
目录
- 前言
- 编写代码
- 总结
前言
本次我们使用selenium来获取网页中的股票id,然后根据这些id拼接出url,访问相应的url获取到我们想要的数据,存储到excel里。
不多说,先上结果图。
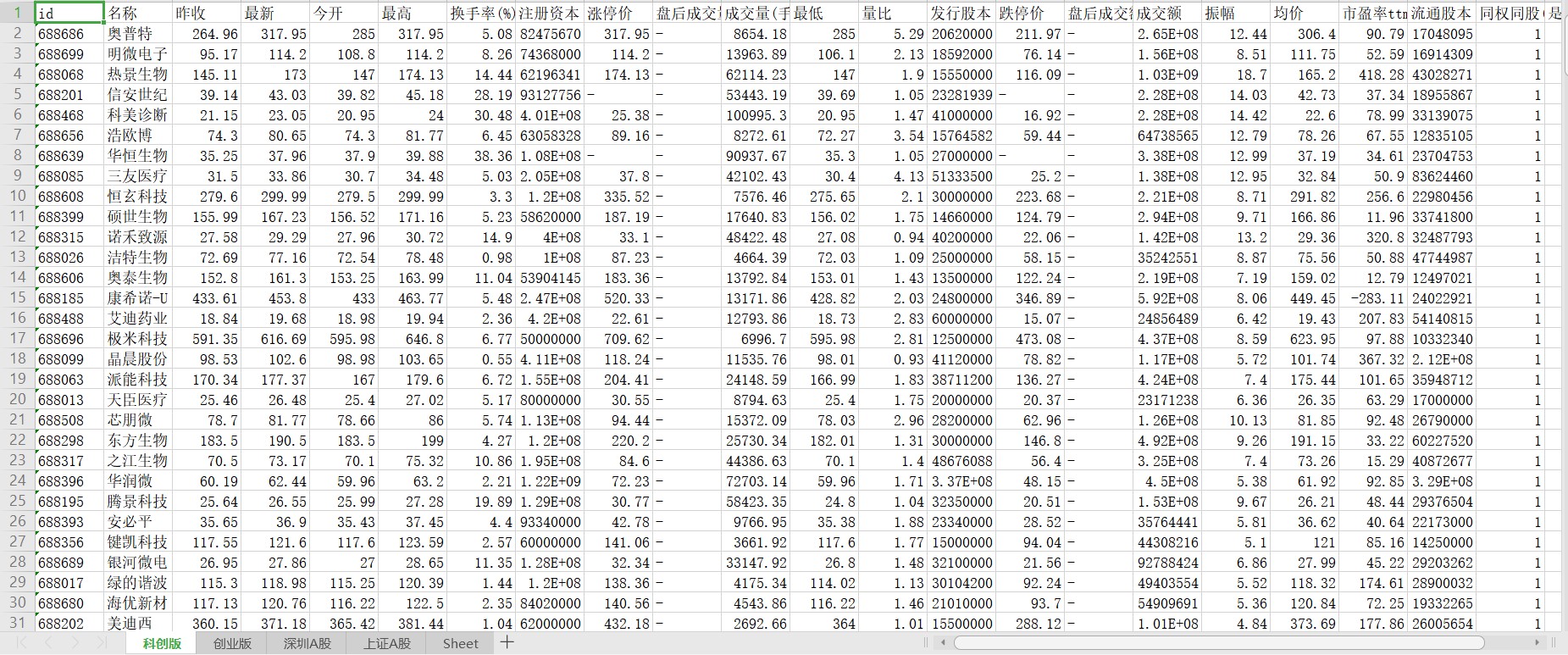
编写代码
1.分析网页
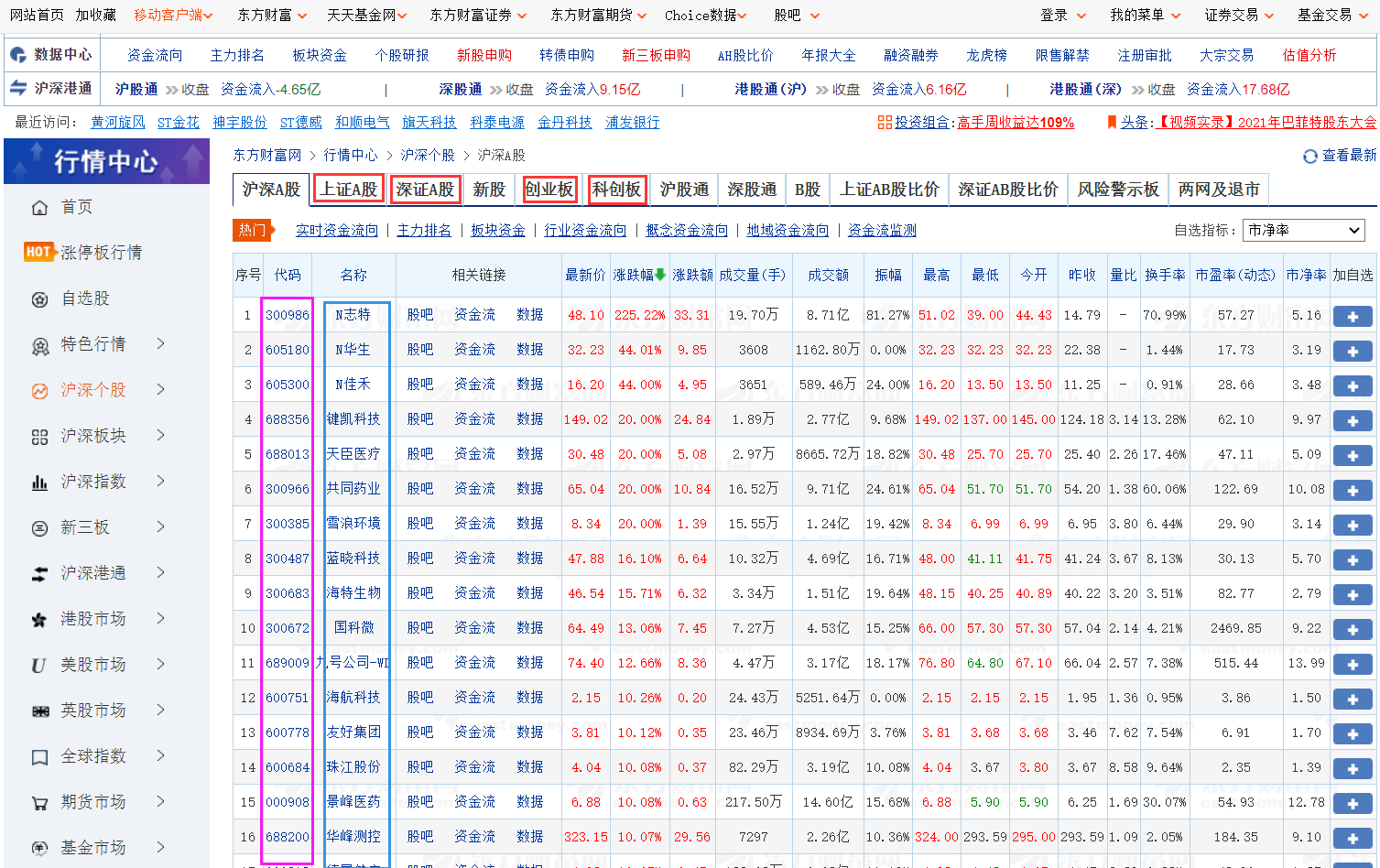 本次爬取的网站是东方财富网中的上证A股、深证A股、创业版、科创版4个板块中所有股票的行情。例如N志特我们需要的就是棕色框框内的内容。
本次爬取的网站是东方财富网中的上证A股、深证A股、创业版、科创版4个板块中所有股票的行情。例如N志特我们需要的就是棕色框框内的内容。
 其实股票id可以通过这个网址获取,速度更快,但第一次时我还是傻乎乎地使用了selenium来获取。
其实股票id可以通过这个网址获取,速度更快,但第一次时我还是傻乎乎地使用了selenium来获取。
 不过也没关系,我们可以尝试着使用一下selenium这个自动化工具。
当然,使用selenium获取我们还需要模拟点击下一页,因为一页上的股票是展示不全的。
获取到股票id后,我们就可以拼接出对应的url了。
比如N志特的url就是http://quote.eastmoney.com/sz300986.html 其中的sz是对应的板块,300986就是它的股票id。
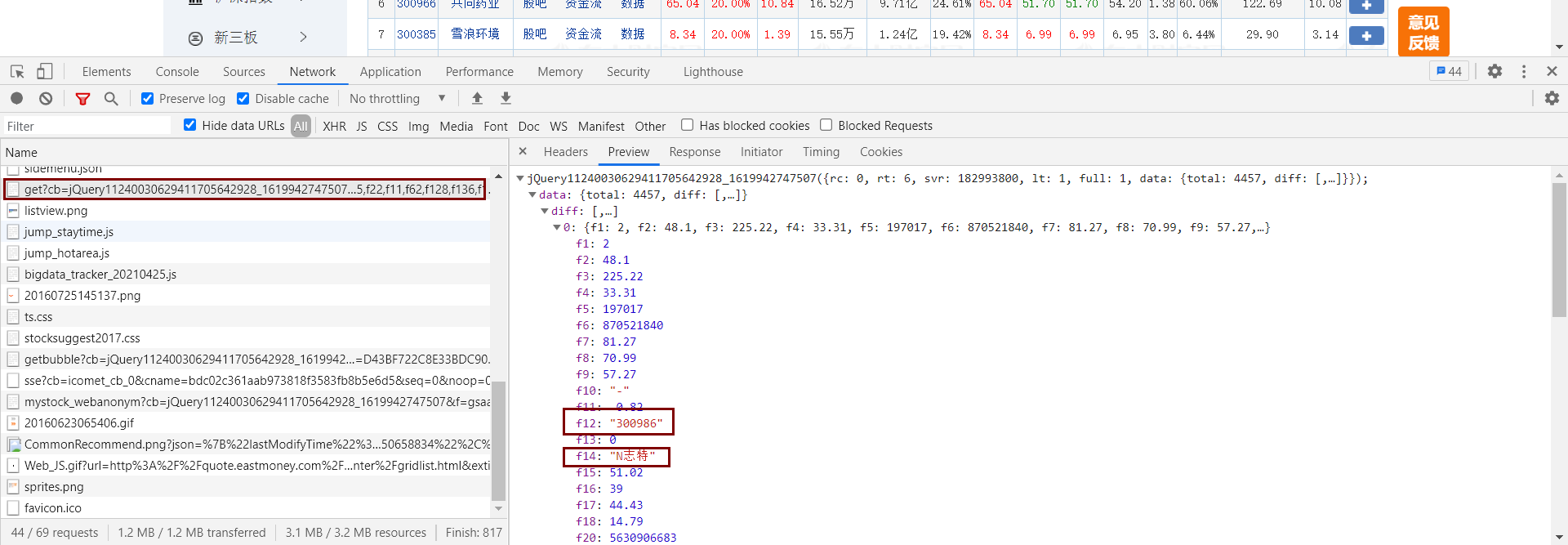
进入到对应的股票界面,进行抓包。我们发现所需要的数据在这个地方。
不过也没关系,我们可以尝试着使用一下selenium这个自动化工具。
当然,使用selenium获取我们还需要模拟点击下一页,因为一页上的股票是展示不全的。
获取到股票id后,我们就可以拼接出对应的url了。
比如N志特的url就是http://quote.eastmoney.com/sz300986.html 其中的sz是对应的板块,300986就是它的股票id。
进入到对应的股票界面,进行抓包。我们发现所需要的数据在这个地方。
 但有个问题,我们不知道这些数据的对应关系,可能有人说可以将这里的数据和网页上的数据一个个比对,这样是可以,但很麻烦而且不准确,所以我们还是到对应的js文件里看看是如何处理这些数据的吧。
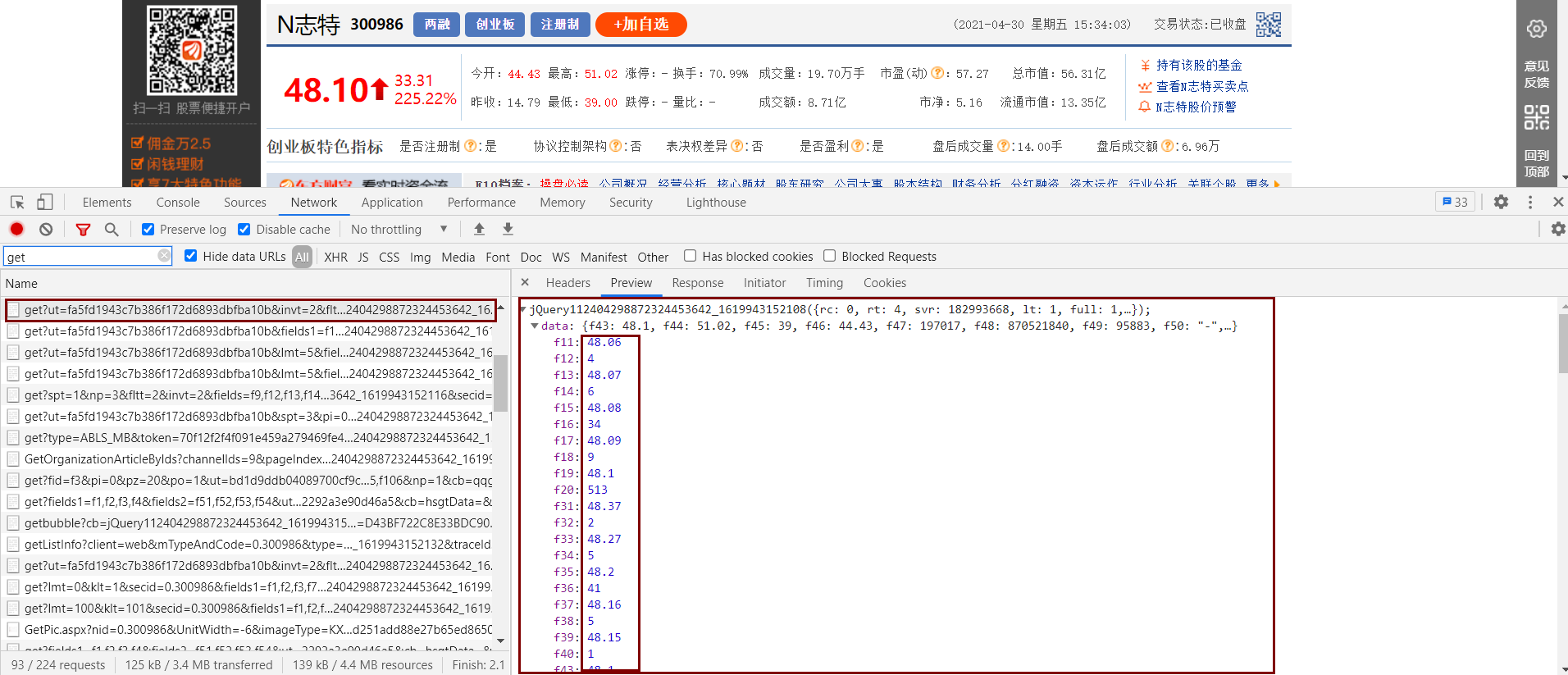
在调试界面按ctrl+shift+F打开全局搜索,然后搜索一个字段,我们发现我们找到了所需要的对应关系,不放心的话按照这个将数据和网页上的进行对比,发现没错,就是这个!
但有个问题,我们不知道这些数据的对应关系,可能有人说可以将这里的数据和网页上的数据一个个比对,这样是可以,但很麻烦而且不准确,所以我们还是到对应的js文件里看看是如何处理这些数据的吧。
在调试界面按ctrl+shift+F打开全局搜索,然后搜索一个字段,我们发现我们找到了所需要的对应关系,不放心的话按照这个将数据和网页上的进行对比,发现没错,就是这个!
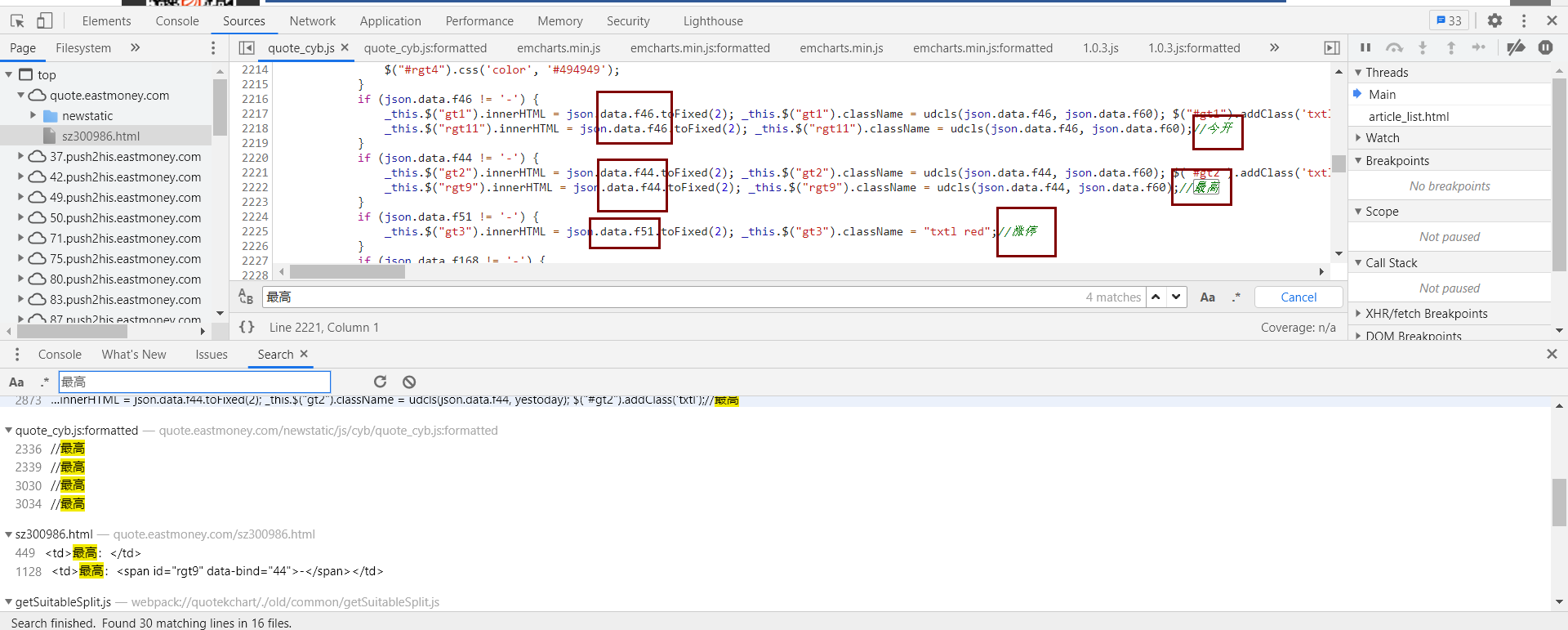 接下来我们就可以开始写代码了!
接下来我们就可以开始写代码了!
2.编写代码
