推荐
专栏
教程
课程
飞鹅
本次共找到10000条
python机器学习库
相关的信息
Easter79
•
3年前
sqoop从hive导入数据到mysql时出现主键冲突
今天在将一个hive数仓表导出到mysql数据库时出现进度条一直维持在95%一段时间后提示失败的情况,搞了好久才解决。使用的环境是HUE中的Oozie的workflow任何调用sqoop命令,该死的oozie的日志和异常提示功能太辣鸡了,最后发现是重复数据导致数据进入mysql表时出现主键冲突进而导致数据同步失败。(1)众所周知hive表是没有主键与索引
Easter79
•
3年前
springboot2结合mybatis拦截器实现主键自动生成
前言前阵子和朋友聊天,他说他们项目有个需求,要实现主键自动生成,不想每次新增的时候,都手动设置主键。于是我就问他,那你们数据库表设置主键自动递增不就得了。他的回答是他们项目目前的id都是采用雪花算法来生成,因此为了项目稳定性,不会切换id的生成方式。朋友问我有没有什么实现思路,他们公司的orm框架是mybatis,我就建议他说,不然让你老大把m
cpp加油站
•
4年前
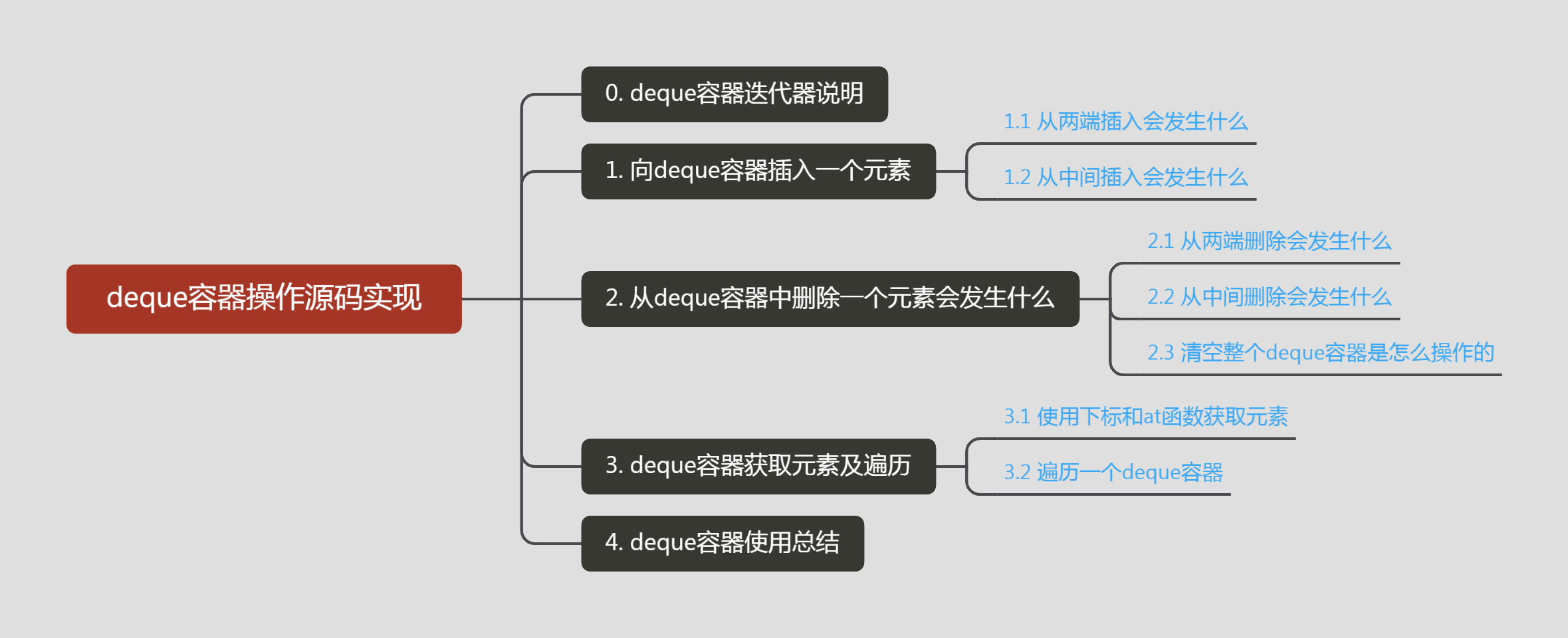
【deque容器系列二】基于STL源码分析deque容器插入和删除时内存都是怎么变动的
上篇文章我们介绍了deque容器整体结构和构造实现,链接如下:本篇文章接上篇,继续基于gcc中stl的源码剖析deque容器插入、删除、取值的实现原理,以提问者的角度去深入分析这些操作过程中发生了什么,并对deque容器适合使用的场景和使用时的注意事项进行说明。说明一下,我用的是gcc7.1.0编译器,标准库源代码也是这个版本的。按照惯例,还是先看一下本文
helloworld_78018081
•
4年前
【设计思想解读开源框架】Activity的6大难点,你会几个
背景面是是上海的Androidleader岗位,周日一轮面试,自我感觉答的都还不错。结果收到邮件面试结束了,说什么"你优秀的学识和能力给我们留下了深刻的印象!经过对你综合情况的仔细评估,并经过与岗位需求进行谨慎匹配和权衡之后,非常遗憾,我们这次没有和你达成合作。但你的信息已经被录入到公司人才库"。意思就是挂了呗。后来打电话问hr,没跟我说原因。然后面试过
Easter79
•
3年前
SVN的Trunk Branchs Tags
