
前几天接触到SpringDataJPA访问数据库的项目,看源代码时发现有的Repository上面的部分接口没有实现类,但是系统却可以正常运行,这引起了我的好奇心,决定花点时间研究下,于是便有了此文。
先来看看是哪些接口可以不用实现:
Xxx findByXxxAndXxOrderByXxDesc(String arg1, String arg2, String arg3);
带着这样的疑问,开始今天的探索。
实战篇
1. 创建一个简单的表:
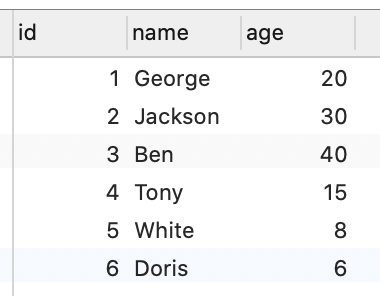
2. 创建一个Gradle的SpringBoot项目,并创建一个User实体类:
package com.example.demo.domain;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
private Integer age;
@Override
public String toString() {
return "User{" + "id=" + id + ", name='" + name + '\'' + ", age=" + age + '}';
}
// Getters and Setters ...
}
3. 创建UserRepo类作为User对象访问数据库的操作类,这里需要注意的是,UserRepo类继承了JpaRepository类:
package com.example.demo.dao;
import com.example.demo.domain.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public interface UserRepo extends JpaRepository<User, Long> {
// 通过三个列查找User
User findByIdAndNameAndAge(Long id, String name, Integer age);
}
4. 写个单元测试看下效果:
package com.example.demo;
import com.example.demo.dao.UserRepo;
import com.example.demo.domain.User;
import org.junit.Assert;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@SpringBootTest
