
楔子
在我们想要新上线一个 Node.js 应用之前,尤其是技术栈切换的第一个 Node.js 应用,由于担心其在线上的吞吐量表现,肯定会想要进行性能压测,以便对其在当前的集群规模下能抗住多少流量有一个预估。本案例实际上正是在这样的一个场景下,我们想要上线 Node.js 技术栈来做前后端分离,那么刨开后端服务的响应 QPS,纯使用 Node.js 进行的模板渲染能有怎么样的表现,这是大家非常关心的问题。
本书首发在 Github,仓库地址:https://github.com/aliyun-node/Node.js-Troubleshooting-Guide,云栖社区会同步更新。
优化过程
集群在性能压测下反映出来的整体能力其实由单机吞吐量就可以测算得知,因此这次的性能压测采用的 4 核 8G 内存的服务器进行压测,并且页面使用比较流行的 ejs 进行服务端渲染,进程数则按照核数使用 PM2 启动了四个业务子进程来运行。
I. 开始压测
完成这些准备后,使用阿里云提供的 PTS 性能压测工具进行压力测试,此时大致单机 ejs 模板渲染的 QPS 在 200 左右,此时通过 Node.js 性能平台 监控可以看到四个子进程的 CPU 基本都在 100%,即 CPU 负载达到了瓶颈,但是区区 200 左右的 QPS 显然系统整体渲染非常的不理想。
II. 模板缓存
因为是 CPU 达到了系统瓶颈导致整体 QPS 上不去,因此按照第二部分工具篇章节的方法,我们在平台上抓了 压测期间 的 3 分钟的 CPU Profile,展现的结果如下图所示:

这里就看到了很奇怪的地方,因为压测环境下我们已经打开了模板缓存,按理来说不会再出现 ejs.compile 函数对应的模板编译才对。仔细比对项目中的渲染逻辑代码,发现这部分采用了一个比较不常见的模块 koa-view,项目开发者想当然地用 ejs 模块地入参方式传入了 cache: true,但是实际上该模块并没有对 ejs 模板做更好的支持,因此实际压测情况下模板缓存并没有生效,而模板地编译动作本质上字符串处理,它恰恰是一个 CPU 密集地操作,这就导致了 QPS 达不到预期的状况。
了解到原因之后,首先我们将 koa-view 替换为更好用的 koa-ejs 模块,并且按照 koa-ejs 的文档正确开启缓存:
render(app, {
root: path.join(__dirname, 'view'),
viewExt: 'html',
cache: true
});
再次进行压测后,单机下的 QPS 提升到了 600 左右,虽然大约提升了三倍的性能,但是仍然达不到预期的目标。
III. include 编译
为了继续优化进一步提升服务器的渲染性能,我们继续在压测期间抓取 3 分钟的 CPU Profile 进行查看:
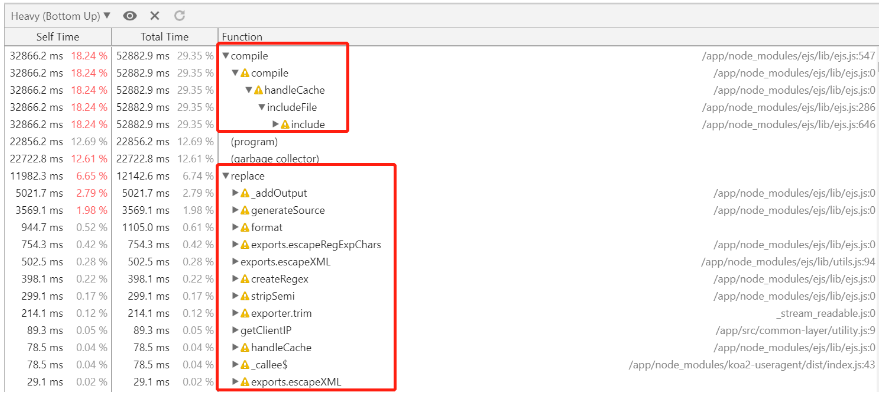
可以看到,我们虽然已经确认使用 koa-ejs 模块且正确开启了缓存,但是压测期间的 CPU Profile 里面竟然还有 ejs 的 compile 动作!继续展开这里的 compile,发现是 includeFile 时引入的,继续回到项目本身,观察压测的页面模板,确实使用了 ejs 注入的 include 方法来引入其它模板:
<%- include("../xxx") %>
对比 ejs 的源代码后,这个注入的 include 函数调用链确实也是 include -> includeFile -> handleCache -> compile,与压测得到的 CPU Profile 展示的内容一致。那么下面红框内的 replace 部分也是在 compile 过程中产生的。
到了这里开始怀疑 koa-ejs 模块没有正确地将 cache 参数传递给真正负责渲染地 ejs 模块,导致这个问题地发生,所以继续去阅读 koa-ejs 的缓存设置,以下是简化后的逻辑(koa-ejs@4.1.1 版本):
const cache = Object.create(null);
async function render(view, options) {
view += settings.viewExt;
