推荐
专栏
教程
课程
飞鹅
本次共找到623条
网页抓取
相关的信息
Wesley13
•
4年前
java实现 PageRank算法
PageRank算法是Google的核心搜索算法,在所有链接型文档搜索中有极大用处,而且在我们的各种关联系统中都有好的用法,比如专家评分系统,微博搜索/排名,SNS系统等。 PageRank算法的依据或思想: 1,被重要的网页链接的越多(外链) ,此网页就越重要 2,此网页对外的链接越少越重要 这两个依据不能
Wesley13
•
4年前
java通过sina端口提取股票历史数据并存入MySQL
1.提取股票代码代码见:http://www.oschina.net/code/snippet\_2688840\_55337(http://www.oschina.net/code/snippet_2688840_55337) 2抓取sina股票的json页面数据;代码见:http://www.oschina.net/code/snip
Stella981
•
4年前
Nginx+uwsgi+ssl配置https
使用原始django,太过于笨重和杂多nginx是一个轻量级的web服务器,在处理静态资源和高并发有优势uwsgi是一个基于python的高效率的协议,处理后端和动态网页有优势所以这里采用静态网页交给nginx解析,动态网页交给uwsgi解析,并且nginx配置ssl,即可以使用出高安全,高效率的部署。步骤我
Stella981
•
4年前
BeetlSQL 3.0.9 发布,Idea 插件发布
本次发布修复了bug以及发布了可在idea社区和专业版使用的BeetlSQL插件修复代码生成到本地路径错误的Bug修复FetchOne抓取数据错误。Idea插件发布<dependency<groupIdcom.ibeetl</groupId<artifactIdbeetlsql</artifactId<version3.0.9
Stella981
•
4年前
JavaScript DOM编程艺术(第2版)学习笔记1(1~4章)
第一章一些基本概念HTML(超文本标记语言),构建网页的静态结构,由一系列的DOM组成;CSS(层叠样式表),给网页各部分结构添加样式;JavaScript,通过获取DOM给静态结构加上动作,使用户能够与静态网页进行交互;DOM,一种API(应用程序接口),通过这个接口动态的访问和修改结构或样式。浏
Wesley13
•
4年前
GuozhongCrawler系列教程 (5) TransactionRequest详解
为了实现和维护并发抓取的属性信息提供线程安全的事务请求。TransactionRequest是一个抽象类自己不能设置Processor,却需要实现TransactionCallBack接口。TransactionRequest是个复合的BasicRequest。他可以将多个PageRequest、BinaryRequest甚至Transacti
Stella981
•
4年前
Laravel Symfony_Crawler GuzzleHttp 爬虫 抓取行政区域
2018/05/29修改抓取编码gb2312改gb18030项目需要行政区域三级联动,刚好写个爬虫练练手。Laravel框架,安装的两个库composerrequireguzzlehttp/guzzlecomposerrequiresymfony/domcrawler创建表DROPT
小白学大数据
•
2年前
python爬虫中“动态网页”如何爬取
经常会在一些爬虫群里面看到这样的提问,为什么用Python爬虫请求某个网页时,有时打印的数据不全或者什么数据都没有或者只有html骨架代码。这是因为涉及到了”动态网页数据“这个词了,简单而言,就是后台的数据不是请求网页链接时就已经将数据写入到相应的标签上了
魂祈梦
•
1年前
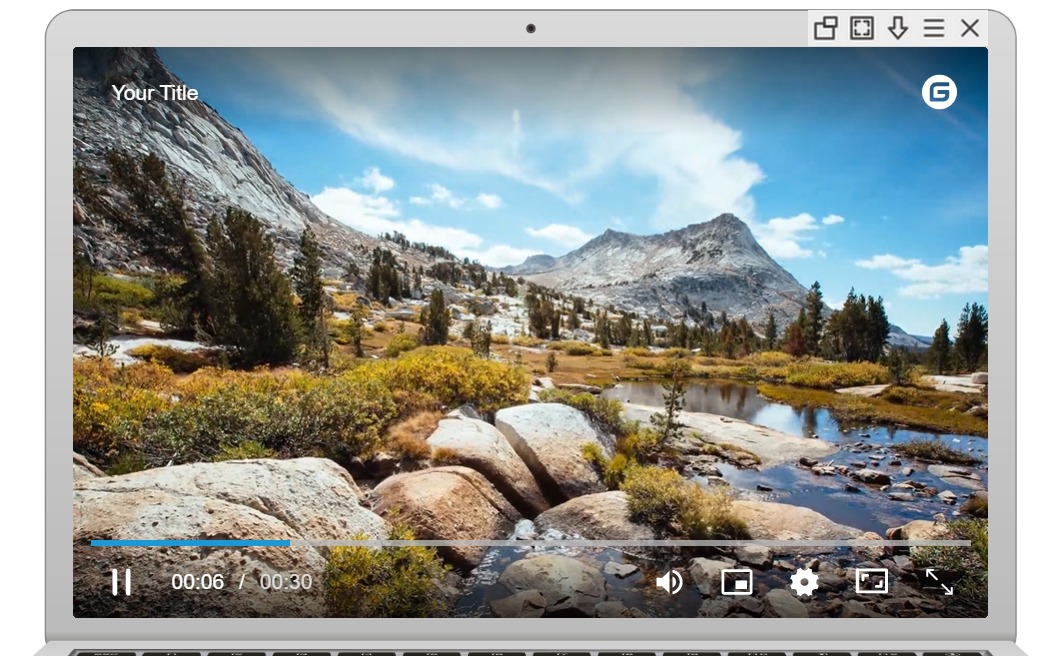
从DPlayer说起,有哪些开源的H5播放器
主要介绍(列出)一些开源的网页播放器。
1
•••
9
10
11
•••
63