
一、介绍
TxtFileReader提供了读取本地文件系统数据存储的能力。在底层实现上,TxtFileReader获取本地文件数据,并转换为DataX传输协议传递给Writer。
二、配置模版
{
"setting": {},
"job": {
"setting": {
"speed": {
"channel": 2
}
},
"content": [
{
"reader": {
"name": "txtfilereader",
"parameter": {
"path": ["/home/haiwei.luo/case00/data"],
"encoding": "UTF-8",
"column": [
{
"index": 0,
"type": "long"
},
{
"index": 1,
"type": "boolean"
},
{
"index": 2,
"type": "double"
},
{
"index": 3,
"type": "string"
},
{
"index": 4,
"type": "date",
"format": "yyyy.MM.dd"
}
],
"fieldDelimiter": ","
}
},
"writer": {
"name": "txtfilewriter",
"parameter": {
"path": "/home/haiwei.luo/case00/result",
"fileName": "luohw",
"writeMode": "truncate",
"format": "yyyy-MM-dd"
}
}
}
]
}
}
三、使用说明
支持且仅支持读取TXT的文件,且要求TXT中shema为一张二维表。
支持类CSV格式文件,自定义分隔符。
支持多种类型数据读取(使用String表示),支持列裁剪,支持列常量
四、实践
最近需要导一张表,原来的表数据是存放在hive上的,利用python脚本处理数据之后直接插入到hive的。现在是要将这张表的数据导入到greenplum中。表数据在7200万左右
方法:将hive数据导出成csv文件,利用datax导入到greenplum

