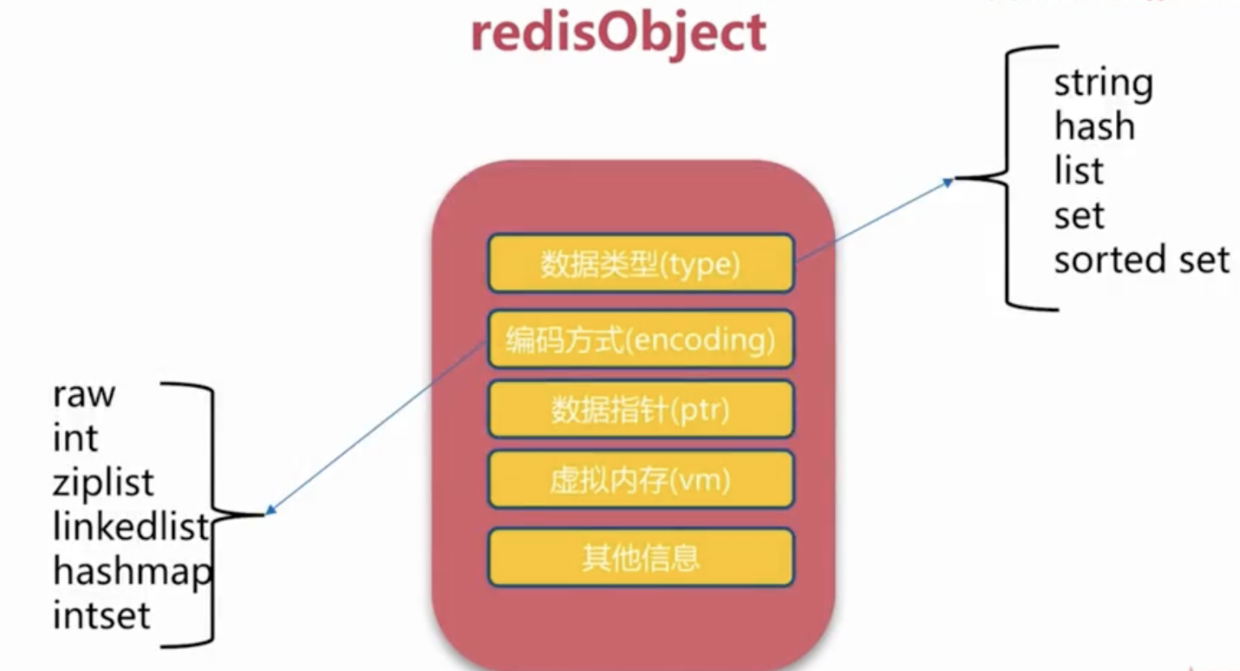
Set针对复杂对象去重问题
在项目中我们经常使用set,因其可以去重特性,平时使用较多的是基础数据类型,Set
创建的对象去覆盖set中type相同的对象,于是想到Set这个集合类型,并且重写了自定义对象的equals()和hashCode()方法,但调试阶段发现结果并非所想。
以下代码是自定义的Bean:
@AllArgsConstructor
@ToString
public class Foo implements Serializable {
private static final long serialVersionUID = -3968061057233768716L;
@Getter
@Setter
private int type;
@Getter
@Setter
private String name;
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Foo foo = (Foo) o;
return type == foo.type;
}
@Override
public int hashCode() {
return Objects.hash(type);
}
}
接下来写个单元测试吧
public class SetTest {
@Test
public void test1() {
Set<Foo> set = new HashSet<>();
Foo foo = new Foo(1, "1");
set.add(foo);
foo = new Foo(2, "2");
set.add(foo);
foo = new Foo(1, "3");
set.add(foo);
// 输出结果是什么
System.out.println("set = " + set);
}
第一感觉会输出什么,set.size()=2是毫无疑问的,重点是type=1的对象对应的name是1还是3?当时我用脑子意想出来的name=3。可能会有童鞋认为输出的结果name=1,恭喜你答对了,确实
是name=1。
set = [Foo(type=1, name=1), Foo(type=2, name=2)]
为什么不是3呢,3呢,3呢?接下来我们分析下,我们都知道当我们向HashMap中放入相同key和不同val放入到map中,map会保留最新的val(hashMap源码分析网上有很多解析,这里不再赘
述了,自行Google下),可见map其实也是保证key唯一的,不会出现key对应多个val的值(限:jdk中自带HashMap,Guava中Multimap是可以key对应多个val的,get(key)时返回的是val的集
合),HashSet就是利用HashMap中key唯一不重复的特性来实现的。
jdk1.8源码
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
-----------add部分 begin--------------------
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element <tt>e</tt> to this set if
* this set contains no element <tt>e2</tt> such that
* <tt>(e==null ? e2==null : e.equals(e2))</tt>.
* If this set already contains the element, the call leaves the set
* unchanged and returns <tt>false</tt>.