class DemoApplicationTests {
@Autowired
private UserRepo userRepo;
@Test
void testFindByIdAndNameAndAge() {
User user = userRepo.findByIdAndNameAndAge(1L, "George", 20);
System.out.println("==========>>>>>>>>>>" + user.toString());
}
}
5. 执行结果:
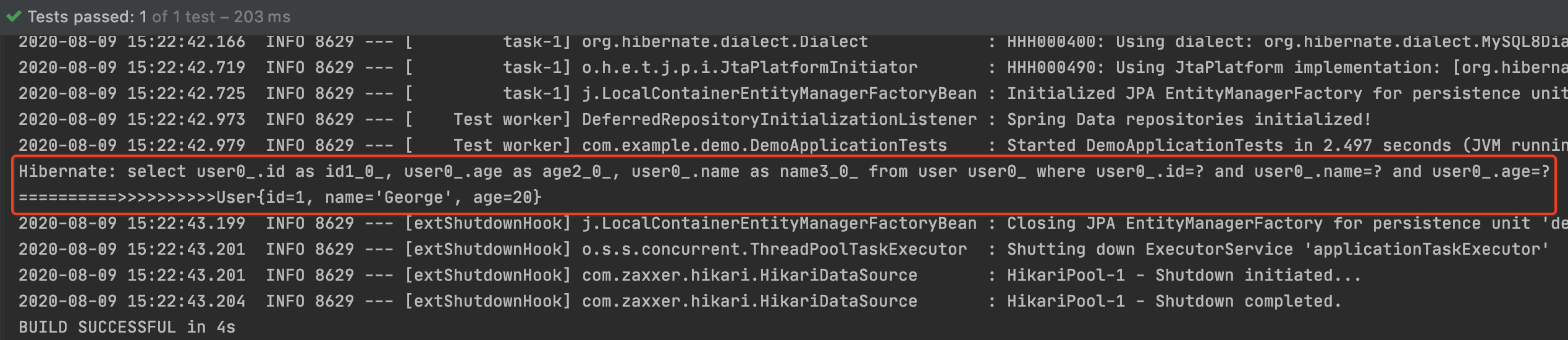
可以看到这个userRepo.findByIdAndNameAndAge方法只存在于接口,并没有任何实现(一句SQL都没写),但还是成功的返回了执行结果。
为什么呢?接下来我们来看源码。
源码篇
再次运行单元测试,这次用debug模式看看:
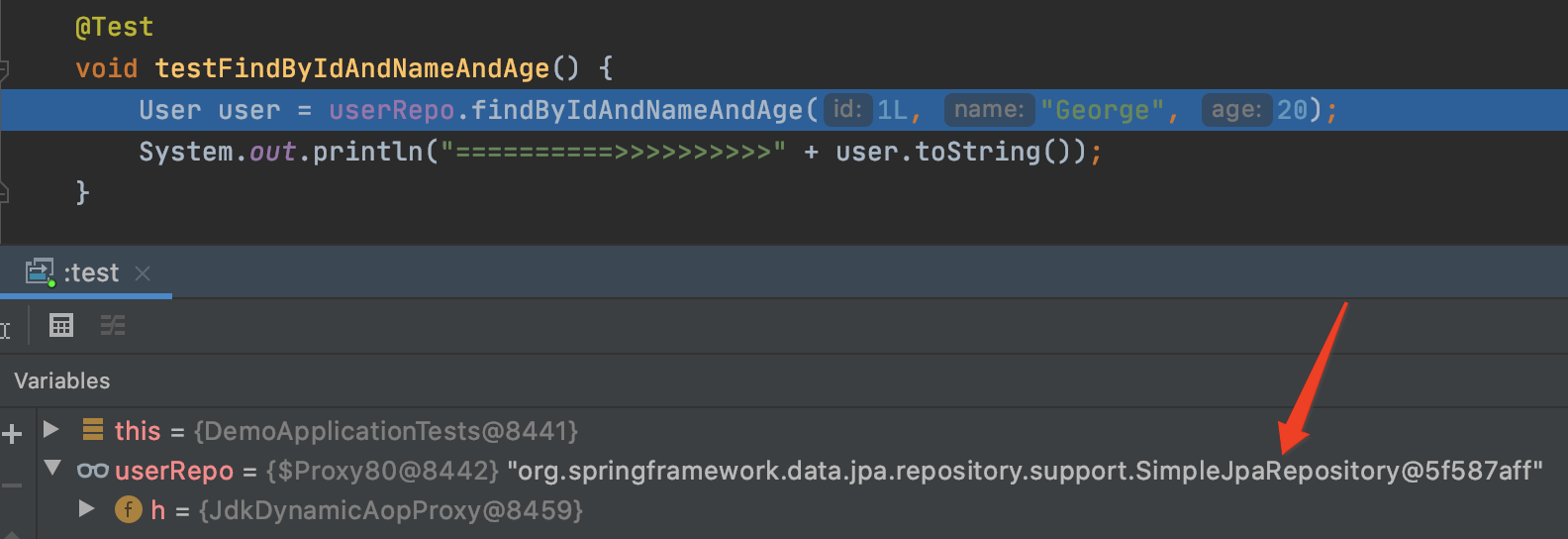
可以看到,Spring为我们注入的userRepo对象是个代理对象,实际上是个SimpleJpaRepository对象,而我们的UserRepo类是这么声明的:
public interface UserRepo extends JpaRepository<User, Long>
它继承于JpaRepository接口,我们可以从这个JpaRepository的实现类或子接口关系中找到这个实际注入的SimpleJpaRepository类:
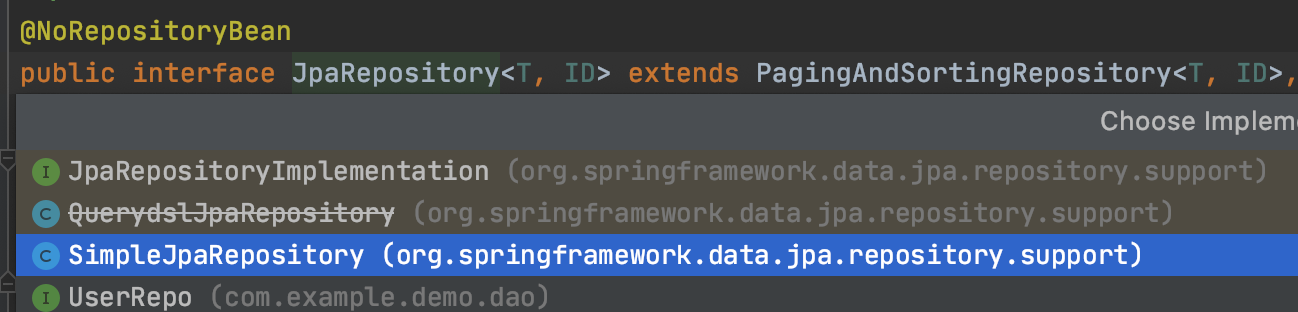
那么为什么会注入这个类呢?先来回答这个问题。
我们在Java Config方式配置Spring Data JPA的@EnableJpaRepositories注解里有这样一句:
//源码1
Class<?> repositoryFactoryBeanClass() default JpaRepositoryFactoryBean.class;
配置中默认指定了Repository的工厂类为JpaRepositoryFactoryBean,从类名可以看出这个类是一个工厂类,看下源码:
//源码2
public class JpaRepositoryFactoryBean<T extends Repository<S, ID>, S, ID>
extends TransactionalRepositoryFactoryBeanSupport<T, S, ID> {
