我们开发并提供了现场日志查询功能。
何为现场日志?就是案发现场的日志。案发现场一般在哪里呢?当然是用户应用部署所在的主机了。
我们提供现场日志查询的功能,用于查询用户主机上的应用日志。该功能默认支持规范目录下的日志查询,且支持扩展的自定义路径。
- 规范目录:
/export/Logs/$appName/$instanceName/,在用户主机这个目录下的日志文件,会自动列到页面,用户选择要查询的文件进行查询即可。$appName代表用户的应用名称;$instanceName代表应用部署的实例名称。 - 用户自定义路径举例:
/export/test.log,由于这个路径对我们系统来讲是“不规范”的,用户如果需要查这个日志信息,就需要自己手动输入该日志路径,然后再执行查询操作。
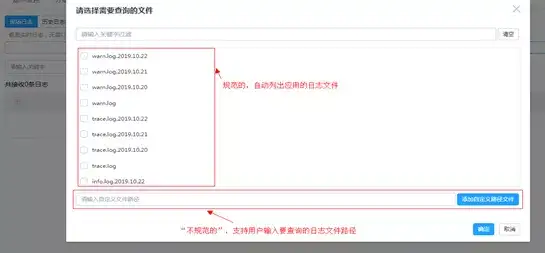
现场日志查询文件选择示例图
如何实现现场日志查询功能
想想一般我们自己要查看主机上的日志是怎么做的呢?第一步往往是ssh登录到主机,然后通过grep命令查询指定内容。是的,我们的现场日志就是将这一过程进行了平台化,用户在现场日志页面上选择要查询的日志文件,输入要查询的关键字,点查询按钮即可。出于安全性考虑,ssh认证我们采用密钥认证而非密码认证。当然了,既然通过ssh连接,那就要求用户主机必须开放22端口。
现场日志通过ssh查询遇到的问题
比如有的用户的主机是在VPC里的,ssh直接访问不到,怎么办呢?想想办法这个问题是可以解决的,那就是配置代理,这样就导致渐渐地要维护一堆的代理配置。
改进措施
随着云翼内部新的控制系统zero的出现(zero是一套控制系统,通过给用户主机上的zero-agent下发任务实现对用户主机的一些操作),现场日志查询有了新的实现方式,可以通过调用控制系统API,用控制系统下发任务的方式来实现日志查询,这样采用http的连接方式替代之前的ssh,不再依赖密钥,也不再需要再维护一堆的ssh代理配置了。嗯,感觉一下清爽了好多。
新的困境
改变实现方式后,发现一个新的问题,就是用户单条日志太大的情况下,查询数据量如果超过zero-agent一次传输数据量的限制会导致查询失败,这里就需要做个权衡了,要么用户调整日志长度,要么减小一页的数据展示条数,再要么可以考虑换一种查询方式,比如用下面将要介绍的历史日志查询,当然了,这只是权宜之计,历史日志功能并不是为了解决这个问题才产生的。
场景二:用户的应用部署在多台机器上,用户需要对多台机器上的日志进行集中检索,且做日志检索时不希望消耗自己机器上的资源(比如带宽、内存、CPU)。
为此,云翼的历史日志查询功能应运而生。我们期望历史日志支持最近7天的日志检索。
既然要集中检索,那我们首先需要及时把日志数据采集走,进行集中存储。这里需要用户做一个日志订阅的操作,其实就是告诉日志服务要采集哪个应用下的哪个日志文件的数据。
日志数据流向图:

上图反映了用户订阅后,用户日志数据的流向情况。可以看到数据存储涉及两种介质,一种是kafka,一种是ES,数据先缓存到kafka,最终流向ES。ElasticSearch简称ES,是一个开源的分布式搜索引擎,我们的历史日志查询功能正是借助于ES强大的搜索能力实现的。
下面依次介绍一下上图中的log-agent、fwd和indexer模块。
- log-agent,是云翼的日志采集客户端,部署在用户的应用主机上。它可以动态发现用户的订阅信息,实时采集日志数据并将数据上报给fwd模块。log-agent内部封装了rsyslog,通过控制rsyslog的配置以及程序的启停来实现对用户日志的采集。rsyslog是linux上一款比较成熟的系统日志采集工具,我们拿来采集应用级别的日志,当然也是可以的。