const viewPath = path.join(settings.root, view);
// 如果有缓存直接使用缓存后的模板解析得到的函数进行渲染
if (settings.cache && cache[viewPath]) {
return cache[viewPath].call(options.scope, options);
}
// 没有缓存首次渲染调用 ejs.compile 进行编译
const tpl = await fs.readFile(viewPath, 'utf8');
const fn = ejs.compile(tpl, {
filename: viewPath,
_with: settings._with,
compileDebug: settings.debug && settings.compileDebug,
debug: settings.debug,
delimiter: settings.delimiter
});
// 将 ejs.compile 得到的模板解析函数缓存起来
if (settings.cache) {
cache[viewPath] = fn;
}
return fn.call(options.scope, options);
}
显然,koa-ejs 模板的模板缓存是完全自己实现的,并没有在调用 ejs.compile 方法时传入的 option 参数内将用户设置的 cache 参数传递过去而使用 ejs 模块提供的 cache 能力。但是偏偏项目在模板内又直接使用了 ejs 模块注入的 include 方法进行模板间的调用,产生的结果就是只缓存了主模板,而主模板使用 include 调用别的模板还是会重新进行编译解析,进而造成压测下还是存在大量重复的模板编译动作导致 QPS 升不上去。
再次找到了问题的根源,为了验证是否是 koa-ejs 模块本身的 bug,我们在项目中将其渲染逻辑稍作更改:
const fn = ejs.compile(tpl, {
filename: viewPath,
_with: settings._with,
compileDebug: settings.debug && settings.compileDebug,
debug: settings.debug,
delimiter: settings.delimiter,
// 将用户设置的 cache 参数传递给 ejs 而使用到其提供的缓存能力
cache: settings.cache
});
然后打包后进行压测,此时单机 QPS 从 600 提升至 4000 左右,基本达到了上线前的性能预期,为了确认压测下是否还有模板的编译动作,我们继续在 Node.js 性能平台 上抓取压测期间 3 分钟的 CPU Profile:
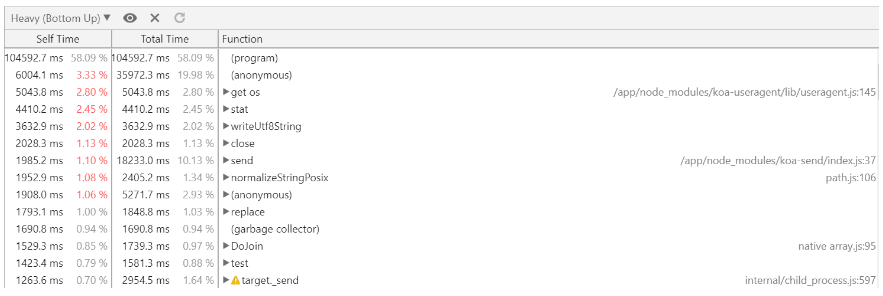
可以看到上述对 koa-ejs 模板进行优化后,ejs.compile 确实消失了,而压测期间不再有大量重复且耗费 CPU 的编译动作后,应用整体的性能比最开始有了 20 倍左右的提升。文中 koa-ejs 模块缓存问题已经在 4.1.2 版本(包含)之后被修复了,详情可以见 cache include file,如果大家使用的 koa-ejs 版本 >= 4.1.2 就可以放心使用。
结尾
CPU Profile 本质上以可读的方式反映给开发者运行时的 JavaScript 代码执行频繁程度,除了在线上进程出现负载很高时能够用来定位问题代码之外,它在我们上线前进行性能压测和对应的性能调优时也能提供巨大的帮助。这里需要注意的是:仅当进程 CPU 负载非常高的时候去抓取得到的 CPU Profile 才能真正反馈给我们问题所在。
在这个源自真实生产的案例中,我们也可以看到,正确和不正确地去使用 Node.js 开发应用其前后运行效率能达到二十倍的差距,Node.js 作为一门服务端技术栈发展至今日,其本身能够提供的性能是毋庸置疑的,绝大部分情况下执行效率不佳是由我们自身的业务代码或者三方库本身的 Bug 引起的,Node.js 性能平台 则可以帮助我们以比较方便的方式找出这些 Bug。
原文链接
本文为云栖社区原创内容,未经允许不得转载。