开干:
配置json文件
{
"content":[
{
"reader":{
"name":"txtfilereader",
"parameter":{
"column":[
{
"format":"yyyy-MM-dd",
"index":0,
"type":"date"
},
{
"index":1,
"type":"string"
},
{
"index":2,
"type":"string"
},
{
"index":3,
"type":"string"
},
{
"index":4,
"type":"string"
},
{
"index":5,
"type":"long"
},
{
"index":6,
"type":"long"
},
{
"index":7,
"type":"long"
},
{
"index":8,
"type":"long"
}
],
"encoding":"utf-8",
"fieldDelimiter":",",
"path":[
"/home/tianyafu/flux_timecount_action.csv"
]
}
},
"writer":{
"name":"gpdbwriter",
"parameter":{
"column":[
"record_date",
"outid",
"tm_type",
"serv",
"app",
"down_flux",
"up_flux",
"seconds",
"count"
],
"connection":[
{
"jdbcUrl":"jdbc:postgresql://192.168.100.21:5432/ods",
"table":[
"ods_flux_timecount_action"
]
}
],
"password":"******",
"segment_reject_limit":0,
"username":"admin"
}
}
}
],
"setting":{
"errorLimit":{
"percentage":0.02,
"record":0
},
"speed":{
"channel":"1"
}
}
}
然后就失败了呀
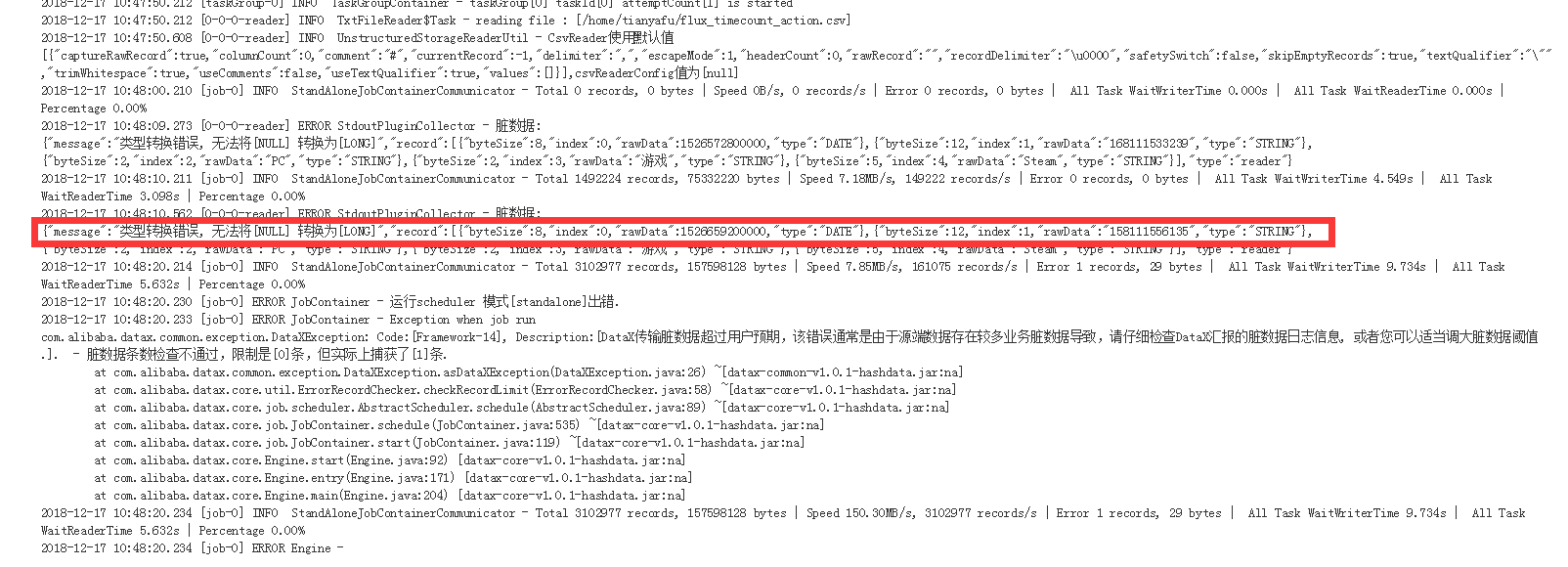
确定错误是数据中有null值,无法转换为Long类型。
查询到解决方法是添加:
nullFormat配置项
nullFormat
描述:文本文件中无法使用标准字符串定义null(空指针),DataX提供nullFormat定义哪些字符串可以表示为null。
例如如果用户配置: nullFormat:"\N",那么如果源头数据是"\N",DataX视作null字段。
必选:否
默认值:\N
那就加上呗,
{
"content":[
{
"reader":{
"name":"txtfilereader",
"parameter":{
"column":[
{
"format":"yyyy-MM-dd",
"index":0,
"type":"date"
},
{
"index":1,
"type":"string"
},
{
"index":2,
"type":"string"
},
{
"index":3,
"type":"string"
},
{
"index":4,
"type":"string"
},
{
"index":5,
"type":"long"
},
{
"index":6,
"type":"long"
},
{
"index":7,
"type":"long"
},
{
"index":8,
"type":"long"
}
],
"csvReaderConfig":{
"safetySwitch":false,
"skipEmptyRecords":false,
"useTextQualifier":false
},
"encoding":"utf-8",
"fieldDelimiter":",",
"nullFormat":"null",
"path":[
"/home/tianyafu/flux_timecount_action.csv"
]
}
},
"writer":{
"name":"gpdbwriter",
"parameter":{
"column":[
"record_date",
"outid",
"tm_type",
"serv",
"app",
"down_flux",
"up_flux",
"seconds",
"count"
],
"connection":[
{
"jdbcUrl":"jdbc:postgresql://192.168.100.21:5432/ods",
"table":[
"ods_flux_timecount_action"
]
}
],
"password":"******",
"segment_reject_limit":0,
"username":"admin"
}
}
}
],
"setting":{
"errorLimit":{
"percentage":0.02,
"record":0
},
"speed":{
"channel":"1"
}
}
}
结果又失败了

看来是大小写敏感的,继续改:
{
"content":[
{
"reader":{
"name":"txtfilereader",
"parameter":{
"column":[
{
"format":"yyyy-MM-dd",
"index":0,
"type":"date"
},
{
"index":1,
"type":"string"
},
{
"index":2,
"type":"string"
},
{
"index":3,
"type":"string"
},
{
"index":4,
"type":"string"
},
{
"index":5,
"type":"long"
},
{
"index":6,
"type":"long"
},
{
"index":7,
"type":"long"
},
{
"index":8,
"type":"long"
}
],
"csvReaderConfig":{
"safetySwitch":false,
"skipEmptyRecords":false,
"useTextQualifier":false
},
"encoding":"utf-8",
"fieldDelimiter":",",
"nullFormat":"NULL",
"path":[
"/home/tianyafu/flux_timecount_action.csv"
]
}
},
"writer":{
"name":"gpdbwriter",
"parameter":{
"column":[
"record_date",
"outid",
"tm_type",
"serv",
"app",
"down_flux",
"up_flux",
"seconds",
"count"
],
"connection":[
{
"jdbcUrl":"jdbc:postgresql://192.168.100.21:5432/ods",
"table":[
"ods_flux_timecount_action"
]
}
],
"password":"******",
"segment_reject_limit":0,
"username":"admin"
}
}
}
],
"setting":{
"errorLimit":{
"percentage":0.02,
"record":0
},
"speed":{
"channel":"1"
}
}
}

终于成功了
看来这个参数是大小写敏感的