- fwd,这个模块负责接收log-agent上报的数据,并转发至kafka。它的价值在于解耦了log-agent和kafka,避免了成千上万的主机和kafka直连;当kafka有变动的时候,我们只给有限的几台fwd做修改和升级即可,不需要对所有的log-agent做统一的升级了。
- indexer,该模块可以被看作一个数据搬运工,负责把日志数据从kafka搬到ES。indexer的本质是rsyslog,它的输入是kafka,输出是ES。是不是发现rsyslog很强大?这个模块虽然简单,但很重要。曾经一度令人特别头疼的是它经常罢工,要么吃内存,要么假死不干活。它不干活,ES就得眼巴巴等数据而不得,ES没数据,历史日志就查不出内容,这个问题简直太严重了。经过反复排查分析,最终发现是由于action队列里的消息出队太慢导致的,在对rsyslog的队列配置反复做了几次调整后,这家伙终于肯乖乖干活了,好开心。有时候并不是现成的工具不好用,而是我们不会用。
ES索引介绍
ES存储离不开索引,最初我们的索引是按照天的粒度来创建的,一天一个索引,例如:index-log-2019-10-21。但是随着日志量的增加,按天索引,每次查询时,搜索范围太大,会导致一次查询特别慢,用户体验非常不好。为了提升查询效率,后来就把索引改成了小时粒度,例如:index-log-2019-10-21-13。
索引时间如何确定
看完ES索引介绍,有人可能会有疑惑,既然是按时间索引,这个时间具体是怎么取的呢?从用户的日志消息中解析的吗?不是的。用户的日志,时间格式各不相同,从用户日志中解析时间显然是不现实的。
难道是按照当前的搬运时间来确定索引?这样的话,在数据处理不及时,kafka消息有积压的情况下,用户日志中的时间和索引的时间就很可能不一致了呀,比如15点的数据,可能会放到16点的索引中,这样在搜索15点的数据的时候是搜不到期望的数据的。
这里要说明一下,我们log-agent采集的每条数据,除了日志内容外,都会带有一些元信息,比如部门名称、应用名、日志文件路径,time时间戳等,这里的时间戳记录的是日志采集时的时间,由于是实时采集,这个时间和用户应用日志中的时间可以看作是几乎相等的。在索引数据前,先解析出time时间戳,通过这个时间戳来确定具体的索引。这样即使在kafka消息有积压的情况下,也能保证日志数据可以正确存放到期望的索引中。
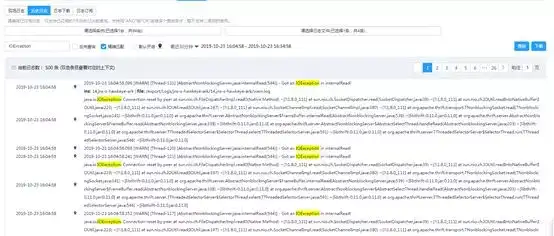
历史日志查询示例图
历史日志面临的问题
随着日志量的增多,有一个比较尴尬的问题,就是ES存储资源会出现不足的情况。这是一个需要我们和用户一起努力来解决的问题。
场景三:有的用户觉得自己应用的日志比较重要,希望能够长久保留,比如三个月、半年……当突然需要某天的数据了,可以通过日志服务将数据文件下载下来进行查看。
针对这个用户需求,我们的做法是将用户的日志按照日期进行存储,然后在前端页面提供日志下载功能,供用户根据需要进行查询和下载指定日期的的日志文件。这里我们抽象出的功能叫日志下载。
日志下载功能的实现思路
日志下载的前提和核心是将零散的日志信息合并到文件进行长久存储。
之前我们将采集到的数据存放到了kafka,数据源有了,接下来就是把数据拉下来进行合并存储的问题了。对,期初我们选择的存储介质是HDFS(ES是检索利器,且存储成本太高,用做长久存储显然是不现实的)。
