推荐
专栏
教程
课程
飞鹅
本次共找到2932条
python爬虫
相关的信息
Python进阶者
•
3年前
手把手教你用Python网络爬虫进行多线程采集高清游戏壁纸
一、背景介绍大家好,我是皮皮。对于不同的数据我们使用的抓取方式不一样,图片,视频,音频,文本,都有所不同,由于网站图片素材过多,所以今天我们使用多线程的方式采集某站4K高清壁纸。二、页面分析目标网站:http://www.bizhi88.com/3840x2160/如图所示,有278个页面,这里我们爬取前100页的壁纸图片,保存到本地;解析页面如图所示所哟
Karen110
•
4年前
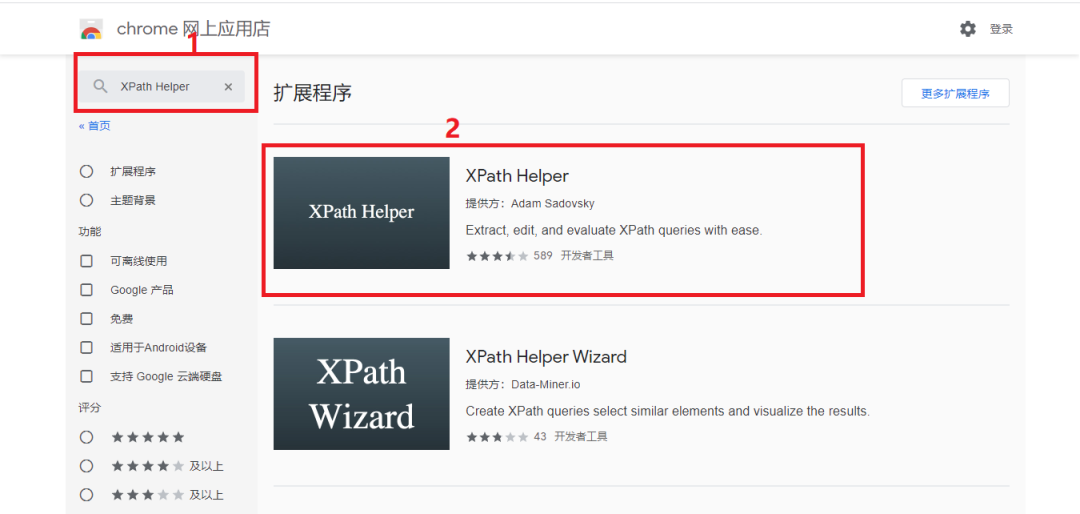
手把手教你使用XPath爬取免费代理IP
大家好,我是霖hero。前言可能有人说,初学者Python爬虫爬数据太难啦,构造正则表达式的时候,太烦琐了,眼睛都看花了,而且前一秒还可以愉快地爬取,下一秒IP就被封了,这还爬个屁啊,不爬了。哎,不要着急,这篇文章我们教你如何使用XPath来爬取快代理中的免费代理IP,告别眼花,告别IP被封的烦恼。XPath首先我们来简单了解一下XPath,想要了解更多
Python进阶者
•
4年前
手把手教你使用Python网络爬虫获取B站视频选集内容(附源码)
大家好,我是Python进阶者。前言前几天雪球兄在Python交流群里分享了一个获取B站视频选集的Python代码,小编觉得非常奈斯,这里整理成一篇小文章,分享给大家学习。关于雪球兄,大家应该都熟悉了,之前他写过Python实战文章,好评如潮,没来得及看的小伙伴,可以戳这里了:之前也有给大家分享B站的一些文章,感兴趣的话可以看看这个文章,Python网络爬
Stella981
•
4年前
Python爬虫实践 —— 4.好听音乐网轻音乐资源下载
第三章的requests库阶段性demo,爬取好听音乐网的榜上歌曲。此网站没有js混淆,音乐资源链接有规律,适合爬虫新手上手。首先观察首页和音乐榜的url链接关系,我们先手动模拟下载,chromef12获取response,可探查到url规律如下:1.!(https://oscimg.oschina.net/oscnet/485087a
小白学大数据
•
1年前
Rust中的数据抓取:代理和scraper的协同工作
一、数据抓取的基本概念数据抓取,又称网络爬虫或网页爬虫,是一种自动从互联网上提取信息的程序。这些信息可以是文本、图片、音频、视频等,用于数据分析、市场研究或内容聚合。为什么选择Rust进行数据抓取?●性能:Rust的编译速度和运行效率极高。●内存安全:Ru
小白学大数据
•
1年前
如何使用pholcus库进行多线程网页标题抓取以提高效率?
在当今信息爆炸的时代,数据抓取已成为获取信息的重要手段。Go语言因其高效的并发处理能力而成为编写爬虫的首选语言之一。pholcus库,作为一个强大的Go语言爬虫框架,提供了多线程抓取的能力,可以显著提高数据抓取的效率。本文将介绍如何使用pholcus库进行
小白学大数据
•
1年前
使用Panther进行爬虫时,如何优雅地处理登录和Cookies?
前言在互联网数据采集领域,网络爬虫扮演着至关重要的角色。它们能够自动化地从网站获取数据,为数据分析、内容聚合、市场研究等提供原材料。然而,许多网站通过登录和Cookies机制来保护其数据,这为爬虫开发者提出了新的挑战。SymfonyPanther作为一个现
小白学大数据
•
3年前
想要知道中国长征系列火箭发射记录很简单
今天,吉林一号高分03D09星等十六颗卫星发射成功,这又是CZ系列的又一次成功,该批卫星主要用于商业遥感、大气成像等领域。点赞中国航天。关于CZ系列火箭发射记录,没有深入去研究的朋友应该不是很清楚,所以今天我们就给大家分享下,通过python爬虫技术爬取中国长征系列火箭发射记录。CZ系列运载火箭作为我国的金名片,以优质、高效、低成本等优势闻名海外,那么今天我
小白学大数据
•
2年前
如何在Puppeteer中设置User-Agent来绕过京东的反爬虫机制?
概述京东作为中国最大的电商平台,为了保护其网站数据的安全性,采取了一系列的反爬虫机制。然而,作为开发者,我们可能需要使用爬虫工具来获取京东的数据。正文Puppeteer是一个由Google开发的Node.js库,它提供了高级的API,用于控制无头浏览器(H
小白学大数据
•
2年前
python HTML文件标题解析问题的挑战
引言在网络爬虫中,HTML文件标题解析扮演着至关重要的角色。正确地解析HTML文件标题可以帮助爬虫准确地获取所需信息,但是在实际操作中,我们常常会面临一些挑战和问题。本文将探讨在Scrapy中解析HTML文件标题时可能遇到的问题,并提供解决方案。问题背景在
1
•••
26
27
28
•••
294