
如今的大数据批计算,随着 Hive 数仓的成熟,普遍的模式是 Hive metastore + 计算引擎。常见的计算引擎有 Hive on MapReduce、Hive on Tez、Hive on Spark、Spark integrate Hive、Presto integrate Hive,还有随着 Flink 1.10 发布后生产可用的 Flink Batch SQL。
Flink 作为一个统一的计算引擎,旨在提供统一的流批体验以及技术栈。Flink 在 1.9 合并了 Blink 的代码,并在 1.10 中完善了大量的功能以及性能,可以运行所有 TPC-DS 的查询,性能方面也很有竞争力,Flink 1.10 是一个生产可用的、批流统一的 SQL 引擎版本。
在搭建计算平台的过程中,性能和成本是选取计算引擎的很关键的因素。为此,Ververica 的 flink-sql-benchmark [1] 项目提供了基于 Hive Metastore 的 TPC-DS Benchmark 测试的工具,为了测试更靠近真正的生产作业:
测试的输入表都是标准的 Hive 表,数据全在与生产一致的 Hive 数仓中。其它计算引擎也能方便分析这些表。
数据的格式采用 ORC,ORC 是常用的生产文件格式,提供较高的压缩率,和较好的读取性能。
选取 TPC-DS Benchmark 的 10TB 数据集,10TB 的数据集是比较常见的生产规模。如果只有 1TB,完全可以在传统数据库中运行起来,不太适合大数据的测试。
我们在 20 台机器上测试了三种引擎:Flink 1.10、Hive 3.0 on MapReduce、Hive 3.0 on Tez,从两个维度测试了引擎的成绩:
总时长 :直观的性能数据,但是可能会受到个别 queries 的较大影响。
几何平均 :表示一组数的中心趋势,它可以更好的消除个别 queries 的较大影响,呈现较真实的平均数。
结果摘要:
Flink 1.10 VS Hive 3.0 on MapReduce
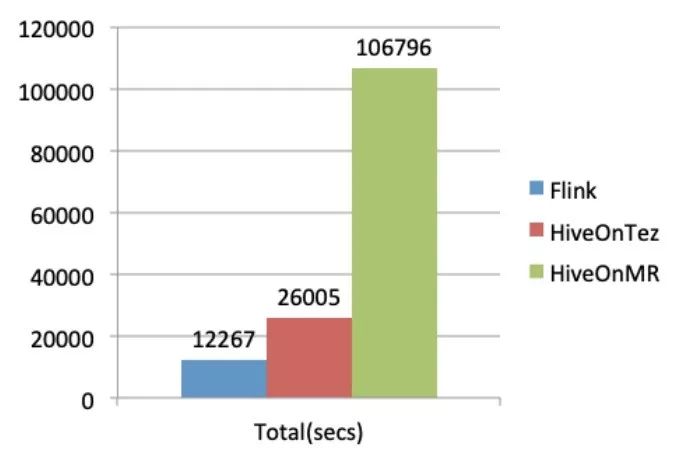
Flink 总时长的性能是 Hive on MapReduce 的 8.7 倍。
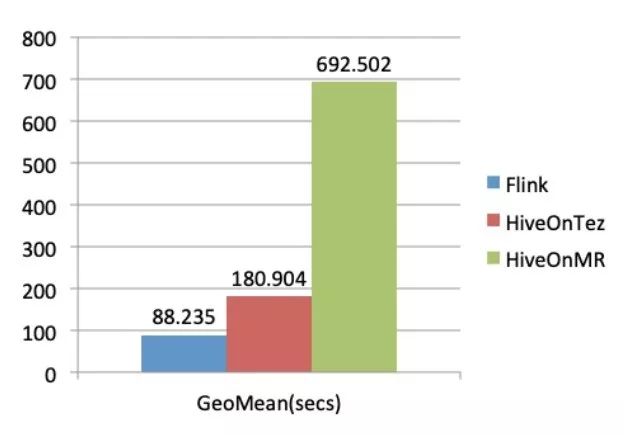
Flink Queries 几何平均的性能是 Hive on MapReduce 的 7.8 倍。
Flink 1.10 VS Hive 3.0 on Tez
Flink 总时长的性能是 Hive on Tez 的 2.1 倍。
Flink Queries 几何平均的性能是 Hive on Tez 的 2.0 倍。
运行总时间的对比成绩是:
Queries 几何平均的对比成绩是:
本文只测试了上述引擎和 10TB 的数据集,读者可以根据自己的集群规模,选取特定的数据集,使用 flink-sql-benchmark 工具来运行更多引擎的对比测试。
Benchmark 详情
Benchmark 环境
具体环境及调优说明:
计算环境 :20 台机器,机器参数为 64 核 intel 处理器、256GB 内存、1 SSD 盘用于计算引擎、多块 SATA 盘用于 HDFS、万兆网卡。
集群环境 :Yarn + HDFS + Hive。
Flink参数 :flink-conf.yaml [2]。
Hive参数 :主要调优了 MapJoin 的阈值,提高性能的同时避免 OOM。
选用较新的 Hadoop 版本(3.X) ,并选用了较新的 Hive 和 Tez 版本
Benchmark 步骤
■ 环境准备
准备 Hadoop (HDFS + YARN) 环境
准备 Hive 环境
■ 数据集生成
分布式生成 TPC-DS 数据集,并加载 TEXT 数据集到 Hive,原始数据是 Csv 的格式。建议分布式生成数据,这也是个比较耗时的步骤。(flink-sql-benmark 工具中集成了 TPC-DS 的工具)
Hive TEXT 表转换为 ORC 表,ORC 格式是常见的 Hive 数据文件格式,行列混合的存储有利于后续的快速分析,也有很高的压缩比。执行 Query:create table ${NAME} stored as ${FILE} as select * from ${SOURCE}.${NAME};
