推荐
专栏
教程
课程
飞鹅
本次共找到632条
网页抓取
相关的信息
无聊的调包专家
•
4年前
微标题信公众号文章,阅读数,点赞数历史文章抓取
微标题信公众号文章,阅读数,点赞数历史文章抓取需求最近在做舆情与微信文章相关的数据抓取,发现微信公众号有些难点很难克服。市面上流行的数据抓取思路要么被腾讯封杀,要么操作难度大。解决方案搜狗微信无法采集历史,而且搜索也不按时间排序。获取的数据的价值不高,仅仅可以通过他获取公众号的biz。微信公众平台微信公
Irene181
•
4年前
详解4种类型的爬虫技术
导读:网络爬虫是一种很好的自动采集数据的通用手段。本文将会对爬虫的类型进行介绍。作者:赵国生王健来源:大数据DT(ID:hzdashuju)聚焦网络爬虫是“面向特定主题需求”的一种爬虫程序,而通用网络爬虫则是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内
Wesley13
•
4年前
java操作html格式数据
近期在做数据抓取功能,抓取到的数据为html格式,需在后台进行转换后取值,为了避免使用字符串查找方式获取而使用Jsonp完美实现。1\.引入Jsonp:1<dependency2<groupIdorg.jsoup</groupId3<artifactIdjsoup</artifactId
Stella981
•
4年前
Charles 使用教程
我们在开发网站项目的时候,我们可以通过浏览器的debug模式来看request以及response的数据,那么如果我们开发移动端项目没有网页呢?如何抓取数据呢?前几天有个做服务端的师弟跟我说他不用抓包工具,遇到问题直接debug代码,那我问他,如果线上服务的话,你怎么调?在实际项目中,没有遇到跟客户端相互扯皮的事情吗?我觉得很正常啊,客户端说他没问题,服
Stella981
•
4年前
C#使用Selenium实现QQ空间数据抓取 说说抓取
上一篇讲的是如何模拟真人操作登录QQ空间,本篇主要讲述一下如何抓取QQ说说数据继续登录空间后的操作登陆后我们发现QQ空间的菜单其实是固定的,只需要找到对应元素就可以,继续XPath!(https://images2018.cnblogs.com/blog/318685/201808/3186852018082909444441195851
Stella981
•
4年前
Python爬虫入门教程 32
1\.B站博人传评论数据爬取简介今天想了半天不知道抓啥,去B站看跳舞的小姐姐,忽然看到了评论,那就抓取一下B站的评论数据,视频动画那么多,也不知道抓取哪个,选了一个博人传跟火影相关的,抓取看看。网址:https://www.bilibili.com/bangumi/media/md5978/?fromsearc
Wesley13
•
4年前
KK课表抓取教务系统
字符串数据解析太难看login_widget::login_widget(QWidget parent) ://QWidget(parent),ui(new Ui::login_widget){uisetupUi(this);p (MainWindow)paren
Python进阶者
•
3年前
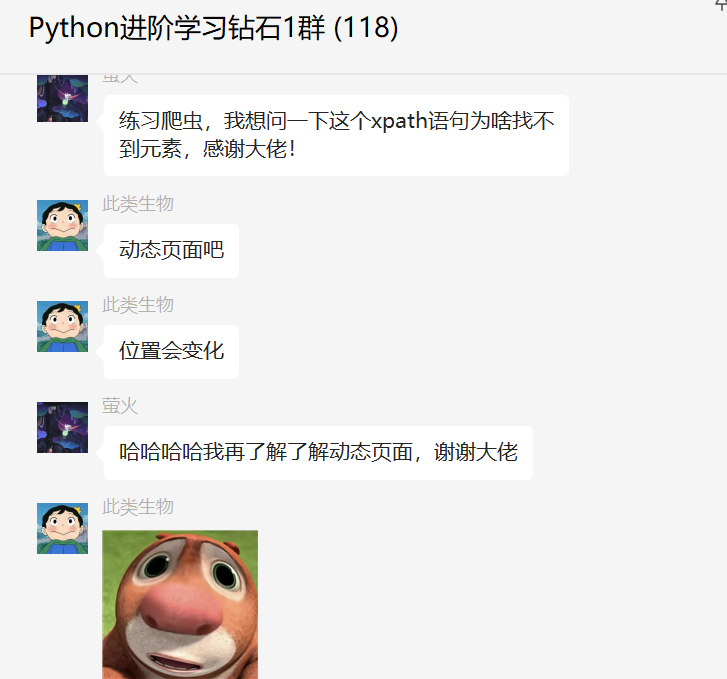
练习爬虫,我想问一下这个xpath语句为啥找不到元素,感谢大佬!
