
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源


点击右侧关注,大数据开发领域最强公众号!


大数据真好玩
点击右侧关注,大数据真好玩!

HiveSQL经典优化案例一:
1.1 将要执行的查询(执行了 1个多小时才出结果):
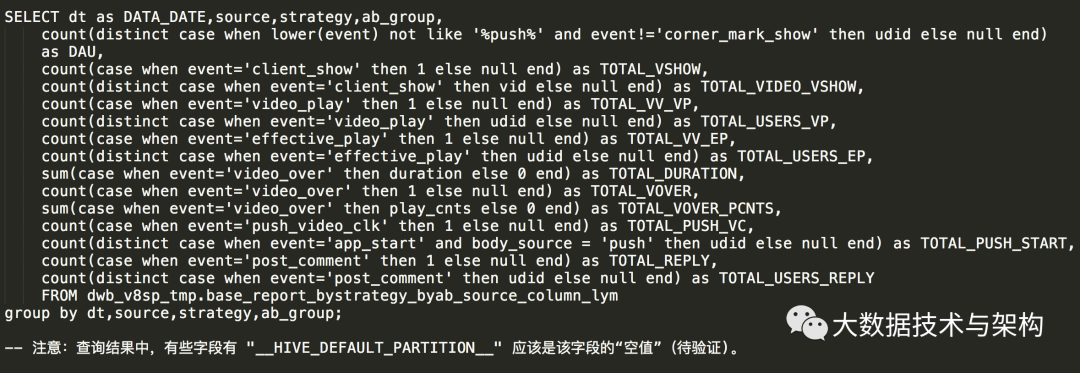
SELECT dt as DATA_DATE,STRATEGY,AB_GROUP,SOURCE,
1.2 查询语句涉及到的表有 7.7亿+ 数据。(查询如下)
jdbc:hive2://ks-hdp-master-01.dns.rightpad (default)> select count(*) from dwb_v8sp_tmp.base_report_bystrategy_byab_source_column_zkl;

1.3 优化思路:既然将要执行的查询是按照 dt, strategy, ab_group, source 这4个字段分组, 那么在建表的时候,就按这四个字段中的N个(1 或 2 或 3 或4)个字段组合分区,直接让 count(distinct xx) 之类的查询定位到“更少的数据子集”,其执行效率就应该更高了(不需要每个子任务均从 7.7亿+ 的数据中(去重)统计)。
1.4 先看每个字段将会有多少分区(因为 Hive 表分区也不宜过多,一般一个查询语句涉及到的 hive分区 应该控制在2K内)
jdbc:hive2://ks-hdp-master-01.dns.rightpad (default)>