我们在一些著名开源项目的版本库中,通常可以看到trunk,branches,tags等三个目录。由于SVN固有的特点,目录在SVN中并没有特别的意义,但是这三个目录却在大多数开源项目中存在,这是因为这三个目录反映了软件开发的通常模式。trunk是主分支,是日常开发进行的地方。branches是分支。一些阶段性的release版本,这些版本是可以继
Stella981
•
3年前
Skynet 设计综述
1.多线程模式,可以使得状态共享、数据交换更加高效。而多线程模型的诸多弊端,比如复杂的线程锁、线程调度问题等,都可以通过减小底层的规模,精简设计,最终把危害限制在很小的范围内。2.做为核心功能,Skynet仅解决一个问题:把一个符合规范的C模块,从动态库(so文件)中启动起来,绑定一个永不重复(即使模块退出)的数字id做为其handl
Stella981
•
3年前
Spring Boot 1 和 Spring Boo 2的差别
有差别,但差别不大。基本上基于SpringBoot的代码不需要改动,但有些配置属性和配置类,可能要改动,改动原因是配置已经不存在或者改名类已经不存在改名听着挺吓人,但我实际切换过程中改动的地方很少。一般正常的MVC,数据库访问这些都不需要改动,下面按照我写的《SpringBoot2精髓:从构建小系统到架构分布式大系统》(https://ww
Wesley13
•
3年前
INNODB锁(2)
在上一篇文章写了锁的基本概述以及行锁的三种形式,这一篇的主要内容如下:一致性非锁定读自增长与锁外键和锁一致性性非锁定读一致性非锁定读是InnoDB通过多版本并发控制(MVCC,multiversionconcurrencycontrol)的方式来读取当前执行时间数据库中的最近一次快照,如果读取的行正在执行
Wesley13
•
3年前
HGDB分区表的使用与管理
目录文档用途详细信息文档用途了解HGDB分区表的简单使用详细信息1.简介数据库表分区把一个大的物理表分成若干个小的物理表,并使得这些小物理表在逻辑上可以被当成一张表来使用。一般来讲我们把上述说明中的大的物理表称为父表/主表,小的物理表称为子表/分区表。主表/父表/MasterTable 该表是创建子表的模板。它是
Stella981
•
3年前
Apache Kafka:大数据的实时处理时代
作者|王国璋编辑|小智在过去几年,对于ApacheKafka的使用范畴已经远不仅是分布式的消息系统:我们可以将每一次用户点击,每一个数据库更改,每一条日志的生成,都转化成实时的结构化数据流,更早的存储和分析它们,并从中获得价值。同时,越来越多的企业应用也开始从批处理数据平台向实时的流数据数据平台转移。本演讲将介绍最近ApacheKafka
1
•••
988
989
990
•••
1000