压缩参数配置
- 要在Hadoop中启用压缩,可以在
mapred-site.xml中配置如下参数
| 默认值 |
阶段 |
参数 |
建议 |
| org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.Lz4Codec |
输入压缩 |
io.compression.codecs (在core-site.xml中配置) |
Hadoop使用文件扩展名判断是否支持某种编解码器 |
| false |
mapper输出 |
mapreduce.map.output.compress |
这个参数设为true启用压缩 |
| org.apache.hadoop.io.compress.DefaultCodec |
mapper输出 |
mapreduce.map.output.compress.codec |
使用LZO、LZ4或snappy编解码器在此阶段压缩数据 |
| false |
reducer输出 |
mapreduce.output.fileoutputformat.compress |
这个参数设为true启用压缩 |
| org.apache.hadoop.io.compress. DefaultCodec |
reducer输出 |
mapreduce.output.fileoutputformat.compress.codec |
使用标准工具或者编解码器,如gzip和bzip2 |
| RECORD |
reducer输出 |
mapreduce.output.fileoutputformat.compress.type |
SequenceFile输出使用的压缩类型:NONE和BLOCK |
Map输出阶段压缩
- 开启map输出阶段压缩可以减少job中map和Reduce Task间数据传输量
案例实操
# 开启hive中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
# 开启mapreduce中map输出压缩功能
set mapreduce.map.output.compress=true;
# 设置mapreduce中map输出数据的压缩方式
set mapreduce.map.output.compress.codec=
org.apache.hadoop.io.compress.SnappyCodec;
# 执行查询语句
select count(ename) name from emp;
Reduce输出阶段压缩
# 开启hive最终输出数据压缩功能
set hive.exec.compress.output=true;
# 开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
# 设置mapreduce最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec =
org.apache.hadoop.io.compress.SnappyCodec;
# 设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
# 测试一下输出结果是否是压缩文件
insert overwrite local directory
'/opt/module/hive/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;
文件存储格式
列式存储和行式存储
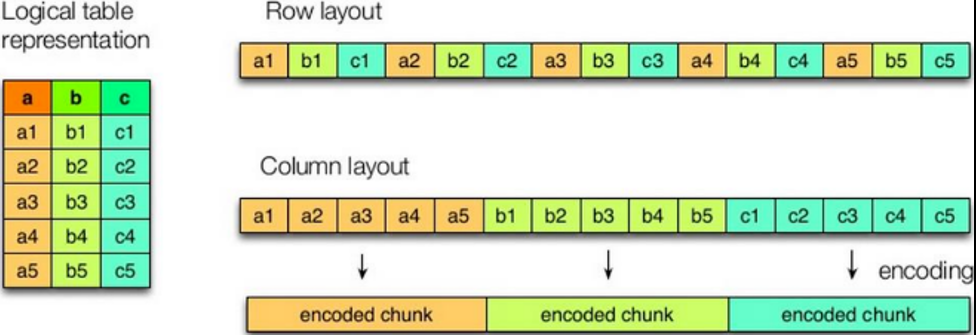
特点
- 行存储:查询速度更快
- 列存储:可以针对性设计更好的设计压缩算法
textfile和sequencefile都是基于行存储的orc和parquet是基于列式存储的
Orc格式
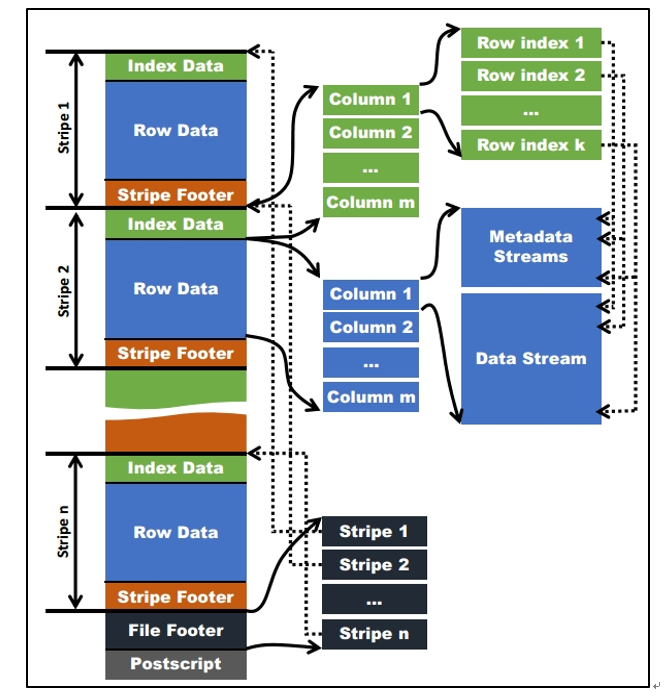
Parquet格式
- 以二进制方式存储,不可以直接读取
- 文件中包括该文件的数据和元数据,因此Parquet格式的文件是自解析的
存储和压缩结合
- 在实际项目开发中,Hive表的数据存储格式一般选择orc或parquet
- 压缩方式一般选择snappy,lzo
执行计划(Explain)
explain select * from emp;
Fetch抓取
- Hive中对某些情况的查询可以不使用MapReduce计算
- 例如select * from employees
- 这种情况下Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台
案例实操
# 把 hive.fetch.task.conversion 设置成 none,如下查询都会走mapreduce
# 设置成more,都不会走mapreduce
set hive.fetch.task.conversion=more;
select * from emp;
select ename from emp;
select ename from emp limit 3;
本地模式
# 开启本地mr
set hive.exec.mode.local.auto=true;
