
搜索程序一般由索引链和搜索组件组成。
索引链主要是先检索原始内容,再根据原始内容来创建对应的文档,并对创建的文档进行索引;
搜索组件用于接收用户的查询请求并响应结果,一般由用户接口、构建可编程查询语句的方法、查询语句执行引擎及结果展示组件组成。
一、ES的基本概念
索引(Index)
ES 将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。同传统数据库对比来看,索引相当于SQL中的一个“数据库”,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个ES集群中可以按需创建任意数据的索引。
类型(Type)
类型是索引内部的逻辑分区(category/partition),就是为拥有相同的域的文档做的预定义,因此一个索引内部可定义一个或多个类型。例如,在索引中,可以定义一个用于存储用户数据的类型,一个存储日志数据的类型,以及一个存储评论数据的类型。类比传统库,类型相当于“表”。
文档(Document)
文档是Lucence索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。文档由一个多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档在结构上有某种程度上的相似之处,类比传统库,文档相当于“记录”,可以拥有多条记录。
映射(Mapping)
ES中,所有的文档在存储之前都要首先进行分析。用户可根据需要定义如何将文本分割成token、哪些token应该被过滤掉,以及哪些文本需要进行额外处理等等。另外,ES还提供了额外功能,例如将域中的内容按需排序。事实上,ES也能自动根据其值确定域的类型。
节点(Node)
运行了单个实例的ES主机称为节点,它是集群的一个成员,可以存储数据、参与集群索引及搜索操作。类似于集群,节点靠其名称进行标识,默认为启动时自动生成的随机marvel字符串名称--注(marvel是ES的管理可监控工具,“随机marvel字符串名称”有点疑问)。用户可以按需要自定义任何希望使用的名称,但是出于管理的目的,此名称应该被设置成较好的识别性。节点通过为其配置的ES集群名称确定其所要加入的集群。
分片(Shard)和副本(Replica)
ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,每一个物理的Lucene索引成为一个分片(shard)。每个分片其内部都是一个全功能且独立的索引,因此可由集群中的任何主机存储。创建索引时,用户可指定其分片的数量,默认数量为5个。