首先是获取股票id页面源代码的selenium使用函数,注意一下里面的time.sleep函数里的值和你浏览器渲染网页的速度有关,如果太小,就会出现网页没渲染完代码就获取到源代码进行下一步操作了,这样会有很大的问题。
def get_html(url):
#获取项目页面的源码
page_sources = []
while True:
try:
#打开谷歌浏览器
wd = webdriver.Chrome()
#发起请求
wd.get(url)
page_sources.append(wd.page_source)
while True:
#寻找加载更多按钮进行点击
html = wd.page_source
h1 = etree.HTML(html)
button = h1.xpath('//a[@class="next paginate_button"]')
#找不到按钮退出
if len(button) == 0:
break
#寻找结束按钮
later = h1.xpath('//a[@class="next paginate_button disabled"]')
if len(later) == 0:
#找不到结束按钮则加载更多
i = wd.find_element_by_xpath('//*[@class="next paginate_button"]')
i.click()
time.sleep(0.5)
page_sources.append(wd.page_source)
else:
break
except BaseException:
wd.quit()
time.sleep(0.5)
print("正在重新获取")
else:
# 正常结束则关闭浏览器
wd.quit()
time.sleep(0.5)
break
return page_sources接下来是从网页源代码中解析出我们需要的股票id,至于里面的td是股票开头的序列号。
def get_ids(page_sources):
#解析出id
id_lists = []
b = 1
for page_source in page_sources:
ids1 = []
xp = etree.HTML(page_source)
td = xp.xpath('//table[@id="table_wrapper-table"]/tbody/tr/td[1]/text()')
ids = xp.xpath('//table[@id="table_wrapper-table"]/tbody/tr/td[2]/a/text()')
# urls = xp.xpath('//table[@id="table_wrapper-table"]/tbody/tr/td[2]/a/@href')
for i in range(len(ids)):
# urls[i] = 'http:' + str(urls[i])
# urls1.append({td[i]:urls[i]})
ids1.append({td[i]: ids[i]})
# print(td,urls)
id_lists.append({str(b):ids1})
b += 1
return id_lists然后是根据股票id获取到股票的基本行情。
def get_data2(id,i):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.76',