为此,我们写了一个Spark job的程序,起了一个consumerGroup从kafka消费数据,由于对实时性要求不高,我们用Spark Streaming的方式,每隔两分钟,进行一次数据拉取,然后进行离线计算。由于一条消息的元数据中包含采集时间戳和日志路径,我们很容易确定一条日志该追加到哪个HDFS文件中。最终通过httpfs从hdfs下载日志文件。
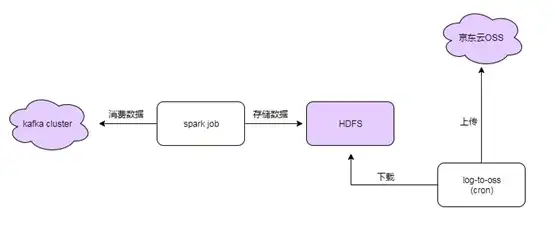
用HDFS作为存储,随着日志量的增加,资源不足的问题便呈现出来了。最终,我们把存储目标锁定到了京东云的对象存储OSS。当然了,初期的将数据计算后存储到HDFS的工作还是很有用的,接下来的工作就是把HDFS上的文件下载导入到OSS,然后生成OSS下载链接提供给用户就好了。这样HDFS相当于中转的作用,文件不需要保留太久,只要确定数据已经转存到OSS,HDFS上的文件就可以删除了,这样大大缓解了HDFS的存储压力。
日志转存(HDFS->OSS)遇到的问题及解决办法
在做日志转存至OSS的时候,我们遇到一个问题,比如用户的日志文件比较大,用户可能在自己的主机上做了日志切割,但是由于我们把数据采集后,变成了kafka中一条条的日志消息,我们相当于再把这一条条的日志消息重新合并到一个HDFS文件中。把一天的日志合到一个文件进行存储,有的应用日志打印比较频繁的话,最终合成的这个文件就会比较大,有的甚至超过了100G,这样不管是从HDFS进行下载和还是压缩上传至OSS操作都会比较耗时,而且磁盘空间占用也比较多。对于用户来说,下载一个大文件进行处理也会是一件比较头疼的事情。
为了解决这个问题,我们调整了spark job处理逻辑,实现了HDFS文件切割,确保单个HDFS文件大小不超过1G。这样一个大文件就被拆分成了多个小文件。对多个小文件进行并发转存,这样整体效率就大大提升了。压缩后的文件,一般不超过300MB,这样用户下载也会快很多。
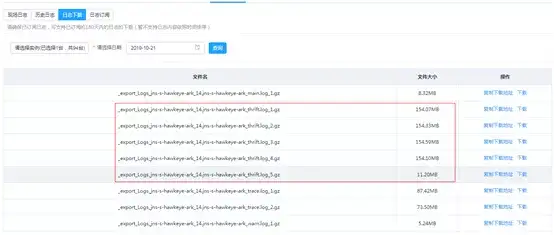
日志下载功能示例图
OSS做持久化存储后,有一个缺点,就是由于需要转存,无法实时下载当天的日志,不过这并不是一个特别急迫的问题,因为当天的日志完全可以通过前面介绍的现场日志查询或历史日志查询功能来进行检索查看。
场景四:特定存储需求 - 用户说,我的日志数据不想交给你做集中存储,我想自己保存,然后用来做分析,你帮我收集到指定地方就好了。
这确实是比较典型的用户需求,为了满足用户的这个需求,我们开发了自定义日志目的地的功能。
自定义日志目的地,顾名思义,就是让用户自己来指定将日志存放到哪里,然后用户在做订阅操作的时候,指定这个目的地名称即可。
目前支持的日志目的地有两种类型:fwd和kafka。
- fwd类型,要求提供目的地服务的域名和端口号,且目的地服务支持RELP协议,RELP是一种比TCP更可靠的传输协议。
- kafka类型,需要指定kafka的broker和topic。
从使用情况来看,目前kafka类型的日志目的地占绝大多数。
至此,云翼日志服务的几个主要功能就介绍完了。从整个过程看,日志服务是连接运维和开发之间很好的桥梁,日志中几乎包含了运维和开发所关心的一切,也完整呈现出了应用程序在线上真实的运行情况。云翼的现场日志查询、历史日志查询、日志下载、自定义日志目的地这四个功能互相补充,可以满足用户在不同场景下的使用诉求。
目前京东云监控提供免费服务,点击【阅读】,了解更多关于京东云监控的内容。
欢迎点击“京东云”了解更多精彩内容