
线上服务内存溢出
这周刚上班突然有一个项目内存溢出了,排查了半天终于找到问题所在,在此记录下,防止后面再次出现类似的情况。
先简单说下当出现内存溢出之后,我是如何排查的,首先通过jstack打印出堆栈信息,然后通过分析工具对这些文件进行分析,根据分析结果我们就可以知道大概是由于什么问题引起的。
关于jstack如何使用,大家可以先看看这篇文章 jstack的使用
问题排查
下面是我打印出来的信息,大部分都是这个
"http-nio-8761-exec-124" #580 daemon prio=5 os_prio=0 tid=0x00007fbd980c0800 nid=0x249 waiting on condition [0x00007fbcf09c8000] java.lang.Thread.State: TIMED_WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000000f73a4508> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078) at java.util.concurrent.LinkedBlockingQueue.poll(LinkedBlockingQueue.java:467) at org.apache.tomcat.util.threads.TaskQueue.poll(TaskQueue.java:85) at org.apache.tomcat.util.threads.TaskQueue.poll(TaskQueue.java:31) at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1073) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) at java.lang.Thread.run(Thread.java:748)
看到了如上信息之后,大概可以看出是由于线程池的使用不当导致的,那么根据信息继续往下看,看到ThreadPoolExecutor那么就可以知道这肯定是创建了线程池,那么我们就在代码里找,哪里创建使用了线程池,我就找到这么一段代码。
`public class ThreadPool {
private static ExecutorService pool;
private static long logTime = 0;
public static ExecutorService getPool() {
if (pool == null) {
pool = Executors.newFixedThreadPool(20);
}
return pool;
}
}
`
乍一看,可能写的同学是想把这当一个全局的线程池用,所有的业务凡是用到线程的都会使用这个类,为了统一管理线程,想法没什么毛病,但是这样写确实有点子毛病。
newFixedThreadPool分析
上面使用了Executors.newFixedThreadPool(20)创建了一个固定的线程池,我们先分析下newFixedThreadPool是怎么样的一个流程。
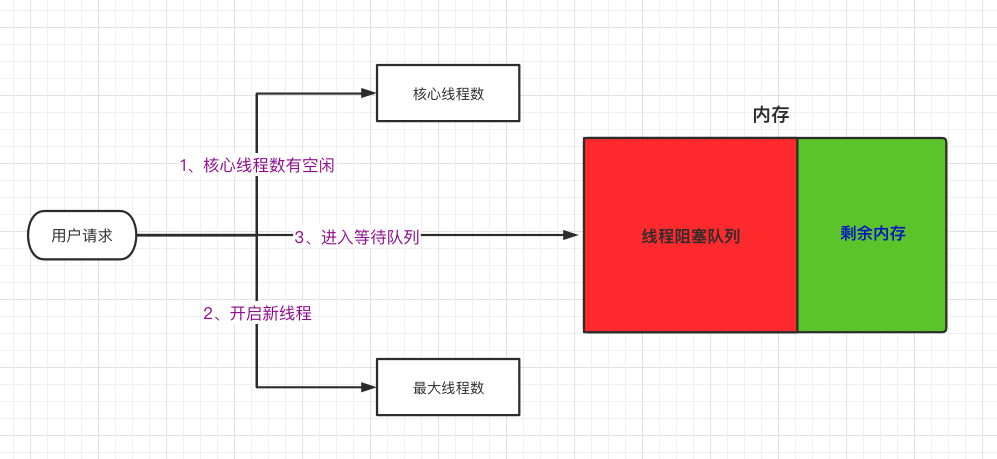
一个请求进来之后,如果核心线程有空闲线程直接使用核心线程中的线程执行任务,不会添加到阻塞队列中,如果核心线程满了,判断是否达到允许的最大线程数,如果没有继续则创建线程执行,直至达到允许的最大线程数,之后进入的请求如果没有空闲的线程,则进入阻塞队列,等待其他线程执行结束。
了解了流程之后我们再来看newFixedThreadPool的代码实现。
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
public LinkedBlockingQueue() { this(Integer.MAX_VALUE); }
public LinkedBlockingQueue(int capacity) { if (capacity <= 0) throw new IllegalArgumentException(); // 任务阻塞队列的初始容量 this.capacity = capacity; last = head = new Node<E>(null); }
定位问题
看到了这里不知道你是否知道了此次引起内存泄漏的原因,其实就是因为阻塞队列的容量过大。
如果不手动的指定阻塞队列的大小,那么它默认是Integer.MAX_VALUE,我们的线程池只有20个线程可以处理任务,其他的请求全部放到阻塞队列中,那么当涌入大量的请求之后,阻塞队列一直增加,你的内存配置又非常紧凑的话,那么是很容易出现内存溢出的。