}
urls = [
'http://push2.eastmoney.com/api/qt/stock/get?ut=fa5fd1943c7b386f172d6893dbfba10b&fltt=2&invt=2&volt=2&fields=f43,f57,f58,f169,f170,f46,f44,f51,f168,f47,f164,f163,f116,f60,f45,f52,f50,f48,f167,f117,f71,f161,f49,f530,f135,f136,f137,f138,f139,f141,f142,f144,f145,f147,f148,f140,f143,f146,f149,f55,f62,f162,f92,f173,f104,f105,f84,f85,f183,f184,f185,f186,f187,f188,f189,f190,f191,f192,f107,f111,f86,f177,f78,f110,f262,f263,f264,f267,f268,f250,f251,f252,f253,f254,f255,f256,f257,f258,f266,f269,f270,f271,f273,f274,f275,f127,f199,f128,f198,f259,f260,f261,f171,f277,f278,f279,f288,f292,f182&secid=1.',
'http://push2.eastmoney.com/api/qt/stock/get?ut=fa5fd1943c7b386f172d6893dbfba10b&invt=2&fltt=2&fields=f43,f57,f58,f169,f170,f46,f44,f51,f168,f47,f164,f163,f116,f60,f45,f52,f50,f48,f167,f117,f71,f161,f49,f530,f135,f136,f137,f138,f139,f141,f142,f144,f145,f147,f148,f140,f143,f146,f149,f55,f62,f162,f92,f173,f104,f105,f84,f85,f183,f184,f185,f186,f187,f188,f189,f190,f191,f192,f107,f111,f86,f177,f78,f110,f260,f261,f262,f263,f264,f267,f268,f250,f251,f252,f253,f254,f255,f256,f257,f258,f266,f269,f270,f271,f273,f274,f275,f127,f199,f128,f193,f196,f194,f195,f197,f80,f280,f281,f282,f284,f285,f286,f287,f292,f293,f181,f294,f295,f279,f288&secid=0.',
]
url = urls[i]+id
data = requests.get(url,headers = headers).json()['data']
return data接着是将股票数据进行处理一下。
def jianxi(data,i):
new_data = {}
ys = [
{
