

Atlassian 产品的设计****理念

工欲善其事,必先利其器!今天,我们就来聊聊全球敏捷开发团队普遍使用的两大利器:来自澳大利亚的软件企业 Atlassian 的 Jira 和 Confluence。其设计理念彻底地贯彻了敏捷开发所倡导的去中心化、协作、集体讨论、信息共享、灵活、透明、可视化等原则。

为了让大家更好的理解,我们假设一个场景:
假设小赵是负责需求分析的BA,她需要和项目干系人一起进行需求分析和确认。
按照过去的做法,小赵会用Word来组织一份需求文档,然后通过邮件把文档发给所有干系人收集意见。干系人也会通过邮件回复意见。然后她又要把根据意见修改的版本发给所有干系人。由此会产生大量的邮件。
由于只有小赵掌握关于需求的全部和最新的信息,每次当某个干系人想要翻阅需求文档时,由于不确定TA手头上的版本是否是最新的,TA一定会找小赵再要一次。小赵需要不厌其烦地招呼这些主。
而且万一小赵病了或者需要突然请假,需求分析和确认这件事情就会停滞下来,其他人也会抓狂。

我们来看一下这里的几个问题:
中心化管理:最全面和最新的信息只掌握在小赵一个人手上,她也成为需求分析这个事情的中心节点,一旦她这个节点出了问题,就会成为整个环节的障碍和瓶颈,其他人的工作也会受到影响;
信息没有共享:信息全部通过邮件传递,不好翻阅和查找,除了小赵外,其他人都是两眼一抹黑,无法确定自己手头上的信息是否是最完整和最新的。
讨论的收集:意见都是通过邮件收集,小赵需要手动收集和整理,费时费力,其他人如果不会看每一封邮件,也无法掌握所有人的意见。
但如果小赵是用 Confluence 工作的话,会怎样呢?
去中心化和共享:虽然小赵是需求文档的原作者,但是由于Confluence是基于Wiki精神设计的,小赵发表初版后,任何干系人都可以直接对内容进行修改和贡献。而Confluence会自动记录每一版的修改,随时可以回退到任何一个版本。
由于任何人都可以在Confluence上看到最新的内容,他们随时可以看到最全面和及时的信息。小赵被彻底地解放了出来,即使她临时无法上班,其他人都可以继续讨论、完善需求,甚至交付团队可以基于最新的信息启动设计和开发。
集体讨论:所有干系人都可以通过Confluence的Comment功能对文档内容进行讨论、对话。所有人都可以很直接地查阅到全部讨论内容。
我们一起来看一段利用Confluence进行团队协作的视频:
而 Jira 也有类似的设计。
通过去中心化、共享和集体讨论,可以减少瓶颈,赋能每个人都有足够信息进行相应的工作,也使得过程变得透明,增加用户/业务对交付过程的理解与信任,促进融合,共同实现项目目标。