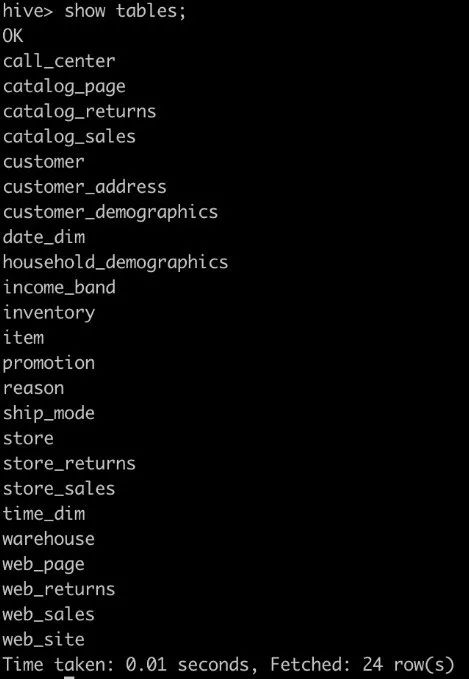
如图,生成了 TPC-DS 官方说明的 7 张事实表和 17 张维表。
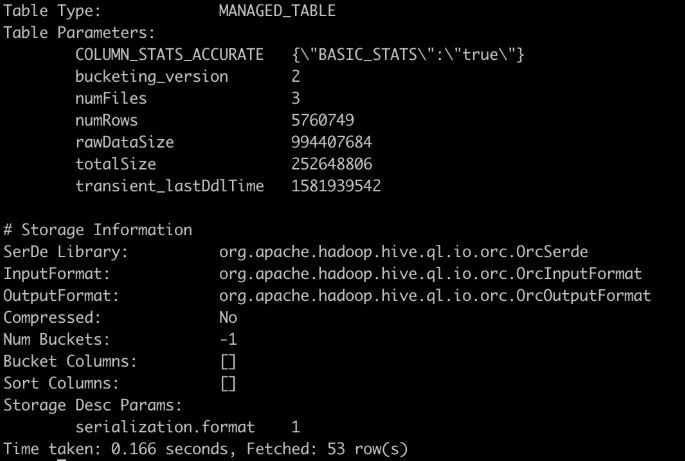
- 分析 Hive 表,统计信息对于分析作业的查询优化非常重要,对于复杂的 SQL,Plan 的执行效率有很大的差异。Flink 不但支持读取 Hive 的 Table 统计信息,也支持读取 Hive 的分区统计信息,根据统计信息进行 CBO 的优化。执行命令:analyze table ${NAME} compute statistics for columns;
■ Flink 运行 Queries
准备 Flink 环境,搭建 Flink Yarn Session 环境,推荐使用 Standalone 或者 Session 模式,可以复用 Flink 的进程,加快分析型作业的速度。
编写代码运行 Queries,统计执行时间等相关信息,具体代码可以直接复用 flink-sql-benchmark 里的 flink-tpcds 工程。
FLINK_HOME/flink run 运行程序,执行所有 queries,等待执行完毕,统计执行时间。
■ 其它引擎运行 Queries
根据其它引擎的官网提示,搭建环境。
得益于标准的 Hive 数据集,可以方便的使用其它引擎来读取 Hive 数据。
在运行时,值得注意的是需要达到集群的瓶颈,比如 Cpu、比如 Disk,一定是有瓶颈出现,才能证明运行方式和参数是比较合理的,为此,需要一些性能调优。
Benchmark 分析
Flink 1.10
Flink 1.9 在合并 Blink 代码的时候,就已经完成了很多工作:深度 CodeGeneration、Binary 存储与计算、完善的 CBO 优化、Batch Shuffler,为后续的性能突破打下了扎实的基础。
Flink 1.10 继续完善 Hive 集成,并达到了生产级别的 Hive 集成标准,其它也在性能和开箱即用方面做了很多工作:
Hive 多版本的支持,支持了 Hive 1.0 以后的主要版本。
向量化的 ORC 读,目前只在 Hive 2.0 以上版本才会默认开启。
Hive 1.X 版本的支持已经在进行中:FLINK-14802 [3]
Parquet 的向量化读支持也已经在开发中:FLINK-11899 [4]
基于比例的弹性内存分配,这不仅利于 Operator 可以更多的使用内存,而且大大方便了用户的配置,用户不再需要配置 Operator 内存,Operator 根据 Slot 弹性的拿到内存,提高了 Flink 开箱即用的易用性。详见 FLIP-53 [5]
Shuffle 的压缩:Flink 默认给 Batch 作业开启中间数据落盘的方式,这有利于避免调度死锁的可能,也提供了良好的容错机制,但是大量的落盘可能导致作业瓶颈在磁盘的吞吐上,所以 Flink 1.10 开发了 Shuffle 的压缩,用 Cpu 换 IO。
新调度框架:Flink 1.10 也引入新了的调度框架,这有利于 JobMaster 的调度性能,避免并发太大时,JobMaster 成为性能瓶颈。
Flink 参数分析
Flink 1.10 做了很多参数的优化,提高用户的开箱即用体验,但是由于批流一体的一些限制,目前也是需要进行一些参数设置的,这里本文粗略分析下。
■ Table 层参数:
table.optimizer.join-reorder-enabled = true:需要手动打开,目前各大引擎的 JoinReorder 少有默认打开的,在统计信息比较完善时,是可以打开的,一般来说 reorder 错误的情况是比较少见的。
table.optimizer.join.broadcast-threshold = 10*1024*1024:从默认值 1MB 调整到 10MB,目前 Flink 的广播机制还有待提高,所以默认值为 1MB,但是在并发规模不是那么大的情况下,可以开到 10MB。
table.exec.resource.default-parallelism = 800:Operator 的并发设置,针对 10T 的输入,建议开到 800 的并发,不建议太大并发,并发越大,对系统各方面的压力越大。
■ TaskManager 参数分析:
taskmanager.numberOfTaskSlots = 10:单个 TM 里的 slot 个数。