'f57': 'id',
'f58': '名称',
'f60': '昨收',
'f43': '最新',
'f46': '今开',
'f44': '最高',
'f168': '换手率(%)',
'f277': '注册资本',
'f51': '涨停价',
'f260': '盘后成交量(手)',
'f47': '成交量(手)',
'f45': '最低',
'f50': '量比',
'f278': '发行股本',
'f52': '跌停价',
'f261': '盘后成交额',
'f48': '成交额',
'f171': '振幅',
'f71': '均价',
'f164': '市盈率ttm',
'f85': '流通股本',
'f279': '同权同股(1为是)',
'f288': '是否盈利(0为是,1为否)',
},
{
'f57': 'id',
'f58': '名称',
'f60': '昨收',
'f43': '最新',
'f46': '今开',
'f44': '最高',
'f168': '换手率(%)',
'f51': '涨停价',
'f260': '盘后成交量(手)',
'f47': '成交量(手)',
'f45': '最低',
'f50': '量比',
'f52': '跌停价',
'f261': '盘后成交额',
'f48': '成交额',
'f71': '均价',
'f164': '市盈率ttm',
'f85': '流通股本',
'f293': '同权同股->是否有表决权差异(1为是)',
'f288': '是否盈利(0为是,1为否)',
'f167':'市净',
'f116':'总市值',
'f117':'流通市值'
}
]
for n in ys[i].keys():
# print(n)
new_data[ys[i][n]] = data[n]
return new_data最后是一个写入表格的函数。
def write_xls(name,data,i):
wb = load_workbook('股票.xlsx')
ws = wb.create_sheet(name,0)
ys = [
{
'A': 'id',
'B': '名称',
'C': '昨收',
'D': '最新',
'E': '今开',
'F': '最高',
'G': '换手率(%)',
'H': '注册资本',
'I': '涨停价',
'J': '盘后成交量(手)',
'K': '成交量(手)',
'L': '最低',
'M': '量比',
'N': '发行股本',
'O': '跌停价',
'P': '盘后成交额',
'Q': '成交额',
'R': '振幅',
'S': '均价',
'T': '市盈率ttm',
'U': '流通股本',
'V': '同权同股(1为是)',
'W': '是否盈利(0为是,1为否)',
},
{
'A': 'id',
'B': '名称',
'C': '昨收',
'D': '最新',
'E': '今开',
'F': '最高',
'G': '换手率(%)',
'H': '涨停价',
'I': '盘后成交量(手)',
'J': '成交量(手)',
'K': '最低',
'L': '量比',
'M': '跌停价',
'N': '盘后成交额',
'O': '成交额',
'P': '均价',
'Q': '市盈率ttm',