*
* @param e element to be added to this set
* @return <tt>true</tt> if this set did not already contain the specified
* element
*/
// 其实这里是有返回值的
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
-----------add部分 end--------------------
调用add()实际就是调用HashMap的put方法,注意此时put的val是固定式<font color="red">**PRESENT**</font>是final修饰的一个对象,针对所有key都一样,因为我们是set所有val对我们来说没啥用。但是我们注意到其
实add()方法是有返回值的,当调用map.put()方法返回的对象是null的时候则代表新增成功,set中以前不存在此元素。当返回的对象not null的时候代表set中有此对象,而我们关注的其实只是key,
并不关注这个val。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
-----------
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 重点在这里
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 当我们第二次加入type=1时代码肯定就走到了这里,return oldValue其实也就是returun我们传入的PRESENT not nul
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
重点在这里
重点在这里
重点在这里
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
hash相等是肯定的,因为我们重写了Foo对象的hashCode方法,只跟type有关,所有p.hash==hash为true,大括号中(k = p.key) == key部门为false因为对象地址不同,但是
key != null && key.equals(k)是为true的,因为重写了equals()方法也只跟type有关,都为1,所以e = p了,流程判断语句结束,return一个not null的value。其实putVal()流程控制来看,只要我们的key
是存在的都会返回一个not null的val,而新插入的key返回值都是null。
代码调试截图走一波
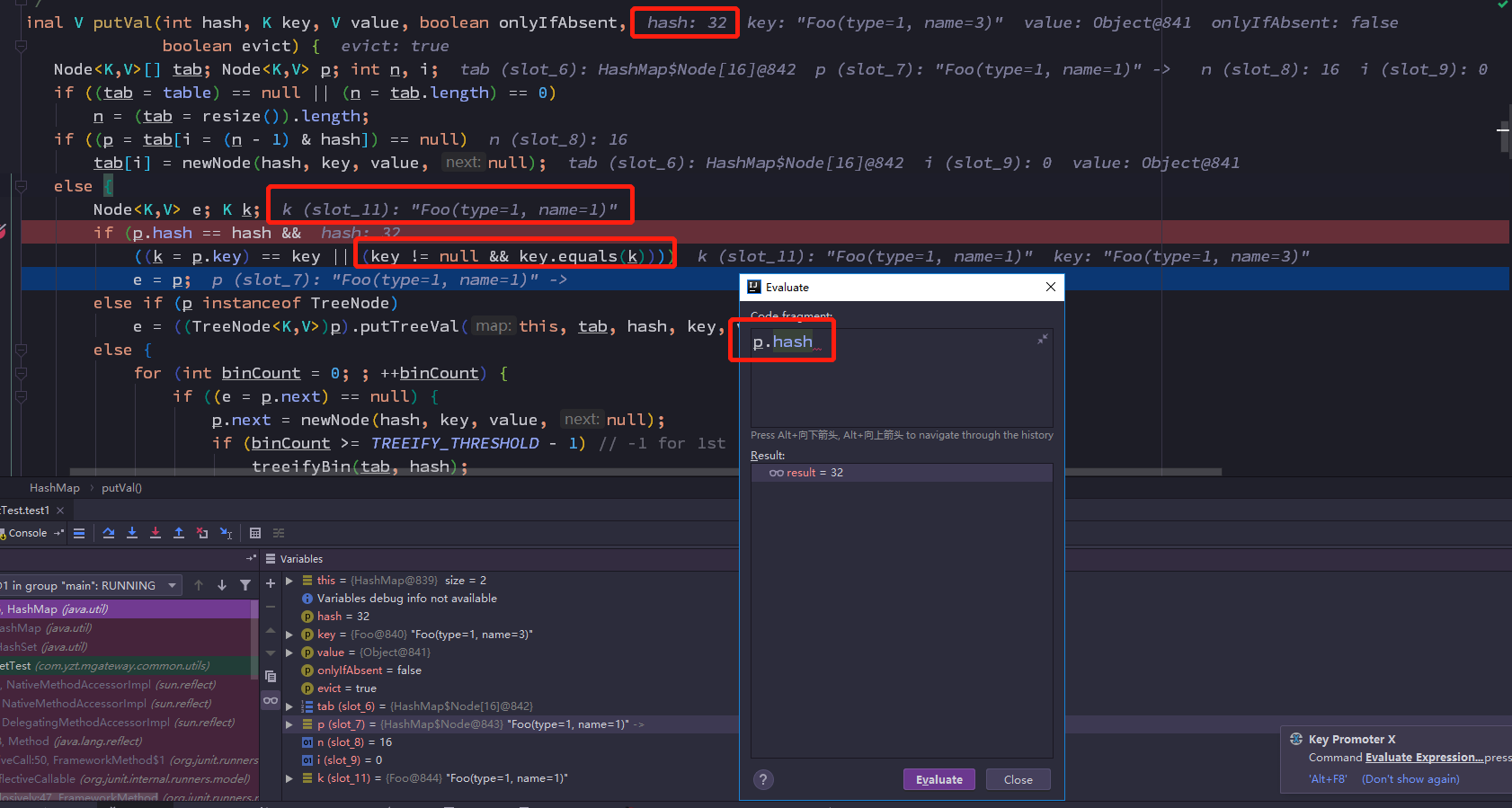
最后没办法先remove()后add()。。。
注:代码中使用了lombok插件,非常好用哈哈,墙裂推荐。一个@Data搞定所有,不要告诉我idea代码自动生成,想一下,当你开发代码时给对象增加一个属性是不是还要给新属性生成get和set方法,还要toString()是不是也要改,而你加了@Data属性,这些都不需要考虑了。