推荐
专栏
教程
课程
飞鹅
本次共找到2736条
聚类
相关的信息
不是海碗
•
2年前
IP 归属地查询 API 教你从0到1顺着网线找到键盘侠
IP归属地是利用大数据挖掘和大规模网络探测技术,对IP地址的基础信息和网络拓扑数据进行采集、处理,结合IP地址所在的应用场景与网络属性等因素,利用动态密度聚类算法和基于多层神经网络的IP地址定位算法,完成IP地址地理位置定位。
待兔
•
4年前
面向对象设计原则之 - 高内聚
通常在面向对象设计中,我们经常听到,高内聚,低耦合,那么到底什么是内聚呢?内聚究竟是什么?参考百度百科的解释,内聚的含义如下:内聚(Cohesion),科学名词,是一个模块内部各成分之间相关联程度的度量。我自己的理解是:内聚指一个模块内部元素之间的紧密程度看起来很好理解,但只要深入思考一下,其实没有那么简单。首先,“模块”如何理解?一定会有人说,模块
待兔
•
4年前
面向对象设计原则之 - 低耦合
耦合到底是什么?耦合(或者称为依赖)是程序模块之间的依赖程度。从定义上看,耦合和内聚是相反的:内聚关注模块内部的元素的结合程度耦合关注模块之间的依赖程度理解耦合的关键有两点:什么是模块?模块和内聚里面提到的模块是一样的,耦合中的模块其实也是可大可小的。常见的模块有函数,类,包,子模块,子系统等什么是依赖?依赖这个词很好理解,通俗地讲,就是
专注IP定位
•
4年前
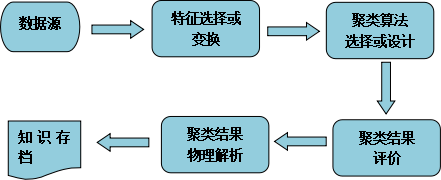
聚类算法有哪些?又是如何分类?
想要了解聚类算法并对其进行区别与比较的话,最好能把聚类的具体算法放到整个聚类分析的语境中理解。聚类分析是一个较为严密的数据分析过程。从聚类对象数据源开始到得到聚类结果的知识存档,共有四个主要研究内容聚类分析过程:1984年,Aldenderfer等人提出了聚类分析的四大功能:一是数据分类的进一步扩展;二是对实体归类的概念性探索;三是通过数据探索而生成假
Wesley13
•
4年前
MySQL中Innodb的聚簇索引和非聚簇索引
聚簇索引数据库表的索引从数据存储方式上可以分为聚簇索引和非聚簇索引(又叫二级索引)两种。Innodb的聚簇索引在同一个BTree中保存了索引列和具体的数据,在聚簇索引中,实际的数据保存在叶子页中,中间的节点页保存指向下一层页面的指针。“聚簇”的意思是数据行被按照一定顺序一个个紧密地排列在一起存储。一个表只能有一个聚簇索引,因为在一个表中数据的
Stella981
•
4年前
DGA聚类 使用DBScan
featuressc.parallelize(data\_group\idx\).map(lambdax:(x.host\_ip'^'x.domain,1)).reduceByKey(operator.add).map(get\_domain\_features)defget\_domain\_features(x):
Wesley13
•
4年前
Java 类之间的关系
总述类和类之间的关系,耦合度从高到低:is。继承、实现has。组合、聚合、关联use。依赖。要求是:高内聚、低耦合。继承Person和Man之间是继承关系。!(https://oscimg.oschina.net/oscnet/7b9f06e3a37b7bc9c5c2fe14
Wesley13
•
4年前
Java程序员实战机器学习——从聚类算法开始
本文适合有编程经验的程序员,是一篇机器学习的”Helloworld!”,没什么理论知识,在意理论准确性的人请绕道。前言人工智能无疑是近年来最火热的技术话题之一,以机器学习为代表的人工智能技术,已经慢慢渗透到我们生活的方方面面,任何事物只要沾上机器学习的边,似乎就变得高大上了。作为处于技术大潮中程序员,我们离机器学习是那么地近,却又
linbojue
•
1年前
史上最全的后端技术
系统开发1.高内聚/低耦合高内聚指一个软件模块是由相关性很强的代码组成,只负责一项任务,也就是常说的单一责任原则。模块的内聚反映模块内部联系的紧密程度。模块之间联系越紧密,其耦合性就越强,模块的独立性则越差。模块间耦合高低取决于模块间接口的复杂性、调用的方
1
2
3
•••
274