'R': '流通股本',
'S': '同权同股->是否有表决权差异(1为是)',
'T': '是否盈利(0为是,1为否)',
'U': '市净',
'V': '总市值',
'W': '流通市值'
}
]
for key, value in ys[i].items():
ws[key + '1'] = value
for n in range(len(data)):
ws[key+str(n+2)] = data[n][value]
wb.save('股票.xlsx')3.总的代码
#coding:utf-8
from openpyxl import Workbook
from openpyxl import load_workbook
from selenium import webdriver
from lxml import etree
import requests
import time
def get_html(url):
#获取项目页面的源码
page_sources = []
while True:
try:
#打开谷歌浏览器
wd = webdriver.Chrome()
#发起请求
wd.get(url)
page_sources.append(wd.page_source)
while True:
#寻找加载更多按钮进行点击
html = wd.page_source
h1 = etree.HTML(html)
button = h1.xpath('//a[@class="next paginate_button"]')
#找不到按钮退出
if len(button) == 0:
break
#寻找结束按钮
later = h1.xpath('//a[@class="next paginate_button disabled"]')
if len(later) == 0:
#找不到结束按钮则加载更多
i = wd.find_element_by_xpath('//*[@class="next paginate_button"]')
i.click()
time.sleep(0.5)
page_sources.append(wd.page_source)
else:
break
except BaseException:
wd.quit()
time.sleep(0.5)
print("正在重新获取")
else:
# 正常结束则关闭浏览器
wd.quit()
time.sleep(0.5)
break
return page_sources
def get_ids(page_sources):
#解析出id
id_lists = []
b = 1
for page_source in page_sources:
ids1 = []
xp = etree.HTML(page_source)
td = xp.xpath('//table[@id="table_wrapper-table"]/tbody/tr/td[1]/text()')
ids = xp.xpath('//table[@id="table_wrapper-table"]/tbody/tr/td[2]/a/text()')
# urls = xp.xpath('//table[@id="table_wrapper-table"]/tbody/tr/td[2]/a/@href')
for i in range(len(ids)):
