推荐
专栏
教程
课程
飞鹅
本次共找到624条
网页抓取
相关的信息
胡哥有话说
•
4年前
Node.js爬虫实战 - 爬你喜欢的
前言今天没有什么前言,就是想分享些关于爬虫的技术,任性。来吧,各位客官,里边请...开篇第一问:爬虫是什么嘞?首先咱们说哈,爬虫不是“虫子”,姑凉们不要害怕。爬虫一种通过一定方式按照一定规则抓取数据的操作或方法。开篇第二问:爬虫能做什么嘞?来来来,谈谈需求产品MM:1.爱豆的新电影上架了,整体电影评价如何呢?2.暗
Python进阶者
•
3年前
手把手教你用Python网络爬虫进行多线程采集高清游戏壁纸
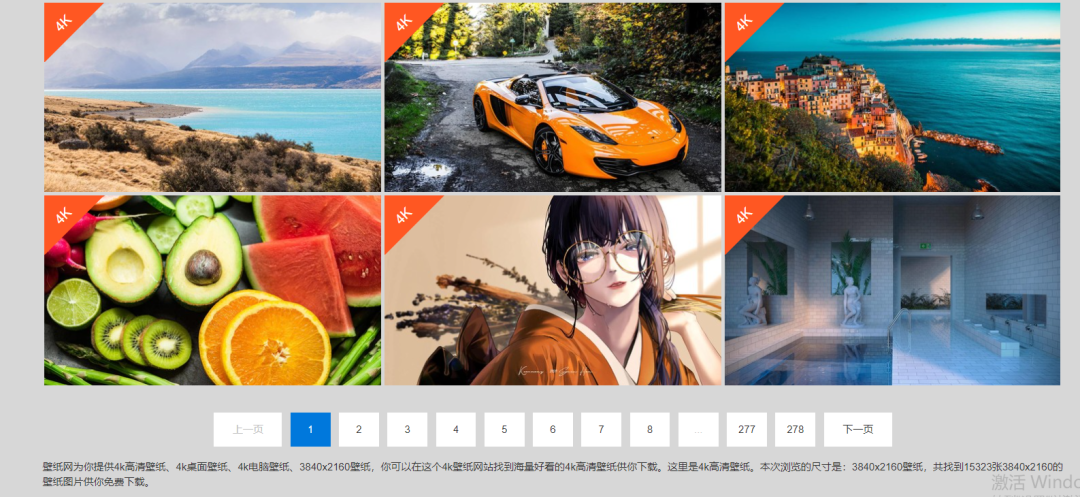
一、背景介绍大家好,我是皮皮。对于不同的数据我们使用的抓取方式不一样,图片,视频,音频,文本,都有所不同,由于网站图片素材过多,所以今天我们使用多线程的方式采集某站4K高清壁纸。二、页面分析目标网站:http://www.bizhi88.com/3840x2160/如图所示,有278个页面,这里我们爬取前100页的壁纸图片,保存到本地;解析页面如图所示所哟
Wesley13
•
4年前
java基础60 JavaScript字符串转换成数字(网页知识)
1、字符串转换成数字1<!doctypehtml2<html3<head4<metacharset"utf8"5<title字符串转换成数字练习</title6</head7<scripttype"text/javascrip
Stella981
•
4年前
Serverless 实战 —— 快速开发一个分布式 Puppeteer 网页截图服务
通俗描述就是:Puppeteer可以将Chrome或者Chromium以无界面的方式运行(当然也可以运行在有界面的服务器上),然后可以通过代码控制浏览器的行为,即使是非界面的模式运行,Chrome或Chromium也可以在内存中正确渲染网页的内容。那么Puppeteer能做什么呢?其实有很多地方都可以受用Puppeteer,比如:
Stella981
•
4年前
Android 7.0+使用VirtualXposed+Charles进行抓包
前言最近在对一个app进行测试的时候,尝试抓取数据包,发现以前的使用方法失效了,原因是随着安卓版本的提高,对证书的限制越发严格,而我身边的老机子放在学,不在身边,没得办法,只好研究一下怎么绕过这种限制。经过一方查找,终于发现了一个相对比较简单的办法,这里就开一篇文章,记录一下。过程首先下载所需要的工具:●Charles—
Stella981
•
4年前
43个实例xHTML+CSS(DIV+CSS)网页及导航布局教程
在中国,很多前端开发初学者都会把xHTMLCSS页面制作说成DIVCSS,甚至很多人都还不知道xHTMLCSS是什么意思,只知道盲目的追求DIVCSS,但在国外,是没有DIVCSS这个概念的,很明显如果单从字面上去理解,DIVCSS的网页就要全都是div,很明显是无法达到语义化标准的。请把”DIVCSS”这个词从脑子中删除,用”xHTMLCS
Wesley13
•
4年前
IP地址定位区间的问题分析
以前写过一篇Oracle中关于IP地址定位的问题分析,最后引申出了一系列的问题。当时问题紧急严峻,抓取了10053事件定位源头,想出了一个解决妙法,还自鸣得意了下,结果忙活完之后看看行业里的解决方案都大体如此,我的心凉了半截。 我总是希望找到一些与众不同的点来解读这一类问题,结果在偶然的一天从MySQL这里找到了一些思路。 我先来分析
Stella981
•
4年前
Apache 打开网页的时候等待时间过长的解决方案
Wesley13
•
4年前
DEDE让广告延时加载显示,大大提高网页访问的速度
延迟默认的第一个广告(aid1)为例。1、在你要放置广告的地方加入以下代码,中间的文字可以修改成自己的词语、代码或者图像等。<spanid"topbanner"精彩内容读取中……</span2、在</body前面加入以下代码<spanid"ad\_topbanner"style"display:none"<scri
爬虫程序大魔王
•
3年前
什么是网络爬虫?
什么是网络爬虫网络爬虫是一种在Internet上运行自动化任务的软件应用程序。与人类互联网活动相比,网络爬虫运行的任务通常很简单,并且执行速度要快得多。有些机器人是合法的——例如,Googlebot是Google用来抓取互联网并将其编入索引以进行搜索的应用程序。其他机器人是恶意的——例如,用于自动扫描网站以查找软件漏洞并执行简单攻击模式的机器人。
1
•••
31
32
33
•••
63