推荐
专栏
教程
课程
飞鹅
本次共找到165条
欧拉
相关的信息
乌秃头
•
10个月前
docker 部署运行MinerU
要在本地使用Docker部署并运行MinerU(仅使用CPU),您可以按照以下步骤进行操作:1.准备工作确保您的计算机上已经安装了Docker环境。如果没有,请访问Docker官方网站下载并安装适合您系统的版本。确保Docker服务已经启动。2.拉取Min
亚瑟
•
4年前
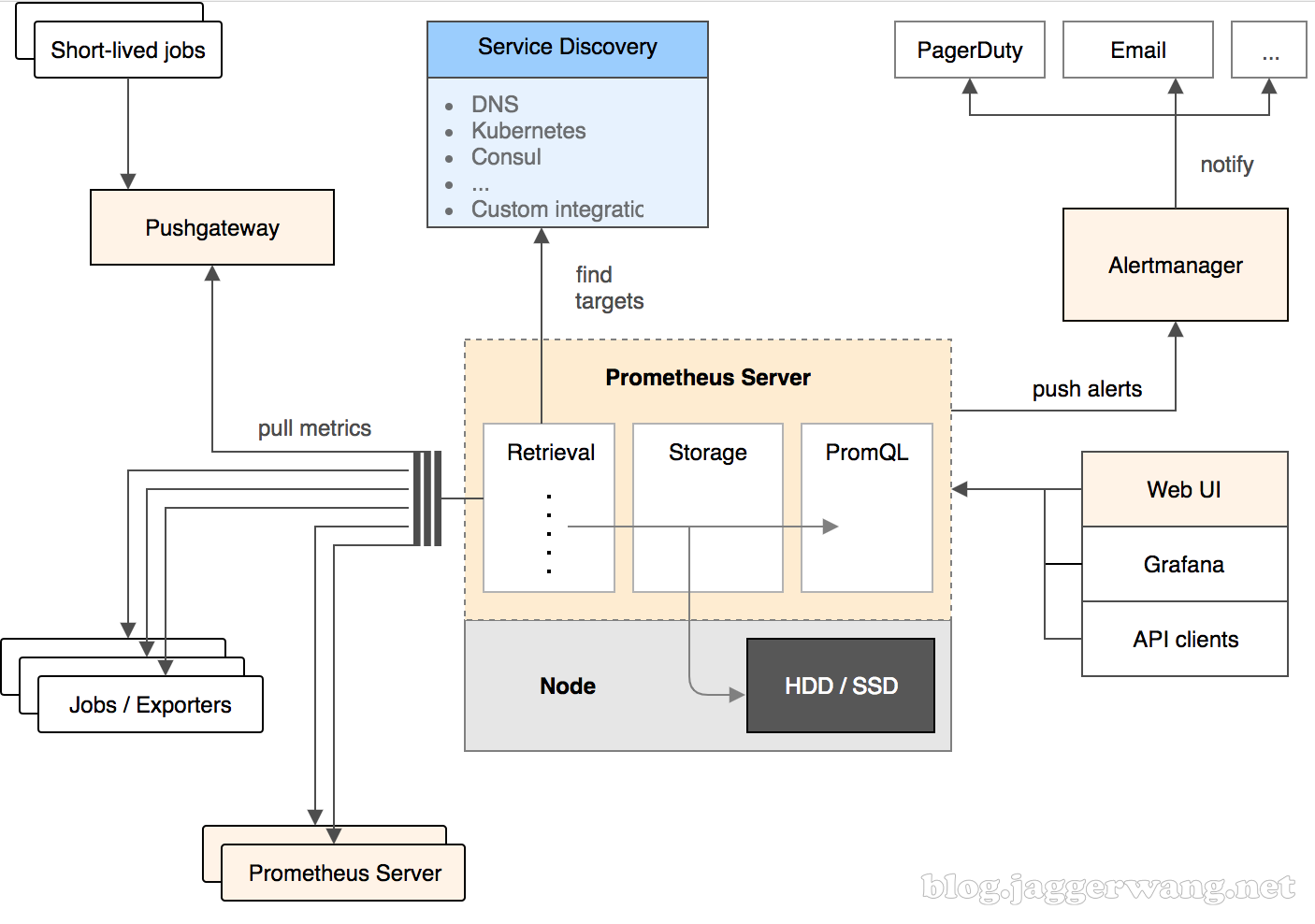
云原生监控系统 Prometheus 入门
Prometheus介绍主要特性之所以Prometheus现在这么受欢迎,主要是因为它具备如下特性:多维度数据模型灵活的查询语言不依赖任何分布式存储常见方式是通过拉取方式采集数据也可通过中间网关支持推送方式采集数据通过服务发现或者静态配置来发现监控目标支持多
Stella981
•
4年前
CSS实现树形结构 + js加载数据
看到一款树形结构,比较喜欢它的样式,就参照它的外观自己做了一个,练习一下CSS。 做出来的效果如下:拉莫小学一年级一班二班二年级三年级一班二班三班树的
Stella981
•
4年前
IDEA解决从git上clone代码没有maven依赖的问题
首先,从git上拉取代码:!(https://oscimg.oschina.net/oscnet/d26f7f4baf65d73148a02d77c1e25a0d603.png)我们将新clone下来的项目打开,可以发现在git上原本是maven项目的工程,没有了maven的结构:!(https://oscimg.oschina.net/
Stella981
•
4年前
JVM的入门知识
前言:巴拉巴拉,今天给大家分享一点java三剑客(jre,jvm,jdk)中的jvm,纯理论教科书篇。非原创,里面摘取了多个博客里面的内容1 JDK、JRE、JVM的关系是什么?我们学习JVM的之前,简单科普一下他们三者有啥关系JVMJAVA虚拟机(JavaVirtualMa
Stella981
•
4年前
