
简介: 鉴于有很多企业都无法配备专门的团队来解决 Flink SQL 平台化的问题,那么到底有没有一个开源的、开箱即用的、功能相对完善的组件呢?答案就是本文的主角——Apache Zeppelin。
作者:LittleMagic
大数据领域 SQL 化开发的风潮方兴未艾(所谓"Everybody knows SQL"),Flink 自然也不能“免俗”。Flink SQL 是 Flink 系统内部最高级别的 API,也是流批一体思想的集大成者。用户可以通过简单明了的 SQL 语句像查表一样执行流任务或批任务,屏蔽了底层 DataStream/DataSet API 的复杂细节,降低了使用门槛。
但是,Flink SQL 的默认开发方式是通过 Java/Scala API 编写,与纯 SQL 化、平台化的目标相去甚远。目前官方提供的 Flink SQL Client 仅能在配备 Flink 客户端的本地使用,局限性很大。而 Ververica 开源的 Flink SQL Gateway 组件是基于 REST API 的,仍然需要二次开发才能供给上层使用,并不是很方便。
鉴于有很多企业都无法配备专门的团队来解决 Flink SQL 平台化的问题,那么到底有没有一个开源的、开箱即用的、功能相对完善的组件呢?答案就是本文的主角——Apache Zeppelin。
Flink SQL on Zeppelin!

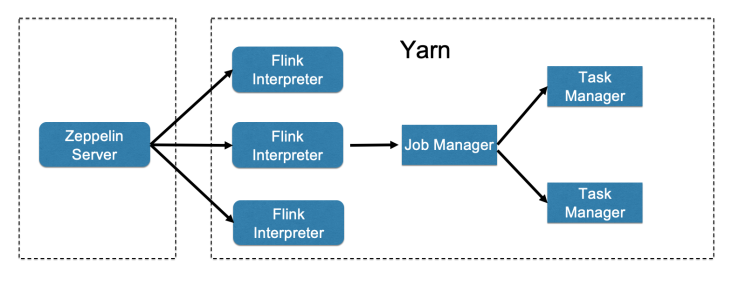
Zeppelin 是基于 Web 的交互式数据分析笔记本,支持 SQL、Scala、Python 等语言。Zeppelin 通过插件化的 Interpreter(解释器)来解析用户提交的代码,并将其转化到对应的后端(计算框架、数据库等)执行,灵活性很高。其架构简图如下所示。
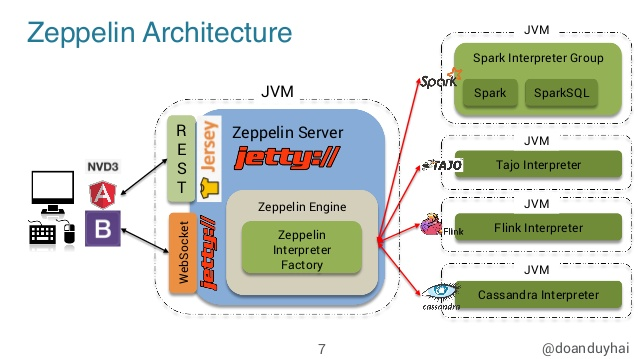
Flink Interpreter 就是 Zeppelin 原生支持的众多 Interpreters 之一。只要配置好 Flink Interpreter 以及相关的执行环境,我们就可以将 Zeppelin 用作 Flink SQL 作业的开发平台了(当然,Scala 和 Python 也是没问题的)。接下来本文就逐步介绍 Flink on Zeppelin 的集成方法。
配置 Zeppelin
目前 Zeppelin 的最新版本是 0.9.0-preview2,可以在官网下载包含所有 Interpreters 的 zeppelin-0.9.0-preview2-bin-all.tgz,并解压到服务器的合适位置。
接下来进入 conf 目录。将环境配置文件 zeppelin-env.sh.template 更名为 zeppelin-env.sh,并修改:
# JDK目录
export JAVA_HOME=/opt/jdk1.8.0_172
# 方便之后配置Interpreter on YARN模式。注意必须安装Hadoop,且hadoop必须配置在系统环境变量PATH中
export USE_HADOOP=true
# Hadoop配置文件目录
export HADOOP_CONF_DIR=/etc/hadoop/hadoop-conf
将服务配置文件 zeppelin-site.xml.template 更名为 zeppelin-site.xml,并修改:
