
因为之前使用redis一般都只做热数据处理,没有考虑过落地方案,因此,通过很多次不同的交流,发现落地也挺重要的,特来学习一般。
落地策略
我们知道,redis是纯内存数据库,一旦发生宕机,数据就会丢失,因此,Redis 的落地策略其实就是持久化(Persistence),主要有以下2种策略:
- RDB: 定时快照方式(snapshot)
- AOF: 基于语句追加文件的方式
RDB
RDB 文件非常紧凑,它保存了 Redis 某个时间点上的数据集。RDB 恢复大数据集时速度要比 AOF 快。但是 RDB 不适合那些对时效性要求很高的业务,因为它只保存了快照,在进行恢复时会导致一些时间内的数据丢失。实际在进行备份时,Redis 主要依靠 rdbSave() 函数,然后有两个命令会调用这个函数 SAVE 和 BGSAVE,前者会同步调用,阻塞主进程导致会有短暂的 Redis-server 停止工作,后者会 fork 出子进程异步处理。
在调用 SAVE 或者 BGSAVE 时,只有发布和订阅功能的命令可以正常执行,因为这个模块和服务器的其他模块是隔离的。 下面的命令表示: “60 秒内有至少有 1000 个键被改动”时进行RDB文件备份。
redis-server> SAVE 60 1000
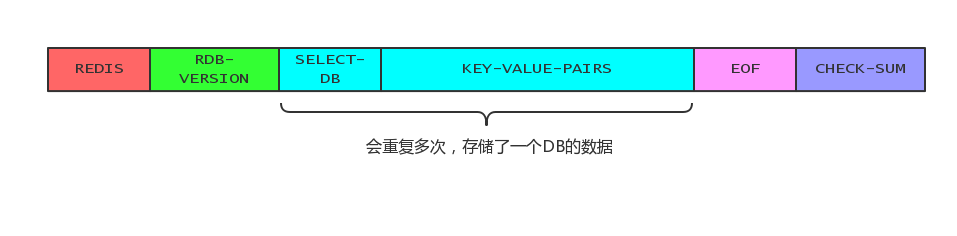
开头的REDIS表示这是一个 RDB 文件,然后紧跟着 redis 的版本号,SELECT-DB 和 KEY-VALUES-PAIRS 构成了对一个数据库中的所有数据记录,其中 KEY-VALUES-PAIRS 具体结构如下,后面两个就不用说了。

AOF
AOF 可以通过设置的 fsync 策略配置,如果未设置 fsync ,AOF 的默认策略为每秒钟 fsync 一次,在这种配置下, fsync 会在后台线程执行,所以主线程不会受到打扰。但是像 AOF 这种策略会导致追加的文件非常大,而且在恢复大数据时非常缓慢,因为要把所有会导致写数据库的命令都重新执行一遍。AOF文件中实际存储的是 Redis 协议下的命令记录,因此非常易读。
当然 Redis 考虑到了 AOF 文件过大的问题,因此引入了 BGREWRITEAOF 命令进行重建 AOF 文件,保证可以减少大量无用的重复写操作。重建命令并不会去分析已有的 AOF 文件,而是将当前数据库的快照保存。
在 AOF 文件重写时,Redis 的具体逻辑如下:
- Redis 首先 fork 出一个子进程,子进程将新 AOF 文件的内容写入到临时文件。
- 对于所有新执行的写入命令,父进程一边将它们累积到一个缓存中,一边将这些改动追加到现有 AOF 文件的末尾: 这样即使在重写的中途发生停机,现有的 AOF 文件也还是安全的。
- 当子进程完成重写工作时,它给父进程发送一个信号,父进程在接收到信号之后,将缓存中的所有数据追加到新 AOF 文件的末尾。
- 现在 Redis 原子地用新文件替换旧文件,之后所有命令都会直接追加到新 AOF 文件的末尾。
Redis 会维持一个默认的AOF重写策略,当当前的AOF文件比上次重写之后的文件大小增大了一倍时,就会自动在后台重写AOF。
从策略方式来看,AOF文件模式类似于mysql的binlog,是做一个归档日志,属于逻辑日志。
AOF与RDB的优缺点和适用场景
RDB持久化是在指定的时间间隔内将内存中的数据集快照写入磁盘中,fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。具体操作:遍历hash table,利用copy on write,把整个db dump保存下来。save, shutdown, slave 命令会触发这个操作。
特点:粒度比较大,如果save, shutdown, slave 之前crash了,则中间的操作没办法恢复。
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。Redis 还可以在后台对 AOF 文件进行重写(rewrite),使得 AOF 文件的体积不会超出保存数据集状态所需的实际大小。Redis 还可以同时使用 AOF 持久化和 RDB 持久化。 在这种情况下, 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。你甚至可以关闭持久化功能,让数据只在服务器运行时存在。
特点:粒度较小,crash之后,只有crash之前没有来得及做日志的操作没办法恢复。
选择的标准,就是看系统是愿意牺牲一些性能,换取更高的缓存一致性(aof),还是愿意写操作频繁的时候,不启用备份来换取更高的性能,待手动运行save的时候,再做备份(rdb)。rdb这个就更有些 eventually consistent的意思了。