大家好,我是皮皮。一、前言前几天在Python钻石交流群【萤火】问了一个Python网络爬虫的问题,下图是截图:下图是报错截图:二、实现过程这里【error】给了一个代码,如下所示,满足粉丝的需求:用selenium没找到的话,大概率是网页还没渲染出来,代码就运行到了抓取规则,所以抓不到。其实他的匹配规则是可以拿到数据的,只不过用jupyter运行sel
狡猾的骗骗花
•
3年前
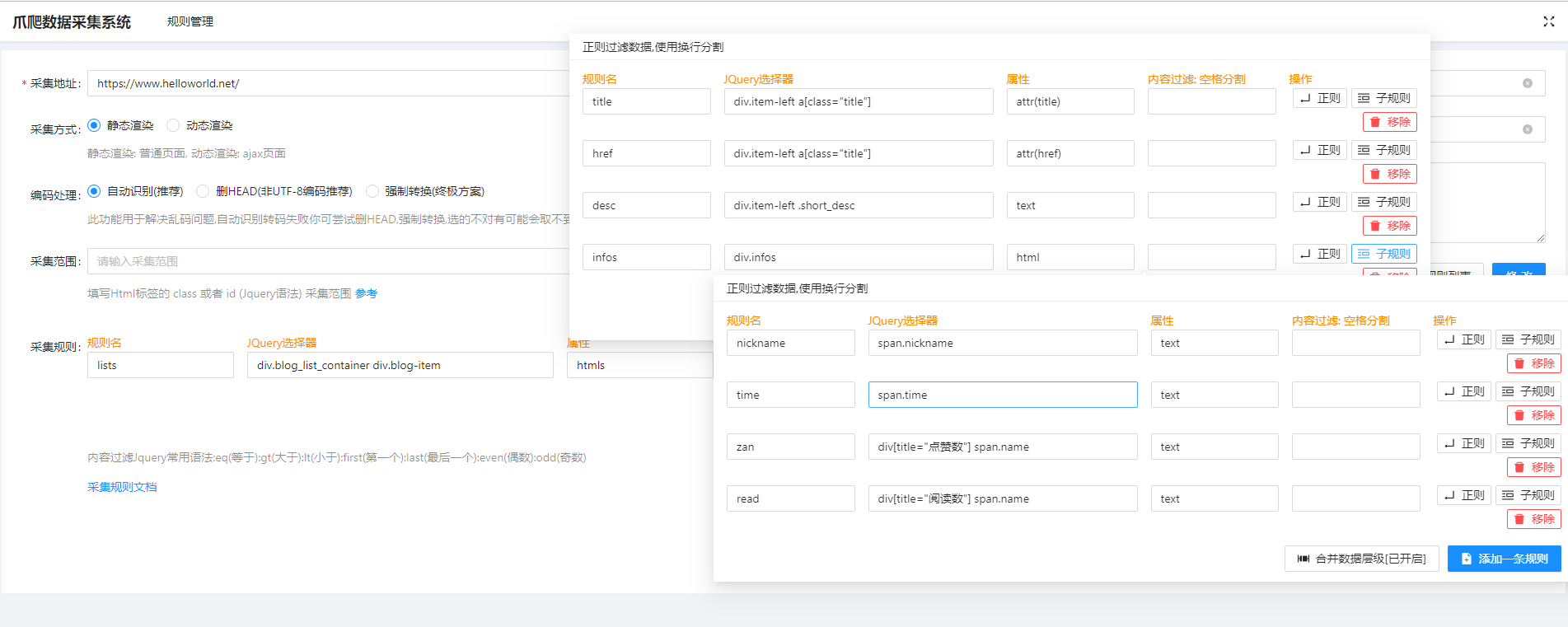
采集系统(php) 爪爬采集
爪爬采集(编写的小玩意框架采用tp6规则使用的jquery语法按道理来说一般的网页都能抓下面举例子抓取helloworld上的文章的例子.首先根据F12的元素信息实现定义规则最后按一下Debug按钮得到结果支持分页参数page.支持正则过滤/筛选/替换支持http代理代码调用示例
小白学大数据
•
1年前
网页爬虫开发:使用Scala和PhantomJS访问知乎
引言随着大数据时代的到来,网页爬虫作为一种高效的数据收集工具,被广泛应用于互联网数据抓取和信息抽取。而知乎是一个知识分享平台,拥有大量的用户生成内容。通过爬虫获取知乎数据,企业和研究人员可以进行深入的数据分析和市场研究,了解用户的需求、兴趣和行为模式,从而
1
2
3
4
•••
64