我们的业务是在APP启动的时候,会使用线程池去检查用户的一些配置,应用的启动量还是非常大的而且给的内存配置也不是很足,所以运行一段时间后,部分容器就出现了内存溢出的情况。
如何正确的创建线程池
以前其实没太在意这种问题,都是使用Executors去创建线程,但是这样确实会存在一些问题,就像这些的内存泄漏,所以一般不要使用Executors去创建线程,使用ThreadPoolExecutor进行创建,其实Executors底层也是使用ThreadPoolExecutor进行创建的。
使用ThreadPoolExecutor创建需要自己指定核心线程数、最大线程数、线程的空闲时长以及阻塞队列。
3种阻塞队列
ArrayBlockingQueue:基于数组的先进先出队列,有界
LinkedBlockingQueue:基于链表的先进先出队列,有界
SynchronousQueue:无缓冲的等待队列,无界
我们使用了有界的队列,那么当队列满了之后如何处理后面进入的请求,我们可以通过不同的策略进行设置。
4种拒绝策略
AbortPolicy:默认,队列满了丢任务抛出异常
DiscardPolicy:队列满了丢任务不异常
DiscardOldestPolicy:将最早进入队列的任务删,之后再尝试加入队列
CallerRunsPolicy:如果添加到线程池失败,那么主线程会自己去执行该任务
在创建之前,先说下我最开始的版本,因为队列是固定的,最开始我们不知道有拒绝策略,所以在队列满了之后再添加的话会出现异常,我就在异常里面睡眠了1秒,等待其他的线程执行完毕获取空闲连接,但是还是会有部分不能得到执行。
接下来我们来创建一个容错率比较高的线程池。
`public class WordTest {
public static void main(String[] args) throws InterruptedException {
System.out.println("开始执行");
// 阻塞队列容量声明为100个
ThreadPoolExecutor executorService = new ThreadPoolExecutor(10, 10,
0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>(100));
// 设置拒绝策略
executorService.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
// 空闲队列存活时间
executorService.setKeepAliveTime(20, TimeUnit.SECONDS);
List
try {
// 模拟200个请求
for (int i = 0; i < 200; i++) {
final int num = i;
executorService.execute(() -> {
System.out.println(Thread.currentThread().getName() + "-结果:" + num);
list.add(num);
});
}
} finally {
executorService.shutdown();
executorService.awaitTermination(10, TimeUnit.SECONDS);
}
System.out.println("线程执行结束");
}
}
`
思路:我声明了100容量的阻塞队列,模拟了一个200的请求,很显然肯定有部分请求进入不了队列,但是我使用了CallerRunsPolicy策略,当队列满了之后,使用主线程去进行处理,这样就不会出现有部分请求得不到执行的情况,也不会因为因为阻塞队列过大导致内存溢出的情况。
如果还有什么更好地写法欢迎各位指教!
通过测试200个请求全部得到执行,有3个请求由主线程进行了处理。
总结
如何更好的创建线程池上面已经说过了,关于线程池在业务中的使用,其实我们这种全局的思路是不太好的,因为如果从全局考虑去创建线程池,是很难把控的,因为你无法准确地评估所有的请求加起来会有多大的量,所以最好是每个业务创建独立的线程池进行处理,这样是很容易评估量化的。
另外创建的时候,最好评估下大概每秒的请求量有多少,然后来合理的初始化线程数和队列大小。
日拱一卒,功不唐捐
今日推荐

本文分享自微信公众号 - 一个程序员的成长(xiaozaibuluo)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。










