推荐
专栏
教程
课程
飞鹅
本次共找到809条
机器狗
相关的信息
不是海碗
•
2年前
ChatGPT3.5-Turbo:真正的人工智能
近年来,随着机器学习算法的不断进步以及海量数据的可用性,自然语言处理(NLP)领域取得了巨大的进展。其中,GPT3.5Turbo是一种代表着重大突破的NLP模型。作为生成式语言模型,它可以根据上下文预测给定句子中的下一个单词,进而生成类似人类的文本。
胖大海
•
3年前
Linux 文件权限
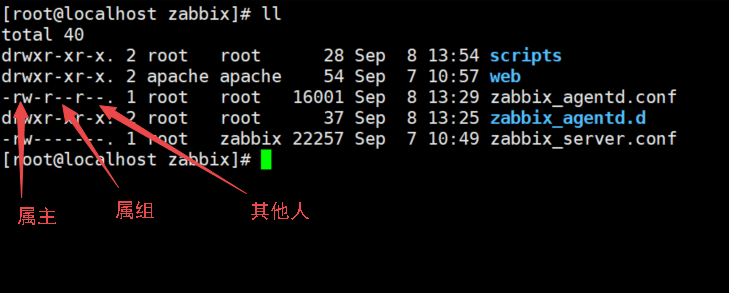
权限管理:指的是操作文件权限超管(root)用户不受普通权限的限制。文件权限分类写内容的权限可写r4写内容的权限可写w2执行的权限可执行x1权限位的概念rw rw rw 属主 属组 其他人设置权限的命令格式chown\ 大家缺乏机器练手的话,可以去3A服务器看看!
Easter79
•
4年前
tensorflow 之循环神经网络
应用场景:应用于语音识别语音翻译机器翻译RNNRNN(RecurrentNeuralNetworks,循环神经网络)不仅会学习当前时刻的信息,也会依赖之前的序列信息。由于其特殊的网络模型结构解决了信息保存的问题。所以RNN对处理时间序列和语言文本序列问题有独特的优势。递归神经网络都具有一连串重复神经网络模
Wesley13
•
4年前
14 类编程题,精华总结!
选自 Medium作者:FahimulHaq机器之心编译参与:Panda在面试程序员岗位时,我们往往需要经历一个编程面试过程,雇主会借此考验面试者的技术实力。然而,这些技术问题有时候却和我们的实际工作并无太大关系,也由此可能给我们的编程面试准备阶段带来很大的压力。曾在Facebook和微软工作过的Educ
Wesley13
•
4年前
ELF文件结构描述
ELF目标文件格式最前部ELF文件头(ELFHeader),它包含了描述了整个文件的基本属性,比如ELF文件版本、目标机器型号、程序入口地址等。其中ELF文件与段有关的重要结构就是段表(SectionHeaderTable)ELF文件格式1.可重定向文件:文件保存着代码和适当的数据,用来和其他的目标文件一起来创
Wesley13
•
4年前
NIS服务器学习
前提环境:1、安装的必须的软件包ypserv,ypbind,yptool关于包的说明:ypserv:服务器端必须的软件包ypbind:客户端需要的包yptool:与yp相关的命令的包PS:NIS服务跟NFS服务有些共同之处,都需要启动portmap服务检查机器是否已安装的包,若没有,就安装相关的包。基本上系
Wesley13
•
4年前
AI新闻报
!(https://oscimg.oschina.net/oscnet/e3d2b223367f4b3cb23e6fa85f03ce89.png"圣诞鹿引导关注")1.【论文】聚焦快速机器学习训练算法,UC伯克利尤洋189页博士论文公布过去十年,深度学习应用领域的数据量迅速增长,使得深度神经网络(DNN)的训练时
Stella981
•
4年前
Kubernetes网络分析之Flannel
Flannel是cereos开源的CNI网络插件,下图flannel官网提供的一个数据包经过封包、传输以及拆包的示意图,从这个图片里面里面可以看出两台机器的docker0分别处于不同的段:10.1.20.1/24和10.1.15.1/24,如果从WebAppFrontend1pod(10.1.15.2)去连接另一台主机上的Backend
Wesley13
•
4年前
MongoDB 的分片技术
在MongoDB中分片技术也就是集群。需要1台配置服务器配置各个节点的配置信息,1台路由服务器来知道每一台节点都在哪个地方并给用户提供各个节点数据的访问功能,还有多台节点服务器,存储节点数据。 当前我有三台机器192.168.0.114,192.168.0.115,192.168.0.116,规划如下: 搭建配置服务器:192.1
广州华锐互动
•
3年前
虚拟数字人开发哪家好?广州华锐互动元宇宙定制助力品牌营销!
近两年,元宇宙概念下的虚拟数字人不断崛起。虚拟数字人是利用计算机数字建模技术模拟人物形象;利用动作捕捉,面部捕捉等技术模拟真实人物表情,眼神与嘴形;并具有语音识别、语义理解,模拟真人发音说话的AI能力的机器人。“十八般武艺”的虚拟数字人吸引了数以亿
1
•••
56
57
58
•••
81