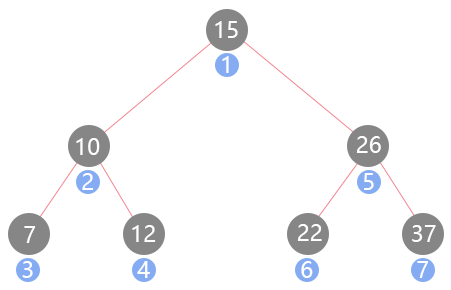
前序遍历
「前序遍历」指先访问节点,再遍历节点的左子树,最后遍历节点的右子树,按照这种规则不重复地访问树中所有节点的过程。
模拟过程

过程中,用「打印节点值」表示对节点的访问,「访问结束」表示该节点完成了访问节点,遍历节点的左子树,遍历节点的右子树的所有过程。
- 到达节点A,访问节点A(打印节点值),开始遍历A的左子树
- 到达节点B,访问节点B(打印节点值),开始遍历B的左子树
- 到达节点D,访问节点D(打印节点值),开始遍历D的左子树
- 到达节点H,访问节点H(打印节点值),H仅有右子树,开始遍历H的右子树
-
到达节点K,访问节点K(打印节点值),K无子树,节点K的访问结束
- 节点K的访问结束同时意味着节点H的右子树遍历结束,且节点H仅有右子树,节点H的访问结束
- 节点H的访问结束同时意味着节点D的左子树遍历结束,且节点D仅有左子树,节点D的访问结束
- 节点D的访问结束同时意味着节点B的左子树遍历结束,开始遍历节点B的右子树
-
到达节点E,访问节点E(打印节点值),E无子树,节点E的访问结束
- 节点E的访问结束同时意味着节点B的右子树遍历结束,且节点B的左子树也遍历结束,节点B的访问结束
- 节点B的访问结束同时意味着节点A的左子树遍历结束,开始遍历节点A的右子树
- 到达节点C,访问节点C(打印节点值),开始遍历C的左子树
- 到达节点F,访问节点F(打印节点值),开始遍历F的左子树
-
到达节点I,访问节点I(打印节点值),I无子树,节点I的访问结束
- 节点I的访问结束同时意味着节点F的左子树遍历结束,且节点F仅有左子树,节点F的访问结束
- 节点F的访问结束同时意味着节点C的左子树遍历结束,开始遍历节点C的右子树
- 到达节点G,访问节点G(打印节点值),G仅有右子树,开始遍历G的右子树
-
到达节点J,访问节点J(打印节点值),J无子树,节点J的访问结束
- 节点J的访问结束同时意味着节点G的右子树遍历结束,且节点G仅有右子树,节点G的访问结束
- 节点G的访问结束同时意味着节点C的右子树遍历结束,且节点C的左子树也遍历结束,节点C的访问结束
- 节点C的访问结束同时意味着节点A的右子树遍历结束,且节点A的左子树也遍历结束,节点A的访问结束
至此,树中所有节点都被访问
分析过程
上述过程中节点的数据结构如下
function Node(value) {
this.value = value
this.left = null
this.right = null
}上述过程中树的结构如下,被当作变量root保存
root {
value: 'A',
left: {
value: 'B',
left: {
value: 'D',
left: {
value: 'H',
left: null,
right: {
value: 'K',
left: null,
right: null
}
},
right: null
},
right: {
value: 'E',
left: null,
right: null
}
},
right: {
value: 'C',
left: {
value: 'F',
left: {
value: 'I',
left: null,
right: null
},
right: null
},
right: {
value: 'G',
left: null,
right: {
value: 'J',
left: null,
right: null
}
}
}
}分析过程:每到达一个节点,先访问节点(打印节点的值),然后寻找下一个节点并前往,直至所有节点都被访问完成,且初始的节点为树的根节点(root)。草写代码如下
const preOrderTraverse = root => {
let node = root // 初始的节点为树的根节点
while (node) { // 若不存在下一个节点,循环终止
console.log(node.value) // 访问节点(打印节点的值)
...nextNode // 寻找下一个前往的节点
node = nextNode || null // 前往下一个节点,若找不到下一个节点,则所有节点都被访问完成
}
}寻找下一个节点并前往,前往下一个节点的方式有多种,其中一种是若节点存在左子树,则下一个节点就是该左子树的根,如上述过程中 A->B, B->D, D->H, C->F, F->I