善用敏捷思维运用工具
既然 Jira 和 Confluence 是基于敏捷原则和价值观设计的,只有以敏捷思维来做事,才能善用这些工具。千万不要把旧思维运用在这些新工具上。
我们公司过去主要用 Word/Excel+SharePoint,很多同事在使用 Confluence时,只是把它当成了 SharePoint 的替代品,把一大堆 Word/Excel 文档以附件形式放在 Confluence 的页面上。
虽然 Confluence 可以管理附件文档,但这完全不是它的特长。
我们从RTC过渡到 Jira 时,也存在类似的情况。
那怎样使用 Jira 和 Confluence 才是正确的呢?我在这里总结了一些使用原则:
- Jira 的使用原则:
在 Jira 里面,所有的事项都统一叫做 Issue,而 Issue 可以定义 Issue 的类型,以映射我们真实工作过程的管理单元,比如它可以是 Story 代表用户故事,可以是 Test 代表测试用例,可以是 Incident 代表生产环境故障等。不同的 Issue 类型也可以对应不同的工作流(Workflow),以反映真实的工作过程。
Jira 是原生支持敏捷开发的。在敏捷开发中,有下面几个层级:
Epic - 史诗故事:包含某个特性或子项目的相关用户故事,便于用户故事归组。
Story - 用户故事:其中一种Issue的类型。这里强烈建议用户故事是具有一定业务价值、可单独交付、最小的需求。
Sub-task - 子任务:用户故事下需要分配给不同人处理、不可单独交付的的子任务,比如前端开发与后端开发,上、下游组件开发等。
由于一个 Epic 包含若干个用户故事(Story),在新建或编辑Story时,可以通过 Epic Link 的属性把该 Story 指向一个已有的 Epic,从而建立两者的隶属关系。
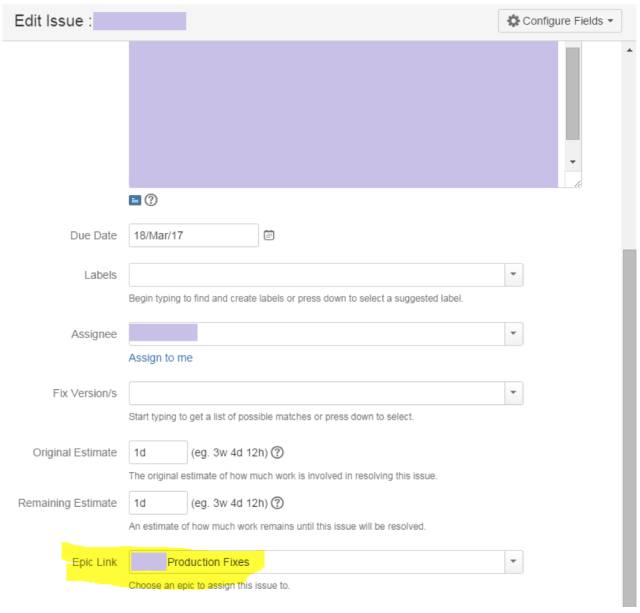
如果一个 Story 需要拆分成任干个任务交给不同人或团队完成,可以在 Story 中新建 Sub-task 并分配给相应的人或团队。Defect 也是一种 Sub-task。独立测试团队对某个 Story 进行测试时发现 Defect,应该在该 Story 下创建 Defect (Sub-task),把两者关联起来。
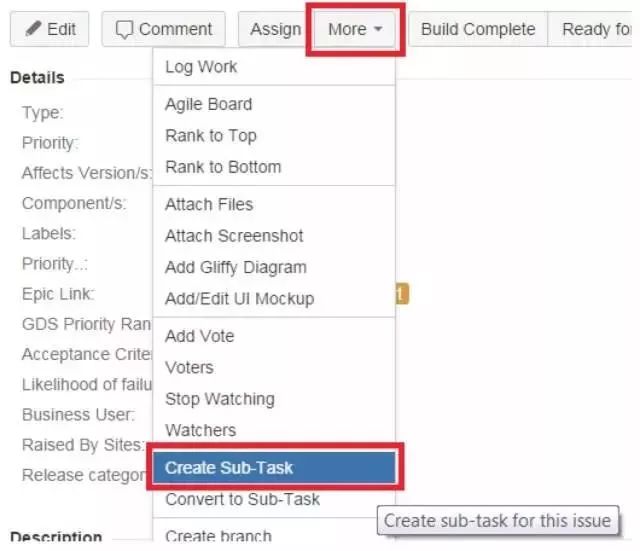
在一个 Story 级别的 Issue 中,可以按“More”按钮,然后按“Create Sub-Task”按钮来新建 Sub-task。Sub-task 和 Story 级别的 Issue 是可以相互转换的。所以即使一开始关系建错了,也没有关系。另外,Issue 类型可以通过 Move 功能随时进行转换。这也体现了 Jira 强大的灵活性和对延后决策的完美支持。
小结三者关系是 Epic 包含若干个 Story,Story 包含若干个 Sub-task。
我们可以在Jira中做发布计划。在管理界面中,管理员可以根据发布计划定义 Version,包含发布日期与发布提要。在每一个 Issue 中,我们可以在 Fix Version/s 属性中指定它将在哪个发布版本发布。可以通过Releases页面轻松分享发布提要(Release Note)。
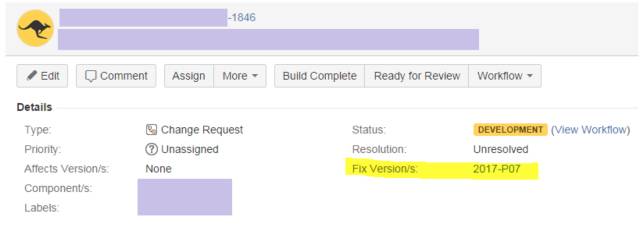
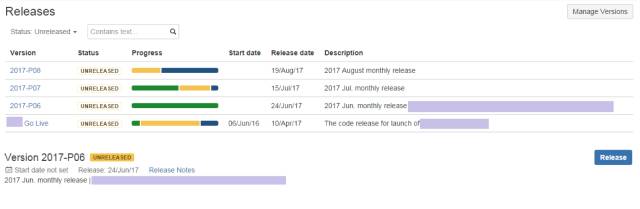
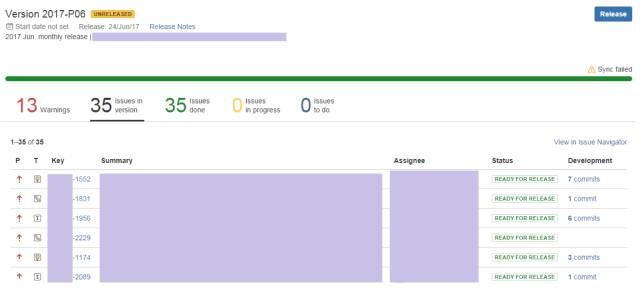
通过代码版本控制软件如 SVN、Git等的插件,只要在提交代码时,提交备注(Comment)中包含Jira Key,相应的代码提交信息也会显示在Issue中,从而建立 Issue 与相应的代码的可视关系。实现敏捷与 DevOps 里倡导的可追踪性。
- Confluence 的使用原则
Confluence 是基于 Wiki 精神设计的,任何人都可以对内容进行修改和贡献。所以在建立 Confluence 文档时,不必拘泥于一次写对,持续地更新、修正恰恰符合“先完成、再完美”的敏捷原则。