<!-- 服务地址。默认为127.0.0.1,改为0.0.0.0使得可以在外部访问 -->
<property>
<name>zeppelin.server.addr</name>
<value>0.0.0.0</value>
<description>Server binding address</description>
</property>
<!-- 服务端口。默认为8080,如果已占用,可以修改之 -->
<property>
<name>zeppelin.server.port</name>
<value>18080</value>
<description>Server port.</description>
</property>
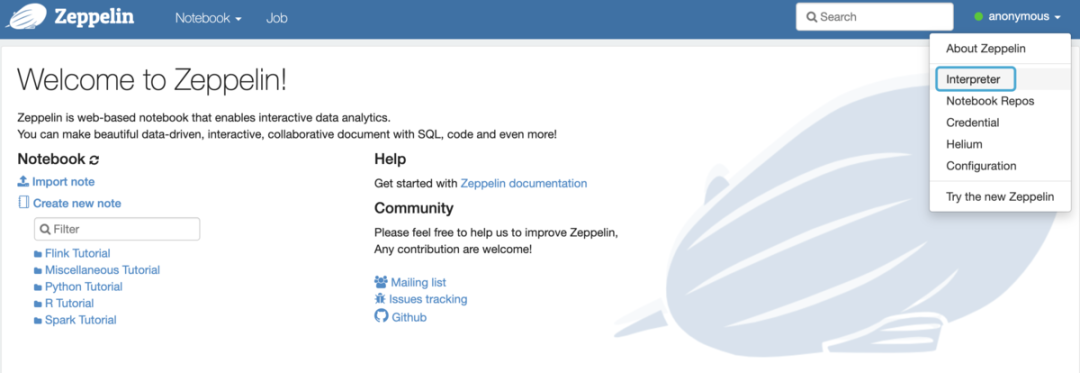
最基础的配置就完成了。运行 bin/zeppelin-daemon.sh start 命令,返回 Zeppelin start [ OK ]的提示之后,访问<服务器地址>:18080,出现下面的页面,就表示 Zeppelin 服务启动成功。
当然,为了一步到位适应生产环境,也可以适当修改 zeppelin-site.xml 中的以下参数:
<!-- 将Notebook repo更改为HDFS存储 -->
<property>
<name>zeppelin.notebook.storage</name>
<value>org.apache.zeppelin.notebook.repo.FileSystemNotebookRepo</value>
<description>Hadoop compatible file system notebook persistence layer implementation, such as local file system, hdfs, azure wasb, s3 and etc.</description>
</property>
<!-- Notebook在HDFS上的存储路径 -->
<property>
<name>zeppelin.notebook.dir</name>
<value>/zeppelin/notebook</value>
<description>path or URI for notebook persist</description>
</property>
<!-- 启用Zeppelin的恢复功能。当Zeppelin服务挂掉并重启之后,能连接到原来运行的Interpreter -->
<property>
<name>zeppelin.recovery.storage.class</name>
<value>org.apache.zeppelin.interpreter.recovery.FileSystemRecoveryStorage</value>
<description>ReoveryStorage implementation based on hadoop FileSystem</description>
</property>
<!-- Zeppelin恢复元数据在HDFS上的存储路径 -->
<property>
<name>zeppelin.recovery.dir</name>
<value>/zeppelin/recovery</value>