1.5 根据原表,新建分区表,并将原表数据插入新表:
show create table dwb_v8sp_tmp.base_report_bystrategy_byab_source_column_zkl;
jdbc:hive2://ks-hdp-master-01.dns.rightpad (default)> show create table dwb_v8sp_tmp.base_report_bystrategy_byab_source_column_zkl;
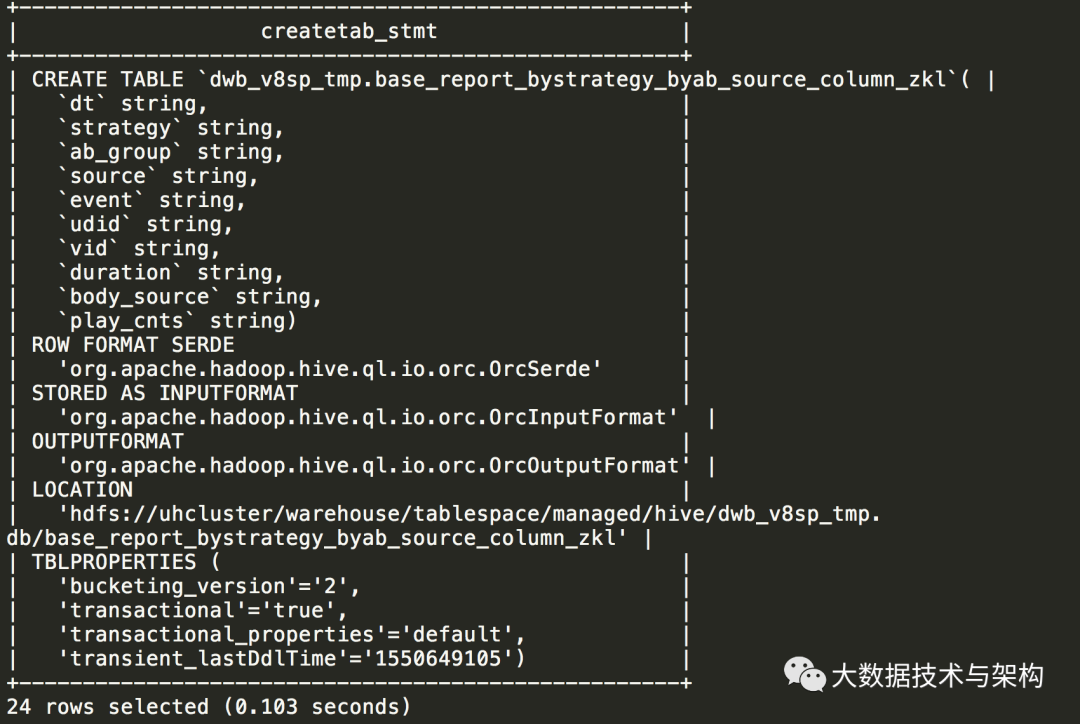
创建新表:按 dt,source,stragegy,ab_group 分区(注意先后顺序,一般习惯分区数越少的越靠前,根据1.5的查询可知:dt=1,source=2,strategy=14,ab_group=72)
create external table `dwb_v8sp_tmp.base_report_bystrategy_byab_source_column_lym`(
将原表数据插入新表:
insert into `dwb_v8sp_tmp.base_report_bystrategy_byab_source_column_lym` partition(dt,source,strategy,ab_group)
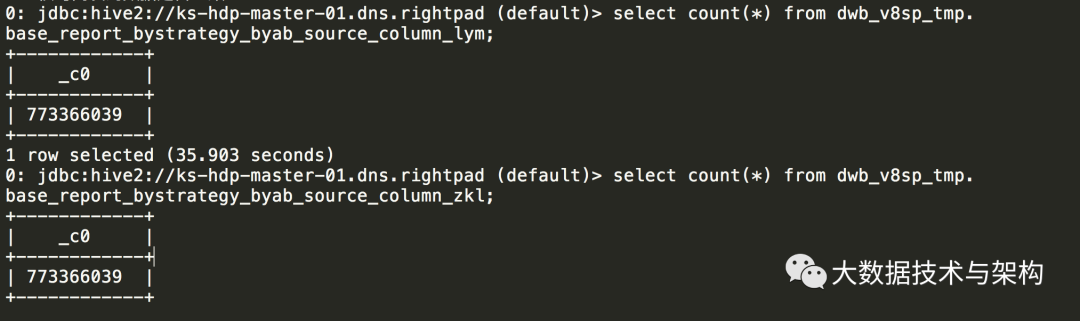
核对两表的数据是否一致:
1.6 基于新表执行查询(执行5分钟出结果):
HiveSQL经典优化案例二:
问题描述:一个复杂的SQL,查询执行一段时间后报错:基本上是查不出来;
分析函数对于大表来说不是 hive的强项,这个时候我们将其分解成很多子集,并且合理利用 hive 分区表的优势,然后去 join 。
2.1 将要执行的查询
create table bi_tmp.aloha_UserLoyalty_190301_190303 as
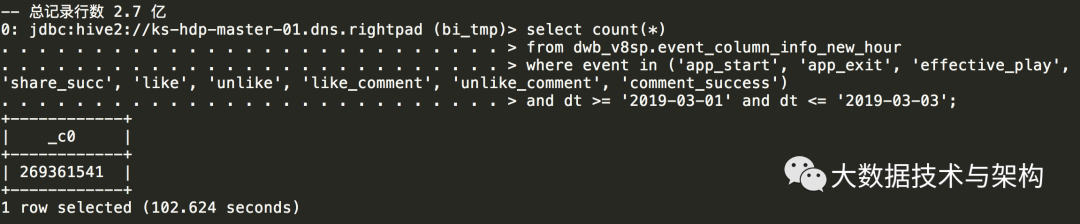
select count(distinct event) as dis_event
分解成三个子集,并保存到三张表: bi_tmp.zyt1, bi_tmp.zyt2, bi_tmp.zyt3
-- drop table if exists bi_tmp.zyt1;