# urls[i] = 'http:' + str(urls[i])
# urls1.append({td[i]:urls[i]})
ids1.append({td[i]: ids[i]})
# print(td,urls)
id_lists.append({str(b):ids1})
b += 1
return id_lists
def get_html2(id_list,i):
datas = []
for pages in id_list:
for page in pages.values(): #对于每一页
for id in page: #对于每一个链接
new_id = list(id.values())[0]
print(new_id)
data = get_data2(new_id,i)
new_data = jianxi(data,i)
print(new_data)
datas.append(new_data)
time.sleep(0.5)
return datas
def jianxi(data,i):
new_data = {}
ys = [
{
'f57': 'id',
'f58': '名称',
'f60': '昨收',
'f43': '最新',
'f46': '今开',
'f44': '最高',
'f168': '换手率(%)',
'f277': '注册资本',
'f51': '涨停价',
'f260': '盘后成交量(手)',
'f47': '成交量(手)',
'f45': '最低',
'f50': '量比',
'f278': '发行股本',
'f52': '跌停价',
'f261': '盘后成交额',
'f48': '成交额',
'f171': '振幅',
'f71': '均价',
'f164': '市盈率ttm',
'f85': '流通股本',
'f279': '同权同股(1为是)',
'f288': '是否盈利(0为是,1为否)',
},
{
'f57': 'id',
'f58': '名称',
'f60': '昨收',
'f43': '最新',
'f46': '今开',
'f44': '最高',
'f168': '换手率(%)',
'f51': '涨停价',
'f260': '盘后成交量(手)',
'f47': '成交量(手)',
'f45': '最低',
'f50': '量比',
'f52': '跌停价',
'f261': '盘后成交额',
'f48': '成交额',
'f71': '均价',
'f164': '市盈率ttm',
'f85': '流通股本',
'f293': '同权同股->是否有表决权差异(1为是)',
'f288': '是否盈利(0为是,1为否)',
'f167':'市净',
'f116':'总市值',
'f117':'流通市值'
}
]
for n in ys[i].keys():
# print(n)
new_data[ys[i][n]] = data[n]
return new_data
def get_data2(id,i):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.76',
