今天终于定方向啦。 开始做常识了。我太难了,研一上摸鱼半学期,啥都整过,啥都是一知半解。不过也好,了解了很多其他领域的东西。现在定方向了,但是又只能待在家里学。。。。
这是我该方向看的第一篇paper,和我没看之前的想法,竟然有些类似。
正文:
这篇paper巧妙的利用了语言模型,极度简单且高效的解决了问题。将代词用选项替换,判断替换后的句子哪个句子的概率高,巧妙地解决了共指消歧和 Winograd Schema Challenge 问题。非常符合我们的常识和理解,所以也达到了非常好的效果。而且这个办法可以在无监督的语料上进行。 简单有效,好论文。
如果对语言模型不明白的可以看我之前的一篇文章,或者百度谷歌一下。
论文评估了两种可能性:
假设代词在第k个位置。wk ← c 代表第k个token用选项c替代。
• Scorefull(wk ← c) = Pθ(w1, w2, ..., wk−1, c, wk+1, ..., wn)
即考虑整个句子生成的概率
• Scorepartial(wk ← c) = Pθ(wk+1, ..., wn|w1, ..., wk−1, c)
考虑在更改代词为c后,后面句子生成的概率。

文章还同时考虑了w为字级别和单词级别时候的效果。
效果
1.Pronoun Disambiguation Problems
可以看出 word级别的token表现得更好,PDP问题中,word-lm-full模型的表现要大幅度优于word-lm-partial。
原因,我还没想明白。以后在补充

这里是 使用额外4个无监督数据集(LM-1-Billion, CommonCrawl, SQuAD, Gutenberg Books)训练(共五个),并且将他们的实验结果融合得到的结果。可以看出,最高可以达到70acc,比之前高了10个点,这点很容易理解,毕竟训练的数据多了,模型可以更好地学习。
2.Winograd Schema Challenge
在WSC问题中 partial的效果反而要由于full。 这里和以上一样只不过使用的是partial模型在四个无监督数据集上进行训练,同时融合了上面的五个模型,共十个模型。acc达到了61.5~~~~
2.1 ‘定做‘的数据集
在CommonCrawl上收集与问题相似的数据,在该数据集上进行训练。
相似是按照重合的n-gram来计算的,公式如下: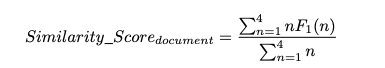
单数据集就超过了之前十个模型的融合,融合以后高了2.2个准确度(63.7)。