
1.Jupyter读取数据警告ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators
在使用Jupyter Notebook读取数据进行分析时,如下:
<ipython-input-5-9af9eaa72e92>:5: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
users = pd.read_csv('users.dat',sep = '::',header = None,names = labels)提示C引擎不支持正则表达式分割,需要使用Python引擎,此时只需要在读取数据文件时加入参数,engine='python'即可,如下:
users = pd.read_csv('users.dat',sep = '::',header = None,names = labels, engine='python')此时再执行就不会再提示警告信息了。
2.使用matplotlib画图警告 RuntimeWarning: Glyph 30005 missing from current font
在使用matplotlib库进行画图时,如果标题等文字中出现中文,就可能出现警告:
E:\Anaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:214: RuntimeWarning: Glyph 30005 missing from current font.
font.set_text(s, 0.0, flags=flags)
E:\Anaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:214: RuntimeWarning: Glyph 24433 missing from current font.
font.set_text(s, 0.0, flags=flags)
E:\Anaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:214: RuntimeWarning: Glyph 25968 missing from current font.
font.set_text(s, 0.0, flags=flags)
E:\Anaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:214: RuntimeWarning: Glyph 25454 missing from current font.
font.set_text(s, 0.0, flags=flags)
E:\Anaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:214: RuntimeWarning: Glyph 25454 missing from current font.
font.set_text(s, 0.0, flags=flags)意思是plt画图找不到字体,需要进行配置。 有两种方式:
临时设置 在调用画图函数前进行配置:
plt.rcParams['font.sans-serif']=['Microsoft YaHei'] #显示中文标签 plt.rcParams['axes.unicode_minus']=False即设置字体为微软雅黑,支持中文。 但是这只是临时设置,下一次再使用又得设置,显得很麻烦。
永久配置 永久设置是编辑matplotlib的配置文件
matplotlibrc,修改后以后无需再修改、一劳永逸。该文件一般位于%PythonPath%\Lib\site-packages\matplotlib\mpl-data(PythonPath即表示安装的Python路径),如果使用的是Anaconda,则是%AnacondaPath%\Lib\site-packages\matplotlib\mpl-data(AnacondaPath表示Anaconda的安装路径)。 在matplotlibrc文件中找到如下位置(定义font.family处):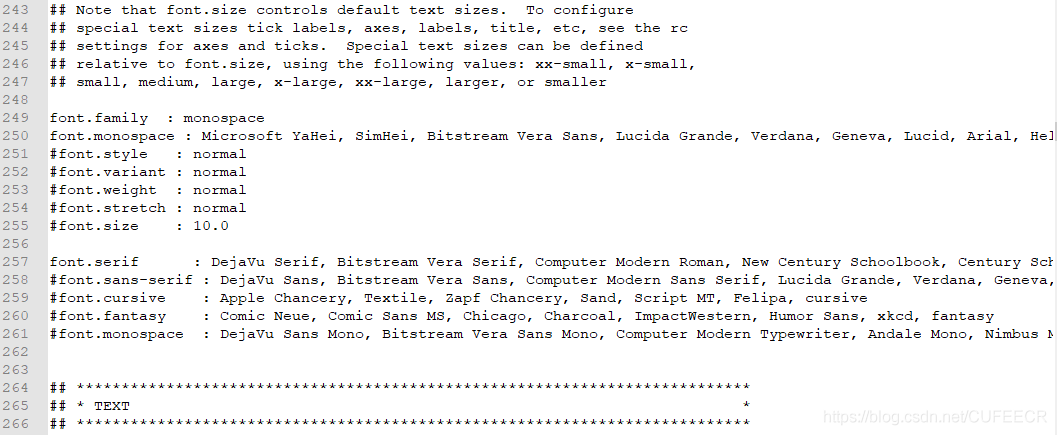 修改如下:
修改如下:## The font.size property is the default font size for text, given in pts. ## 10 pt is the standard value. ## ## Note that font.size controls default text sizes. To configure ## special text sizes tick labels, axes, labels, title, etc, see the rc ## settings for axes and ticks. Special text sizes can be defined ## relative to font.size, using the following values: xx-small, x-small, ## small, medium, large, x-large, xx-large, larger, or smaller font.family : monospace font.monospace : Microsoft YaHei, SimHei, Bitstream Vera Sans, Lucida Grande, Verdana, Geneva, Lucid, Arial, Helvetica, Avant Garde, sans-serif #font.style : normal #font.variant : normal #font.weight : normal #font.stretch : normal #font.size : 10.0主要是第10、11行,设置
font.family : monospace取消#注释,添加一行font.monospace : Microsoft YaHei, SimHei, Bitstream Vera Sans, Lucida Grande, Verdana, Geneva, Lucid, Arial, Helvetica, Avant Garde, sans-serif,Microsoft YaHei为微软雅黑、SimHei为黑体、支持中文。 然后再重启Jupyter Notebook或者重新运行代码即可显示中文,如下:
3.Pandas使用DataFrame.ix[]报错 'DataFrame' object has no attribute 'ix'
在较新版的pandas库中使用
DataFrame.ix[]时,会报错如下:
AttributeError: 'DataFrame' object has no attribute 'ix'意思是DataFrame没有ix属性,这是因为从pandas的1.0.0版本开始,移除了Series.ix和DataFrame.ix,可以直接使用DataFrame.iloc[]或DataFrame.loc[]代替。
4.Pandas画直方图报错'Rectangle' object has no property 'normed'
在使用Pandas画直方图时,如下:
values.hist(bins=100, alpha=0.3, color='k', normed=True)会报错AttributeError: 'Rectangle' object has no property 'normed',这是因为在新版的pandas库中已经没有定义这个属性了,可以去掉这个属性,即values.hist(bins=100, alpha=0.3, color='k'),也可以用density属性替代,即values.hist(bins=100, alpha=0.3, color='k', density=True)。
5.在对数据进行groupby时警告Indexing with multiple keys
在使用groupby()方法对数据进行分组时,有时候会使用到多个列,这时候会显示警告信息:
FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.这是因为在进行分组时使用多个列时的方式不对,为data1 = orders.groupby('付款时间')['支付金额','订单编号'].agg({'支付金额':'sum','订单编号':'count'}),显然,在[]中传入了多个参数,因此会提示警告,正确的做法是将这些列名放入一个列表,再将列表放入中括号,即为:
data1 = orders.groupby('付款时间')[['支付金额','订单编号']].agg({'支付金额':'sum','订单编号':'count'})即使用双层中括号即可。
本文原文首发来自博客专栏数据分析,由本人转发至https://www.helloworld.net/p/deegsj9sJni51,其他平台均属侵权,可点击https://blog.csdn.net/CUFEECR/article/details/108221323查看原文,也可点击https://blog.csdn.net/CUFEECR浏览更多优质原创内容。