另外,我强烈建议大家在编写 Confluence 文档时,善用 Header 来对文档进行结构化处理。Confluence 支持5级 Header,便于建立不同的章节和层次结构,配合目录(Table of Content)功能,Confluence 会自动根据文档的 Header 生成相应的目录和书签,便于定位某个章节。
由于 Confluence 具有强大的灵活性,文档所处的位置可以通过 Move 功能随意移动,不建议花太多时间设计文档间的关系。
在去中心化的原则下,每个人都可以贡献内容,所以 Confluence 的文档体系建立一定是自底向上的,这不可避免地会带来文档的碎片化和内容的重复建设。但不必对此过于担心,其实互联网也是这样的,我们不还是活得好好的,能通过互联网获取到我们所需要的信息吗?强大的搜索功能可以帮助我们找到需要的内容。
善用标签,也就是在编写某类文档有加上相应的关键字做标签,然后通过标签把相应的文档聚合在某个地方,方便查阅,是更高效的方法。
- Jira 与 Confluence 的实时互动
全球 76% 的客户表示,将这两种产品相结合可以帮助他们更快交付项目!****我们一起来看一段视频:
只要把某个 Jira Issue 的链接地址贴到 Confluence 页面里,该 Issue 的标题和实时状态会自动显示在 Confluence 页面中。

我们建议把项目中相对静态的信息,如项目的整体框架或者从项目拆分到特性等内容放在 Confluence 中。
然后把对应的比较动态的具体工件通过 Jira 来追踪,然后把 Jira Issue 的链接放在 Confluence 页面中,建立两者的对应关系,整个项目的脉络,一目了然。
而且在 Jira 中的状态更新在 Confluence 页面中也能实时反映。或者通过 Confluence 的表格功能建立用户故事地图,然后把生成的用户故事通过 Jira 记录,并把链接放在 Confluence 里的地图细节中。
简单来说,就是静态的内容放 Confluence,动态的内容放 Jira,并把两者链接起来。
我们不时需要给客户提交项目报告。过去,我们需要手动整理这些信息,费时费力。通过这两大利器,我们可以轻松构建实时的报告和仪表盘,只消一次搭建的功夫。
我们可以在 Confluence 中把整个 Jira 列表引入,列表的内容可以通过 JQL 灵活设定。也可以把列表转换为图表,建立可视化很强的仪表盘。

敏捷转型是思维转型
最后我想强调的是,敏捷转型是思维转型。我们需要:
深入理解敏捷价值观——在前文提到“去中心化、集体讨论、信息共享、灵活、透明、可视化”等原则才是敏捷转型的思想武器;
运用具体实践和工具落实敏捷价值观——JIRA和Confluence可以帮助我们践行敏捷原则和价值观;
持续回顾与改善——没有放之四海而皆准的方法,通过针对具体交付问题的持续回顾、总结,才能帮我们找到最合适自己的方法和工具。
关于作者
刘 华 (Kenneth)
就职于世界500强银行,负责基金服务业务软件开发与交付,DevOps团队负责人
敏捷、精益、DevOps专家
精通极限编程、Scrum、看板方法、测试驱动开发、持续集成、行为驱动开发、DevOps工具栈
曾在GDevOps、DevOpsDays Meetup、中国软件技术大会、ArchSummit等论坛发表主题演讲
著有《猎豹行动:硝烟中的敏捷转型之旅》一书

小说体敏捷/DevOps转型教科书
和实战经验分享
购书指南
—
纸质书、电子书在京东、当当、亚马逊、微信读书等渠道已全面上架,搜索关键字“猎豹 敏捷”即可找到。
有声书已登录喜马拉雅、微信读书,适合路上听书的你。
关注公众号看其他原创作品

觉得好看,点个“在看”或转发给朋友们,欢迎你留言。
本文分享自微信公众号 - 敏于思 捷于行(kennethz2016)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