Shard有两种类型:primary和replica,即主shard及副本shard。primary shard用于文档存储,每个新的索引会自动创建5个primary shard,当然此数量可在索引创建之前通过配置自行定义,不过,一旦创建完成,其primary shard的数量将不可更改。replica shard是primary shard的副本,用于冗余数据集提高搜索性能。每个primary shard默认配置一个replica shard,但也可以配置多个,且其数量可动态更改。ES会根据需要自动增加或减少replica shard的数量。
二、安装elasticsearch
https://www.elastic.co/downloads/elasticsearch 下载5.4.3版本。解压运行es前,必须安装jdk1.8+。
在linux下运行es,会遇到root权限的问题。
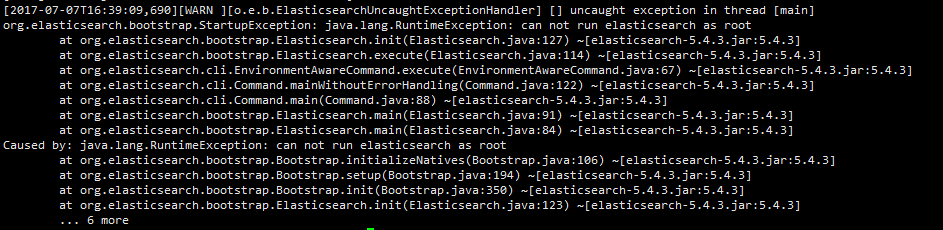
两种解决方式:
1、创建新用户,由于安全问题,es不允许root用户直接运行,要创建新用户;
adduser es_user
passwd xxxxx
chown -hR es_user /usr/local/src/es/elasticsearch-5.4.3
su es_user 后 cd至es目录./bin/elasticsearch
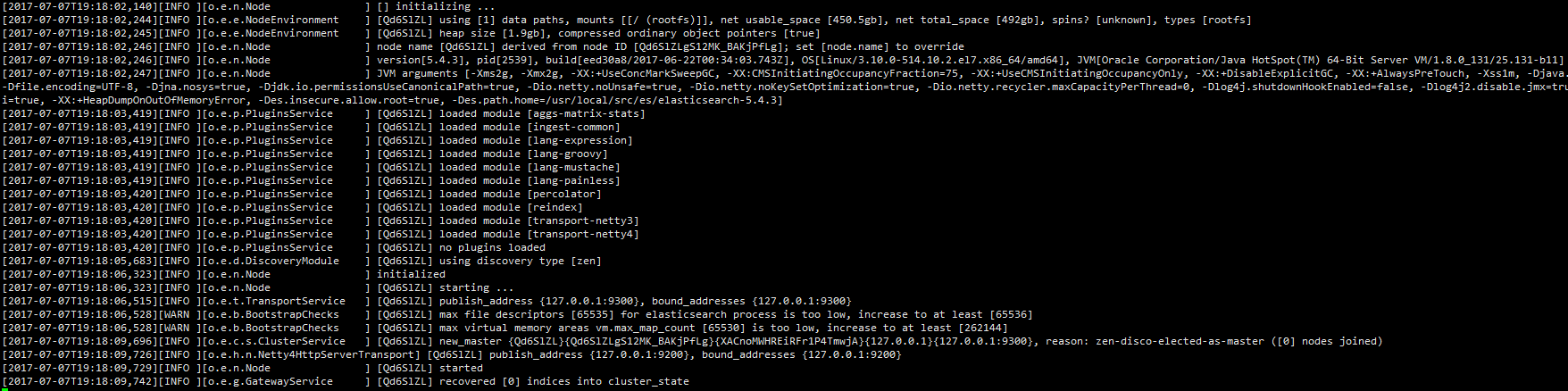
至此es成功启动。
如果报错如下:

需修改sysctl的配置,vim /etc/sysctl.conf
添加vm.max_map_count = 262144,然后生效配置文件 sudo /etc/sysctl.conf -p
对于第一个错误max file,见如下截图

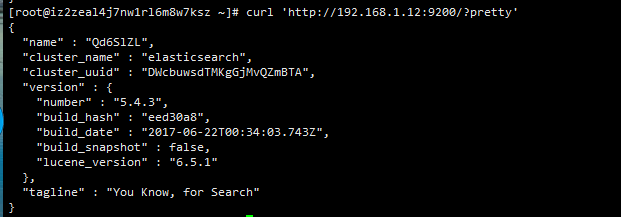
正常启动的情况下,输入curl 'http://***:9200/' 会出现如下结果
2、修改es的属性,以支持root启动
2.1)在执行es时加上参数-Des.insecure.allow.root=true(网上推荐)
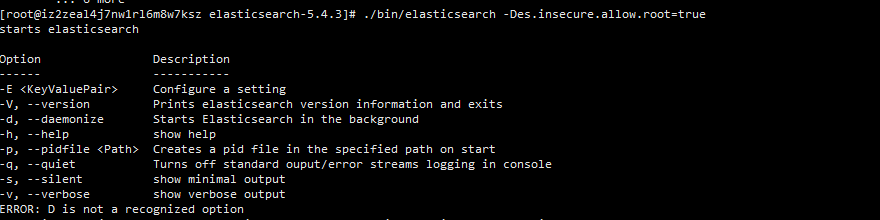
注:这种方式有错误,提供D不是有效的属性
2.2)ES_JAVA_OPTS="-Des.insecure.allow.root=true" 修改elasticsearch执行文件(网上推荐)
注:这种方式依然不奏效
https://discuss.elastic.co/t/elasticsearch-5-1-1-cannot-run-as-root-user/70304/7
似乎从5.0+的版本后es不再允许root运行应用,只能采用第一种方式,创建新用户。










