推荐
专栏
教程
课程
飞鹅
本次共找到6697条
python机器学习
相关的信息
十月飞翔
•
3年前
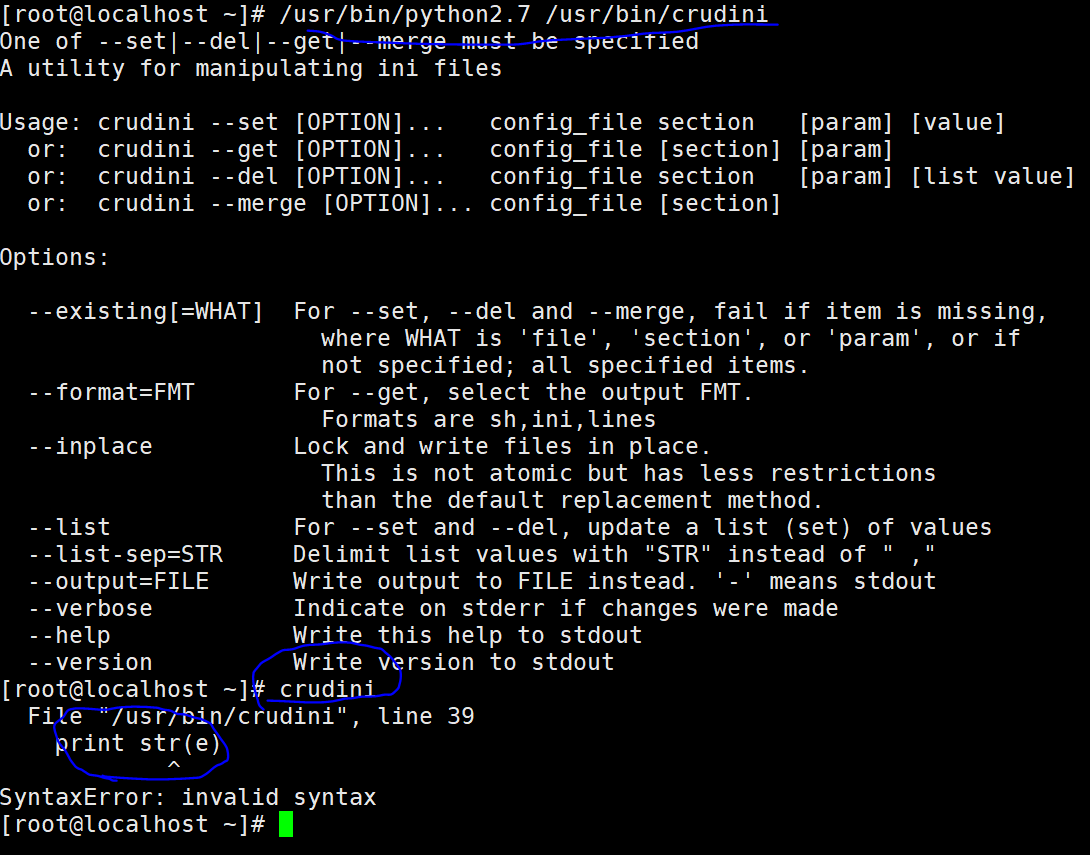
解决jenkins服务器安装的crudini调用失败问题
原因:/usr/bin/crudini文件print用的python2.7的语法,不支持默认的python3.7解决:调用crudini时候指定python2.7启动
个推技术实践
•
4年前
个推分享Spark性能调优指南:性能提升60%↑ 成本降低50%↓
前言Spark是目前主流的大数据计算引擎,功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计算操作,应用范围与前景非常广泛。作为一种内存计算框架,Spark运算速度快,并能够满足UDF、大小表Join、多路输出等多样化的数据计算和处理需求。作为国内专业的数据智能服务商,个推从早期的1.3版本便引入Spark,
Stella981
•
4年前
Mac查看Python安装路径和版本
\TOC\查看当前所有Python版本路径appledeMBP:~apple$whichpython2.7/usr/local/bin/python2.7appledeMBP:~apple$whichpython3.5/Library/Frameworks/Python.framework
可莉
•
4年前
2019年,Hadoop到底是怎么了?
Hadoop太老了,很多人担心它会不会到了明天就已经过时了。目前云驱动数据处理和分析呈上升趋势,我们在本文中来分析下,ApacheHadoop在2019年是否还是一个可选方案。从我第一次使用ApacheHadoop生态系统开始,围绕着“大数据”和“机器学习”两个术语,很多事情已经变得很不一样。在本文中,我们来分析下从那之后发生了什
Stella981
•
4年前
MAC中怎么安装python
转自:https://blog.csdn.net/hou\_manager/article/details/79555809一、Python介绍Python介绍Python3在2008年12月3日正式发布,但是有很多library还是使用Python2.7,所以需要在Mac里面同时装这两个版本,并且和系统所使用的Python区分开来呢?今天要
Stella981
•
4年前
Spider
1\.前期准备1.1开发工具Python3.6PycharmPro2017.3.2Text文本1.2Python库requestsreurllib如果没有这些Python库,使用以下方法
Stella981
•
4年前
2019年,Hadoop到底是怎么了?
Hadoop太老了,很多人担心它会不会到了明天就已经过时了。目前云驱动数据处理和分析呈上升趋势,我们在本文中来分析下,ApacheHadoop在2019年是否还是一个可选方案。从我第一次使用ApacheHadoop生态系统开始,围绕着“大数据”和“机器学习”两个术语,很多事情已经变得很不一样。在本文中,我们来分析下从那之后发生了什
马尚
•
1年前
使用Python进行简单的图像分类
图像分类是深度学习中的一个常见任务,它可以将图像分到预定义的类别中。本文将介绍如何使用Python和PyTorch库进行简单的图像分类任务。1.准备数据集首先,我们需要准备一个图像数据集,其中包含不同类别的图像。你可以使用自己的数据集,也可以使用公开的数据
天翼云开发者社区
•
1年前
开源数据库生态遇新变数,天翼云TeleDB提供企业数据管理更优解!
天翼云TeleDB分析型实例是一款性能卓越、完全托管的PB级国产化云分析型数据库产品,可提供轻松的海量数据分析体验。基于元数据、计算和存储分离的架构,TeleDB分析型实例集成了MPP数据库的高性能和分析功能、大数据平台的扩展性和灵活性以及云计算的弹性和敏捷性,支持SQL及标准的JDBC和ODBC接口,允许使用自定义函数及内建机器学习功能。
陈哥聊测试
•
6个月前
软件工程3.0时代,为什么人工测试仍必不可少?
这不是一场“机器取代人类”的革命,而是人机协同的新篇章。
1
•••
56
57
58
•••
670