Hadoop学习之路(二十三)MapReduce中的shuffle详解
概述1、MapReduce中,mapper阶段处理的数据如何传递给reducer阶段,是MapReduce框架中最关键的一个流程,这个流程就叫Shuffle2、Shuffle:数据混洗——(核心机制:数据分区,排序,局部聚合,缓存,拉取,再合并排序)3、具体来说:就是将MapTask输出的处理结果数据,按照Par
Stella981
•
4年前
Git 单机版
Git是一个分布式的开源版本控制系统,也就是说,每台机器都可以充当控制中心,我从本机拉取代码,再提交代码到本机,不需要依赖网络,各自开发各自的如何创建git仓库:root@localhost~$yuminstallygit安装gitroot@localhost~$mkdirp/data
Stella981
•
4年前
Kafka在哪些场景下会造成重复消费或消息丢失?
kafka消费者在消费的时候对于位移提交的具体时机的把握也很有讲究,有可能会造成重复消费和消息丢失的现象。!(https://oscimg.oschina.net/oscnet/3566bbd82538478396a25dd6e023974e.png"image.png")参考上图,当前一次poll()操作所拉取的消
京东云开发者
•
2年前
CDP 技术系列(三):百万级 QPS 的人群命中服务接口性能优化指南
一、背景介绍CDP系统提供了强大的标签和群体的构建能力,面对海量数据的标签和群体,我们采用了BitmapClickHouse的存储与计算方案。详细内容可以参考之前文章。有了群体之后,它们被广泛的应用到支付,消金,财富,营销等各种核心业务的用户拉新,交易转
产品经理克星
•
5个月前
甲骨文史诗级暴涨背后的AI基建浪潮,近屿智能助你抢占职业先机
引言:一场股价暴涨,揭开AI基建的“新石油时代”10月的美股市场,特朗普对华“关税”言论引发科技股市值蒸发1.65万亿美元的震荡,而甲骨文(Oracle)却逆势上演“史诗级逆袭”——单日股价暴涨近40%,创1992年以来纪录,创始人拉里・埃里森短暂登顶世界
1
•••
9
10
11
•••
17