推荐
专栏
教程
课程
飞鹅
本次共找到10000条
时间序列数据
相关的信息
Wesley13
•
4年前
java 日志的数据脱敏
思路1。在model层进行处理,直接重写get方法,在写一个getPlain获取明文方法。(缺点:数据库写入和json序列化传递时使用的都是密文) 2.利用日志组件过滤特定的key,去进行脱敏(缺点:对所有的日志输出全部要正则匹配,非常耗时。)由1,2的利弊,肯定会选择1,然后考虑一种实现(在model层定义方法,获取它的一个复制类,复制
Wesley13
•
4年前
java小白到架构师技术图谱(整理全网,持续更新)
本文整理于github上各大star大神仓库。并根据自己的理解重新进行了整理本文已经收录于https://github.com/fengdongdongwsn/architectjava一、计算机基础1、数据结构(1)基本数据结构数据结构基本概念(时间复杂度和空间复杂度的计算方法)
似梦清欢
•
3年前
数据结构概述
1.有序列表逻辑结构和存储结构!image(https://imghelloworld.osscnbeijing.aliyuncs.com/imgs/f08fe88e8457bac682c1ae8f33817873.png)四种逻辑结构
Stella981
•
4年前
PostgreSQL 恢复大法
转载自:https://yq.aliyun.com/articles/582880背景一个较大的数据库,如何只恢复一部分数据(例如只恢复某个DB)。如果访问有坏块的表。如何从无法启动的数据库中,恢复到有意义的数据。如何正确的进行备份。如何恢复到过去的某个时间点。恢复部分数据库《PostgreSQLSelect
Stella981
•
4年前
Hive中使用row_number() over()创建自增主键
虽然hive中的表没有主键一说,但是实际数据开发中经常需要将hive中计算好的表导出到mysql库中供业务使用或开发调用,而mysql表是需要有主键的,在hive中我们可以使用row\_number()over()窗口函数来生成一个自增序列的字段,在将表导出到mysql库中的时候就可以指定该字段为主键,使用起来还是挺方便的。select
Wesley13
•
4年前
mysql 查询近7天数据,缺失补0
相信很多人的项目都有这种需求,就是查询近7天的记录,但是这7天总有那么几天是没数据的,所以缺失的只能补0 下面的代码不知道能不能看懂,我简单的说一下思路1)先查询红色字体的近7天,再转换成日期2)我的字段使用的是时间戳的方式去保存,只能是先数据库字段先转日期2.1)先查询自己想要的数据,用每天分组,计算好总数后2.2)时间戳字段先转日期
Stella981
•
4年前
Python3编写网络爬虫10
3.CSV文件存储CSV全称CommaSeparatedValues中文叫做逗号分隔值或者字符分隔值,文件以纯文本形式存储表格数据。文件是一个字符序列可以由任意数目的记录组成相当于一个结构化表的纯文本形式,它比Excel更加简洁,XLS文本是电子表格,包含文本,数值,公式和格式等内容,CSV都没有就是特定的字符分隔纯文本,结构简
Wesley13
•
4年前
Mysql分库分表方案
Mysql分库分表方案1.为什么要分表:当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。mysql中有一种机制是表锁定和行锁定,是为了保证数据的完整性。表锁定表示你们都不能对这张表进行操作,必须等我对表操作完才行。行锁定也一样,别的sql必须等
Wesley13
•
4年前
mysql连接池不能回避的wait timeout问题(转)
起因我们的项目组一直在使用albianj作为开发框架在开发应用。使用至今倒也是没有出现很大的问题,但最近加过监控的接口基本上都会在使用一段时间后,突然之间执行数据库操作变得很慢。虽然会变慢,但持续的时间比较短,一般1分钟左右,然后会自动恢复正常。但是过了一段时间,这个现象又会出现,周而复始。从监控看,发生的时间点并无规律,有的时候一天发生3次,有的
3A网络
•
3年前
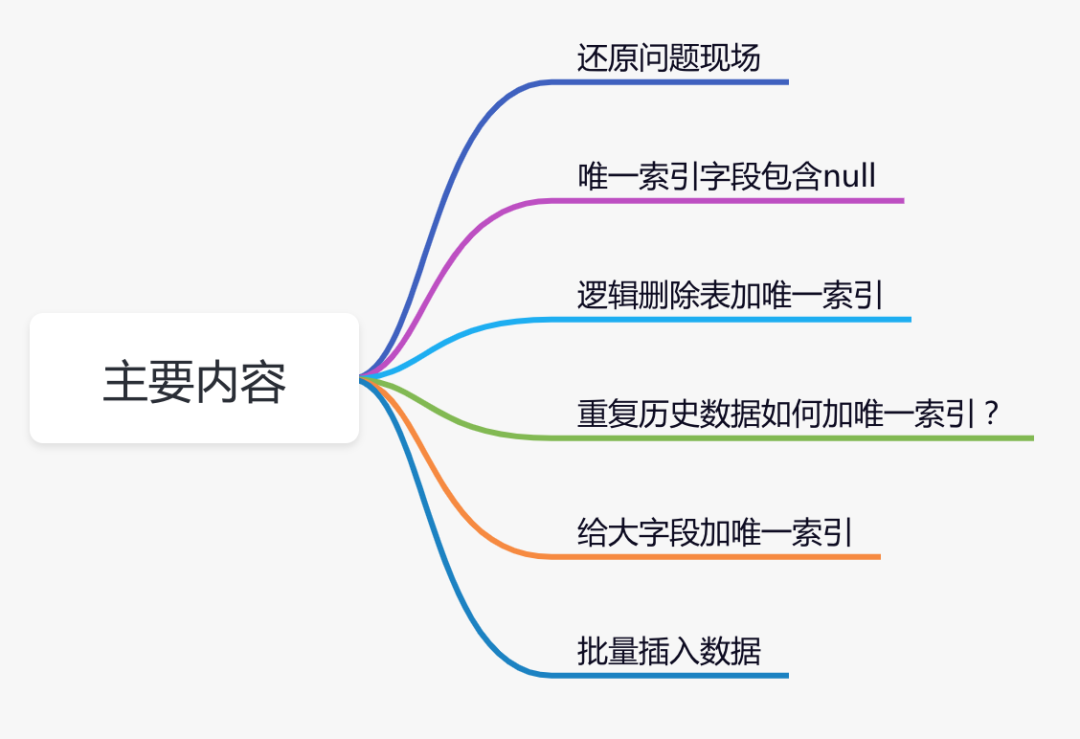
明明加了唯一索引,为什么还是产生了重复数据?
明明加了唯一索引,为什么还是产生了重复数据?前言前段时间我踩过一个坑:在mysql8的一张innodb引擎的表中,加了唯一索引,但最后发现数据竟然还是重复了。到底怎么回事呢?本文通过一次踩坑经历,聊聊唯一索引,一些有意思的知识点。1.还原问题现场前段时间,为了防止商品组产生重复的数据,我专门加了一张防重表。如果大家对防重表,比较感兴趣,可以看看
1
•••
38
39
40
•••
1000