private @Nullable EntityManager entityManager;
// 省略部分代码 ....
/*
* (non-Javadoc)
* @see org.springframework.beans.factory.InitializingBean#afterPropertiesSet()
*/
@Override
public void afterPropertiesSet() {
Assert.state(entityManager != null, "EntityManager must not be null!");
super.afterPropertiesSet();
}
// 省略部分代码 ...
}
可以看到,这是个这个类覆盖了afterPropertiesSet()方法,跟踪一下发现是在RepositoryFactoryBeanSupport类中的实现:
//源码3
public void afterPropertiesSet() {
// 看这里。这里初始化了一个repositoryFactory
this.factory = createRepositoryFactory();
// 省略部分代码 ...
// 看这里,从repositoryFactory中获取对象
this.repository = Lazy.of(() -> this.factory.getRepository(repositoryInterface, repositoryFragmentsToUse));
if (!lazyInit) {
this.repository.get();
}
}
这里面初始化了一个repositoryFactory,并从这个factory中获取repository,跟一下这个createRepositoryFactory()方法,最后会发现,在JpaRepositoryFactoryBean中有实现:
//源码4
protected RepositoryFactorySupport createRepositoryFactory(EntityManager entityManager) {
// 看这里。初始化了一个JpaRepositoryFactory
JpaRepositoryFactory jpaRepositoryFactory = new JpaRepositoryFactory(entityManager);
// 省略部分代码 ...