}
urls = [
'http://push2.eastmoney.com/api/qt/stock/get?ut=fa5fd1943c7b386f172d6893dbfba10b&fltt=2&invt=2&volt=2&fields=f43,f57,f58,f169,f170,f46,f44,f51,f168,f47,f164,f163,f116,f60,f45,f52,f50,f48,f167,f117,f71,f161,f49,f530,f135,f136,f137,f138,f139,f141,f142,f144,f145,f147,f148,f140,f143,f146,f149,f55,f62,f162,f92,f173,f104,f105,f84,f85,f183,f184,f185,f186,f187,f188,f189,f190,f191,f192,f107,f111,f86,f177,f78,f110,f262,f263,f264,f267,f268,f250,f251,f252,f253,f254,f255,f256,f257,f258,f266,f269,f270,f271,f273,f274,f275,f127,f199,f128,f198,f259,f260,f261,f171,f277,f278,f279,f288,f292,f182&secid=1.',
'http://push2.eastmoney.com/api/qt/stock/get?ut=fa5fd1943c7b386f172d6893dbfba10b&invt=2&fltt=2&fields=f43,f57,f58,f169,f170,f46,f44,f51,f168,f47,f164,f163,f116,f60,f45,f52,f50,f48,f167,f117,f71,f161,f49,f530,f135,f136,f137,f138,f139,f141,f142,f144,f145,f147,f148,f140,f143,f146,f149,f55,f62,f162,f92,f173,f104,f105,f84,f85,f183,f184,f185,f186,f187,f188,f189,f190,f191,f192,f107,f111,f86,f177,f78,f110,f260,f261,f262,f263,f264,f267,f268,f250,f251,f252,f253,f254,f255,f256,f257,f258,f266,f269,f270,f271,f273,f274,f275,f127,f199,f128,f193,f196,f194,f195,f197,f80,f280,f281,f282,f284,f285,f286,f287,f292,f293,f181,f294,f295,f279,f288&secid=0.',
]
url = urls[i]+id
data = requests.get(url,headers = headers).json()['data']
return data
def write_xls(name,data,i):
wb = load_workbook('股票.xlsx')
ws = wb.create_sheet(name,0)
ys = [