# 设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
# 设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10;
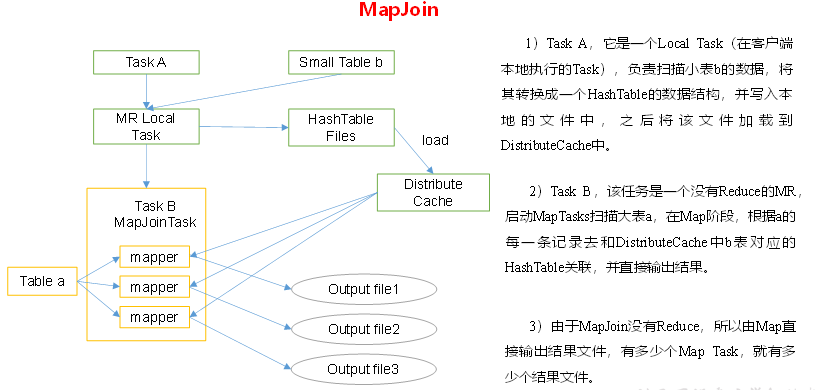
小表大表Join(MapJoin)
# 设置自动选择Mapjoin
set hive.auto.convert.join = true; 默认为true
# 大表小表的阈值设置(默认25M以下认为是小表)
set hive.mapjoin.smalltable.filesize = 25000000;
MapJoin工作机制
大表Join大表
空key过滤
- 有时join超时是因为某些key对应的数据太多
- 而相同的key都会发送到相同的reducer上,导致内存不够
- 很多情况下,这些key对应的数据是异常的数据
- 我们需要在SQL语句中进行过滤,例如key对应的字段为空
空key转换
- 有时候虽然某个key为空对应的数据很多,但相应的数据并不是异常数据
- 此时我们可以为key为空的字段赋一个随机的值,使数据随机均匀地分布到不同的reducer上
Group by
- 默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了
- 可以在Map端进行部分聚合,最后在Reduce端得出最终结果
# 是否在Map端进行聚合,默认为True
set hive.map.aggr = true
# 在Map端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000
# 有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true
Count(Distinct)去重统计
- 数据量大的情况下,由于count distinct操作需要用到一个reduce task来完成
- 这个reduce需要处理的数据量太大,就会导致整个job很难完成
- 一般count distinct使用先group by再count的方式替换
合理设置Map及Reduce数
是不是map数越多越好?
- 答案是否定的
- 如果一个任务有很多个小文件,则每个小文件也会被当作一个块,用一个map任务来完成
- 而一个map任务启动和初始化的时间远大于逻辑处理时间,就会造成很大的资源浪费
- 而且,同时可执行的map数是受限的
是不是保证每个map处理接近128M的文件快,就可以高枕无忧了?
- 答案是不一定
- 比如有一个127M的文件,正常会用一个map去完成
- 但这个文件只有一个或两个小字段,却有几千万的记录
- 如果map处理的逻辑比较复杂,用一个map任务去做,肯定比较耗时
- 此时应该增加map数
小文件进行合并
# 在map执行前合并小文件,减少map数
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
# 在map-only任务结束时合并小文件,默认true
SET hive.merge.mapfiles = true;
# 在map-reduce任务结束时合并小文件,默认false
SET hive.merge.mapredfiles = true;
# 合并文件的大小,默认256M
SET hive.merge.size.per.task = 268435456;
# 当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge
SET hive.merge.smallfiles.avgsize = 16777216;
合理设置Reduce数
# 方式一
# 每个Reduce处理的数据量默认是256MB
hive.exec.reducers.bytes.per.reducer=256000000
# 每个任务最大的reduce数,默认为1009
hive.exec.reducers.max=1009
# 计算reducer数的公式
N=min(参数2,总输入数据量/参数1)
# 方式二
# mapred-default.xm
set mapreduce.job.reduces = 15;
reduce个数并不是越多越好
- 过多的启动和初始化reduce会消耗时间和资源
- 有多少个reduce,就会有多少个小文件,如果这些小文件作为下一个任务的输入,也会出现小文件过多的问题
并行执行
# 打开任务并行执行
set hive.exec.parallel=true;
# 同一个sql允许最大并行度,默认为8
set hive.exec.parallel.thread.number=16;
严格模式
分区表不使用分区过滤
# 对于分区表,除非where语句中含有分区字段过滤条件来限制范围,否则不允许执行
hive.strict.checks.no.partition.filter=true;
order by没有 limit过滤
# 对于使用了order by语句的查询,要求必须使用limit语句
hive.strict.checks.orderby.no.limit=true;
笛卡尔积
# 会限制笛卡尔积的查询
hive.strict.checks.cartesian.product=true