HiveSQL经典优化案例三:
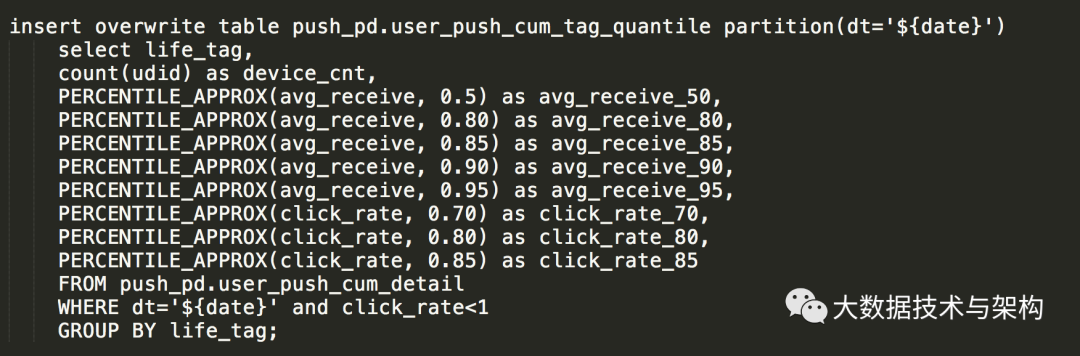
如下SQL,用到了 PERCENTILE_APPROX 函数,问题描述:如下SQL,用到了 PERCENTILE_APPROX 函数,个人初步分析认为:由于用到该函数的次数太多,导致性能严重下降。
我仔细查了一下该函数,发现:它是支持“数组传参”的,那么就不难找到优化该SQL的方法了。
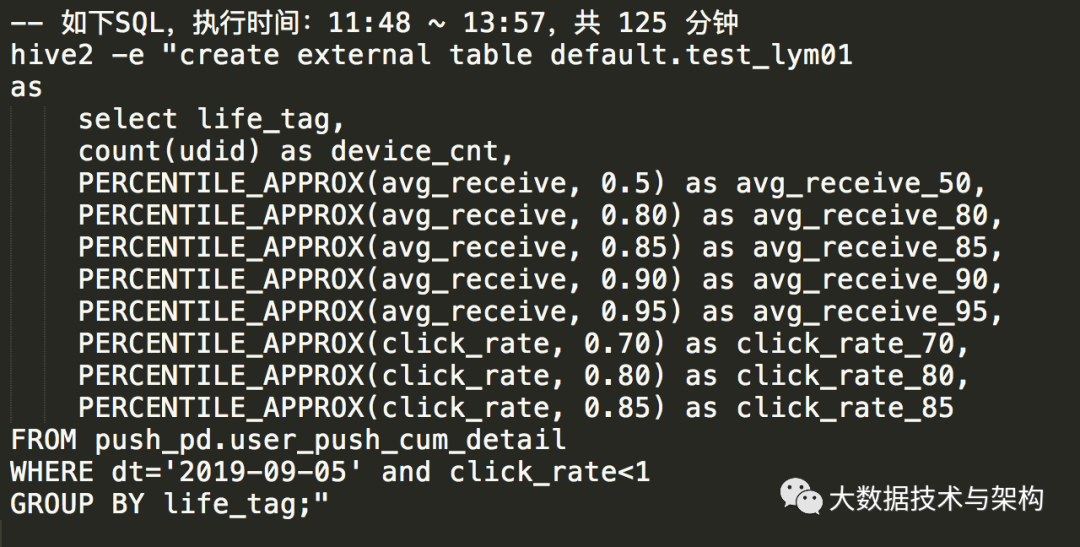
3.1 原SQL性能测试:
3.2 优化后的SQL,性能测试:
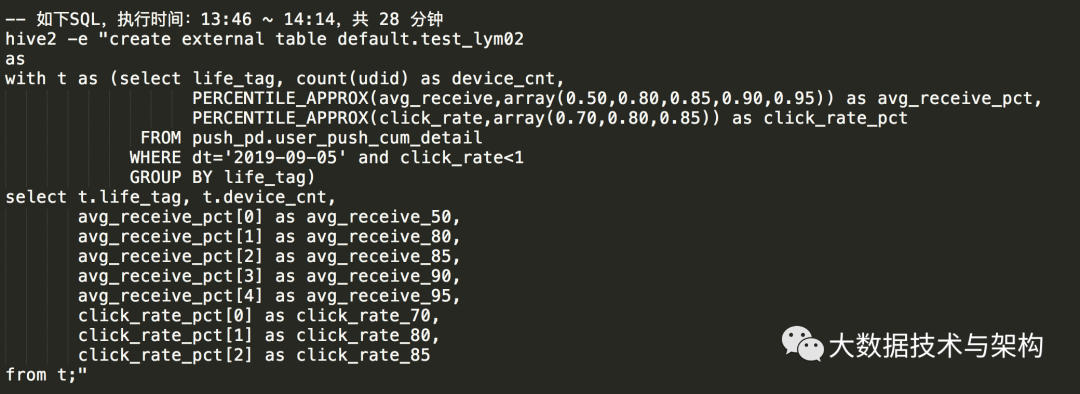
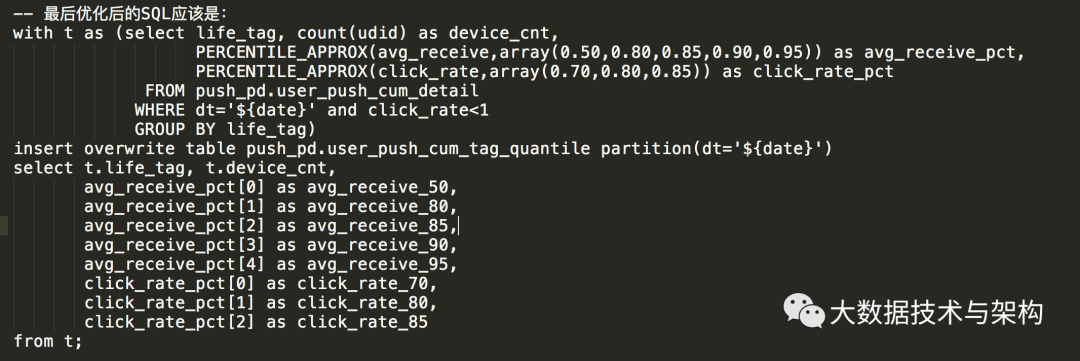
优化后的SQL,性能提升了4倍多。


版权声明:
本文为大数据技术与架构整理,原作者独家授权。未经原作者允许转载追究侵权责任。
编辑|冷眼丶
微信公众号|import_bigdata
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