<description>Location where recovery metadata is stored</description>
</property>
<!-- 禁止使用匿名用户 -->
<property>
<name>zeppelin.anonymous.allowed</name>
<value>true</value>
<description>Anonymous user allowed by default</description>
</property>
Zeppelin 集成了 Shiro 实现权限管理。禁止使用匿名用户之后,可以在 conf 目录下的 shiro.ini 中配置用户名、密码、角色等,不再赘述。注意每次修改配置都需要运行 bin/zeppelin-daemon.sh restart 重启 Zeppelin 服务。
配置 Flink Interpreter on YARN
在使用 Flink Interpreter 之前,我们有必要对它进行配置,使 Flink 作业和 Interpreter 本身在 YARN 环境中运行。
点击首页用户名区域菜单中的 Interpreter 项(上一节图中已经示出),搜索 Flink,就可以看到参数列表。
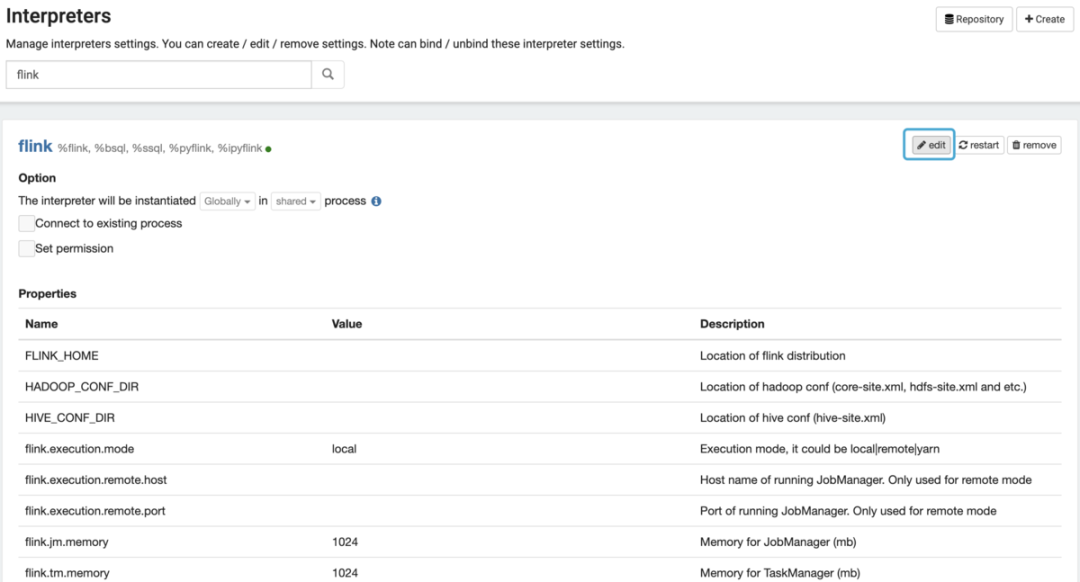
Interpreter Binding
首先,将 Interpreter Binding 模式修改为 Isolated per Note,如下图所示。
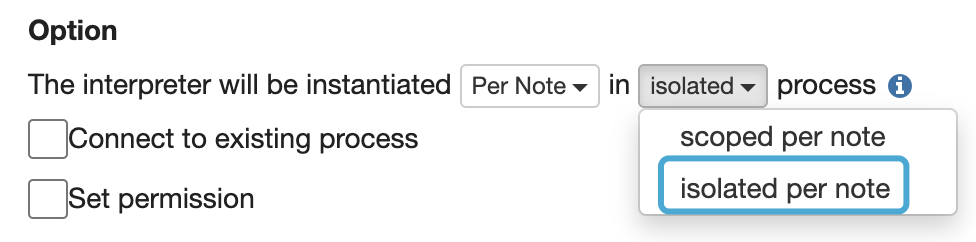
在这种模式下,每个 Note 在执行时会分别启动 Interpreter 进程,类似于 Flink on YARN 的 Per-job 模式,最符合生产环境的需要。
Flink on YARN 参数
以下是需要修改的部分基础参数。注意这些参数也可以在 Note 中指定,每个作业自己的配置会覆盖掉这里的默认配置。
- FLINK_HOME:Flink 1.11所在的目录;
- HADOOP_CONF_DIR:Hadoop 配置文件所在的目录;
- flink.execution.mode:Flink 作业的执行模式,指定为 YARN 以启用 Flink on YARN;
- flink.jm.memory:JobManager 的内存量(MB);
- flink.tm.memory:TaskManager 的内存量(MB);
- flink.tm.slot:TaskManager 的 Slot 数;
- flink.yarn.appName:YARN Application 的默认名称;
- flink.yarn.queue:提交作业的默认 YARN 队列。
Hive Integration 参数
如果我们想访问 Hive 数据,以及用 HiveCatalog 管理 Flink SQL 的元数据,还需要配置与 Hive 的集成。
- HIVE_CONF_DIR:Hive 配置文件(hive-site.xml)所在的目录;
- zeppelin.flink.enableHive:设为 true 以启用 Hive Integration;
- zeppelin.flink.hive.version:Hive 版本号。