TaskManager 内存参数:TaskManager 的内存主要分为三种,管理内存、网络内存、JVM 相关的其它内存。需要理解下官网的文档,才能有效的设置这些参数。
taskmanager.memory.process.size = 15000m:TaskManager 的总内存,减去其它内存后一般留给堆内 3-5GB 的内存。
taskmanager.memory.managed.size = 8000m:管理内存,用于 Operator 的计算,留给单个 Slot 300 - 800MB 的内存是比较合理的。
taskmanager.network.memory.max = 2200mb:Task 点到点的通信需要 4 个 Buffers,根据并发大概计算得出需要 2GB,可以通过尝试得出,Buffers 不够会抛出异常。
■ 网络参数分析
taskmanager.network.blocking-shuffle.type = mmap:Shuffle read 使用 mmap 的方式,直接靠系统来管理内存,是比较方便的形式。
taskmanager.network.blocking-shuffle.compression.enabled = true:Shuffle 使用压缩,这个参数是批流复用的,强烈建议给批作业开启压缩,不然瓶颈就会在磁盘上。
■ 调度参数分析
cluster.evenly-spread-out-slots = true:在调度 Task 时均匀调度到每个 TaskManager 中,这有利于使用所有资源。
jobmanager.execution.failover-strategy = region:默认全局重试,需打开 region 重试才能 enable 单点的 failover。
restart-strategy = fixed-delay:重试策略需要手动设置,默认是不重试的。
其它 timeout 相关参数是为了避免调度和运行过程中,大数据量导致的网络抖动,进而导致作业失败的问题。
Flink 1.11 及后续规划
后续 Flink 社区会在完善功能的同时进一步夯实性能:
提供 SQL Gateway 以及 JDBC Driver,目前提供独立仓库,面向 Flink 1.10。[6] [7]
提供 Hive 语法兼容模式,避免 Hive 用户的困扰。
完善 ORC 和 Parquet 的向量化读。
N-Ary stream operator [8]:开发 table 层的 chain 框架,进一步避免 Shuffle 落盘导致的开销。
参考链接:
**[1]**https://github.com/ververica/flink-sql-benchmark
**[2]**https://github.com/ververica/flink-sql-benchmark/blob/master/flink-tpcds/flink-conf.yaml
**[3]**http://jira.apache.org/jira/browse/FLINK-14802
**[4]**https://issues.apache.org/jira/browse/FLINK-11899
**[6]**https://github.com/ververica/flink-sql-gateway
**[7]**https://github.com/ververica/flink-jdbc-driver
**[8]**https://cwiki.apache.org/confluence/display/FLINK/FLIP-92%3A+Add+N-Ary+Stream+Operator+in+Flink
# 重磅福利 #
《Demo: 基于 Flink SQL 构建离线应用》的 PPT 来啦!识别下方二维码,后台回复关键字“ 0218SQL ”即可获取本次直播课程 Demo 演示 PPT~
2 月 20 日(本周四)晚上 20:00,还有 Flink 1.10 特别篇《Demo: 基于 Flink SQL 构建实时应用》,敬请期待!

你也「 在看 」吗?👇
本文分享自微信公众号 - Flink 中文社区(gh_5efd76d10a8d)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