翻译成代码就是
const preOrderTraverse = root => {
let node = root // 初始的节点为树的根节点
while (node) { // 若不存在下一个节点,循环终止
console.log(node.value) // 访问节点(打印节点的值)
let nextNode
if(node.left){ // 若节点存在左子树
nextNode = node.left // 则下一个节点就是该左子树的根
}
... // 未完待续
node = nextNode || null // 前往下一个节点,若找不到下一个节点,则所有节点都被访问完成
}
}寻找下一个节点并前往,前往下一个节点的另一种方式是,若节点仅存在右子树,则下一个节点就是该右子树的根,如上述过程中 H->K, G->J

翻译成代码就是
const preOrderTraverse = root => {
let node = root // 初始的节点为树的根节点
while (node) { // 若不存在下一个节点,循环终止
console.log(node.value) // 访问节点(打印节点的值)
let nextNode
if(node.left){ // 若节点存在左子树
nextNode = node.left // 则下一个节点就是该左子树的根
}else if(!node.left&&node.right){ // 若节点仅存在右子树
nextNode = node.right // 则下一个节点就是该右子树的根
}
... // 未完待续
node = nextNode || null // 前往下一个节点,若找不到下一个节点,则所有节点都被访问完成
}
}前面提到的寻找下一个节点并前往的方式中,其下一个节点都是当前节点的左孩子或右孩子,分析前序遍历的过程,发现还有一种前往的下一个节点并不是当前节点的孩子的情况,如上述过程中 K->E, E->C, I->J

当节点仅含一颗子树时,就遍历该子树,当节点含左右子树时,先遍历其左子树,而将其右子树的根保存。当其左子树遍历完成时(触发的时机是到达叶节点),前往其右子树的根,开始遍历其右子树。
例如,到节点A时,将其右子树的根节点C保存起来,当左子树遍历结束时,才取出节点C开始遍历右子树。到达节点B,将其右子树的根节点E保存起来。当到达叶节点K,节点B的左子树遍历结束,取出节点E开始遍历右子树。将节点E弹出,此时仅剩节点A的右子树待遍历。节点C先于节点E保存,但后于节点E取出,故采用栈保存待遍历的右子树的根。
翻译成代码就是
const preOrderTraverse = root => {
let node = root, // 初始的节点为树的根节点
stack = [] // 用栈保存待遍历的右子树的根
while (node) { // 若不存在下一个节点,循环终止
console.log(node.value) // 访问节点(打印节点的值)
let nextNode
if(node.left){ // 若节点存在左子树
node.right && stack.push(node.right) // 若是含左右子树的节点,遍历左子树,保存右子树
nextNode = node.left // 则下一个节点就是该左子树的根
}else if(!node.left&&node.right){ // 若节点仅存在右子树
nextNode = node.right // 则下一个节点就是该右子树的根
}else{ // 叶节点,说明最近的含有左右子树的节点的左子树遍历结束,开始遍历含有左右子树的节点的右子树
nextNode = stack.pop() // 前往那个右子树的根,被存于栈中,若栈空,说明没有右子树待遍历,遍历结束
}
node = nextNode // 前往下一个节点,若找不到下一个节点,则所有节点都被访问完成
}
}整理最终代码如下
const preOrderTraverse = root => {
let node = root, // 初始的节点为树的根节点
stack = [] // 用栈保存待前往的节点
while (node) { // 若不存在下一个节点,循环终止
console.log(node.value) // 访问节点(打印节点的值)
if (node.left) { // 若节点存在左子树
node.right && stack.push(node.right) // 若是含左右子树的节点,将其右孩子保存
node = node.left // 则下一个节点就是该左子树的根
} else if (!node.left && node.right) { // 若节点仅存在右子树
node = node.right // 则下一个节点就是该右子树的根
} else { // 叶节点,说明最近的含有左右子树的节点的左子树遍历结束,开始遍历含有左右子树的节点的右子树
node = stack.pop() // 前往那个右子树的根,被存于栈中,若栈空,说明没有右子树待遍历,遍历结束
}
}
}
preOrderTraverse(root)
// A B D H K C F I G J为什么我总想的那么复杂
const preOrderTraverse = root => {
let current = root,
stack = []
while (current || stack.length !== 0) {
if (current) {
console.log(current.value) // 访问节点
stack.push(current)
current = current.left // 遍历左子树
} else {
current = stack.pop()
current = current ? current.right : null // 遍历右子树
}
}
}
preOrderTraverse(binaryTree.root)