{
'A': 'id',
'B': '名称',
'C': '昨收',
'D': '最新',
'E': '今开',
'F': '最高',
'G': '换手率(%)',
'H': '注册资本',
'I': '涨停价',
'J': '盘后成交量(手)',
'K': '成交量(手)',
'L': '最低',
'M': '量比',
'N': '发行股本',
'O': '跌停价',
'P': '盘后成交额',
'Q': '成交额',
'R': '振幅',
'S': '均价',
'T': '市盈率ttm',
'U': '流通股本',
'V': '同权同股(1为是)',
'W': '是否盈利(0为是,1为否)',
},
{
'A': 'id',
'B': '名称',
'C': '昨收',
'D': '最新',
'E': '今开',
'F': '最高',
'G': '换手率(%)',
'H': '涨停价',
'I': '盘后成交量(手)',
'J': '成交量(手)',
'K': '最低',
'L': '量比',
'M': '跌停价',
'N': '盘后成交额',
'O': '成交额',
'P': '均价',
'Q': '市盈率ttm',
'R': '流通股本',
'S': '同权同股->是否有表决权差异(1为是)',
'T': '是否盈利(0为是,1为否)',
'U': '市净',
'V': '总市值',
'W': '流通市值'
}
]
for key, value in ys[i].items():
ws[key + '1'] = value
for n in range(len(data)):
ws[key+str(n+2)] = data[n][value]
wb.save('股票.xlsx')
if __name__ == '__main__':
wb = Workbook()
wb.save('股票.xlsx')
urls = [('上证A股','http://quote.eastmoney.com/center/gridlist.html#sh_a_board',0),
('深圳A股','http://quote.eastmoney.com/center/gridlist.html#sz_a_board',1),
('创业版','http://quote.eastmoney.com/center/gridlist.html#gem_board',1),
('科创版','http://quote.eastmoney.com/center/gridlist.html#kcb_board',0)
]
for name,url,i in urls: #对于每一个板块
print(name)
page_sources = get_html(url)
id_list = get_ids(page_sources)
datas = get_html2(id_list,i)
# print(datas)
print(len(datas))
write_xls(name,datas,i)总结
这次的代码爬到的数据量还是有点多的,爬取的速度比较慢,后续可能会采用多线程进行优化,提高爬取的速度。 需要股票数据进行分析的小伙伴们可以使用这次的代码来获取数据。 对于不使用selenium获取股票id的函数我在下一篇文章中会给出。