- 复制与 Hive Integration 相关的依赖到 $FLINK_HOME/lib 目录下,包括:
- flink-connector-hive_2.11-1.11.0.jar
- flink-hadoop-compatibility_2.11-1.11.0.jar
- hive-exec-..jar
- 如果 Hive 版本是1.x,还需要额外加入 hive-metastore-1.*.jar、libfb303-0.9.2.jar 和 libthrift-0.9.2.jar
- 保证 Hive 元数据服务(Metastore)启动。注意不能是 Embedded 模式,即必须以外部数据库(MySQL、Postgres等)作为元数据存储。
Interpreter on YARN 参数
在默认情况下,Interpreter 进程是在部署 Zeppelin 服务的节点上启动的。随着提交的任务越来越多,就会出现单点问题。因此我们需要让 Interpreter 也在 YARN 上运行,如下图所示。
- zeppelin.interpreter.yarn.resource.cores:Interpreter Container 占用的vCore 数量;
- zeppelin.interpreter.yarn.resource.memory:Interpreter Container 占用的内存量(MB);
- zeppelin.interpreter.yarn.queue:Interpreter 所处的 YARN 队列名称。
配置完成之后,Flink on Zeppelin 集成完毕,可以测试一下了。
测试 Flink SQL on Zeppelin
创建一个 Note,Interpreter 指定为 Flink。然后写入第一个 Paragraph:

以 %flink.conf 标记的 Paragraph 用于指定这个 Note 中的作业配置,支持 Flink 的所有配置参数(参见 Flink 官网)。另外,flink.execution.packages 参数支持以 Maven GAV 坐标的方式引入外部依赖项。
接下来创建第二个 Paragraph,创建 Kafka 流表:

%flink.ssql 表示利用 StreamTableEnvironment 执行流处理 SQL,相对地,%flink.bsql 表示利用 BatchTableEnvironment 执行批处理 SQL。注意表参数中的 properties.bootstrap.servers 利用了 Zeppelin Credentials 来填写,方便不同作业之间复用。
执行上述 SQL 之后会输出信息:

同时在 Hive 中可以看到该表的元数据。
最后写第三个 Paragraph,从流表中查询,并实时展现出来:
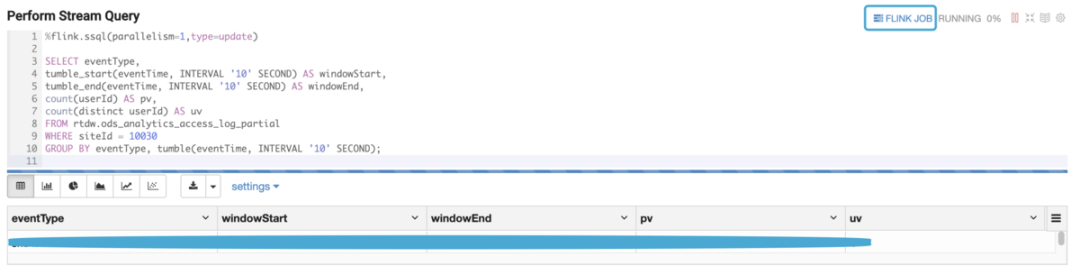
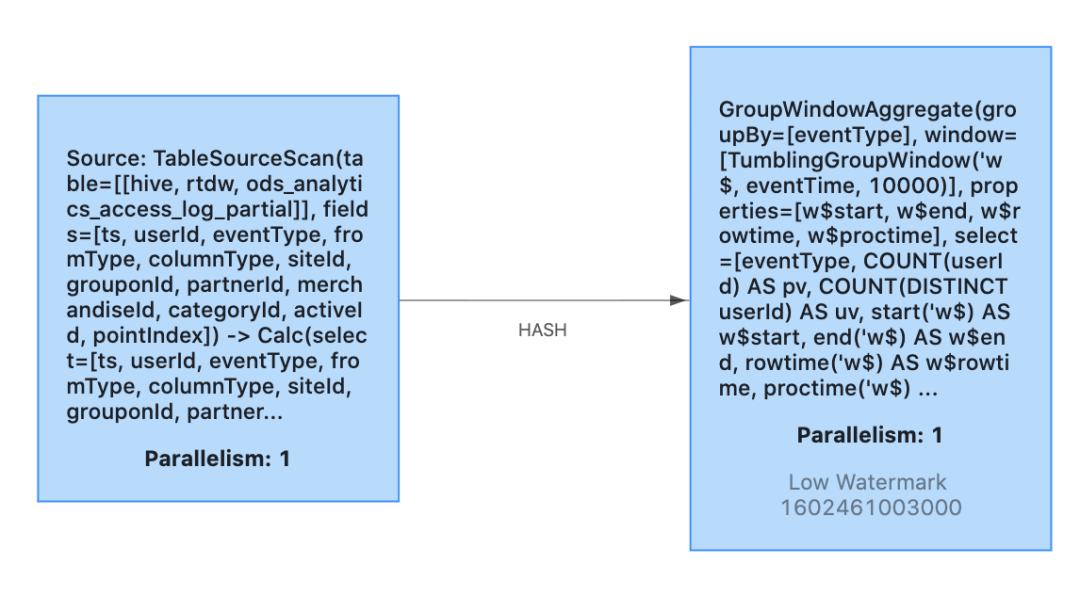
点击右上角的 FLINK JOB 标记,可以打开作业的 Web UI。上述作业的 JobGraph 如下。
除 SELECT 查询外,通过 Zeppelin 也可以执行 INSERT 查询,实现更加丰富的功能。关于 Flink SQL on Zeppelin 的更多应用,笔者在今后的文章中会继续讲解。
原文链接
本文为阿里云原创内容,未经允许不得转载。