return jpaRepositoryFactory;
}
再跟一下this.factory.getRepository()方法,在RepositoryFactorySupport类中:
//源码5
public <T> T getRepository(Class<T> repositoryInterface, RepositoryFragments fragments) {
if (LOG.isDebugEnabled()) {
LOG.debug("Initializing repository instance for {}…", repositoryInterface.getName());
}
Assert.notNull(repositoryInterface, "Repository interface must not be null!");
Assert.notNull(fragments, "RepositoryFragments must not be null!");
RepositoryMetadata metadata = getRepositoryMetadata(repositoryInterface);
RepositoryComposition composition = getRepositoryComposition(metadata, fragments);
RepositoryInformation information = getRepositoryInformation(metadata, composition);
validate(information, composition);
// 看这里。通过information创建了target,并将其放入到代理对象的target中
Object target = getTargetRepository(information);
// Create proxy
ProxyFactory result = new ProxyFactory();
result.setTarget(target);
result.setInterfaces(repositoryInterface, Repository.class, TransactionalProxy.class);
if (MethodInvocationValidator.supports(repositoryInterface)) {
result.addAdvice(new MethodInvocationValidator());
}
result.addAdvisor(ExposeInvocationInterceptor.ADVISOR);
postProcessors.forEach(processor -> processor.postProcess(result, information));
if (DefaultMethodInvokingMethodInterceptor.hasDefaultMethods(repositoryInterface)) {
result.addAdvice(new DefaultMethodInvokingMethodInterceptor());
}
ProjectionFactory projectionFactory = getProjectionFactory(classLoader, beanFactory);
// QueryLookupStrategy稍后会介绍
Optional<QueryLookupStrategy> queryLookupStrategy = getQueryLookupStrategy(queryLookupStrategyKey,
evaluationContextProvider);
// QueryExecutorMethodInterceptor稍后会介绍
result.addAdvice(new QueryExecutorMethodInterceptor(information, projectionFactory, queryLookupStrategy,
namedQueries, queryPostProcessors));
composition = composition.append(RepositoryFragment.implemented(target));
result.addAdvice(new ImplementationMethodExecutionInterceptor(composition));
T repository = (T) result.getProxy(classLoader);
if (LOG.isDebugEnabled()) {
LOG.debug("Finished creation of repository instance for {}.", repositoryInterface.getName());
}
return repository;
}
注意: 在创建ProxyFactory实例后, 调用getProxy()返回的是Repository接口代理。这也是常说的: Spring Data JPA 的实现原理是动态代理机制
JpaRepositoryFactory.getTargetRepository():
//源码6
protected final JpaRepositoryImplementation<?, ?> getTargetRepository(RepositoryInformation information) {
// 看这里。
JpaRepositoryImplementation<?, ?> repository = getTargetRepository(information, entityManager);
repository.setRepositoryMethodMetadata(crudMethodMetadataPostProcessor.getCrudMethodMetadata());
repository.setEscapeCharacter(escapeCharacter);
return repository;
}
里面调用了getTargetRepository重载方法,跟进去:
//源码7
protected JpaRepositoryImplementation<?, ?> getTargetRepository(RepositoryInformation information,
EntityManager entityManager) {
JpaEntityInformation<?, Serializable> entityInformation = getEntityInformation(information.getDomainType());
// 看这里。这里得到了一个repository
Object repository = getTargetRepositoryViaReflection(information, entityInformation, entityManager);
Assert.isInstanceOf(JpaRepositoryImplementation.class, repository);
return (JpaRepositoryImplementation<?, ?>) repository;
}
//源码8
protected final <R> R getTargetRepositoryViaReflection(RepositoryInformation information,
Object... constructorArguments) {
// 看这里。根据information获取到repository的类名,然后通过反射生成实例并返回
Class<?> baseClass = information.getRepositoryBaseClass();
return getTargetRepositoryViaReflection(baseClass, constructorArguments);
}
可以看到,最终通过RepositoryInformation对象获取到repository的类名,并通过反射生成实例最终返回。那么这个RepositoryInformation是如何生成的呢?细心的同学可能已经看到了,在【源码5】中,通过getRepositoryInformation方法初始化的。进去看看具体过程:
//源码9
private RepositoryInformation getRepositoryInformation(RepositoryMetadata metadata,
RepositoryComposition composition) {
RepositoryInformationCacheKey cacheKey = new RepositoryInformationCacheKey(metadata, composition);
return repositoryInformationCache.computeIfAbsent(cacheKey, key -> {
//看这里。baseClass在这里初始化的
Class<?> baseClass = repositoryBaseClass.orElse(getRepositoryBaseClass(metadata));
return new DefaultRepositoryInformation(metadata, baseClass, composition);
});
}
debug的时候可以看到,这里的repositoryBaseClass是空的:
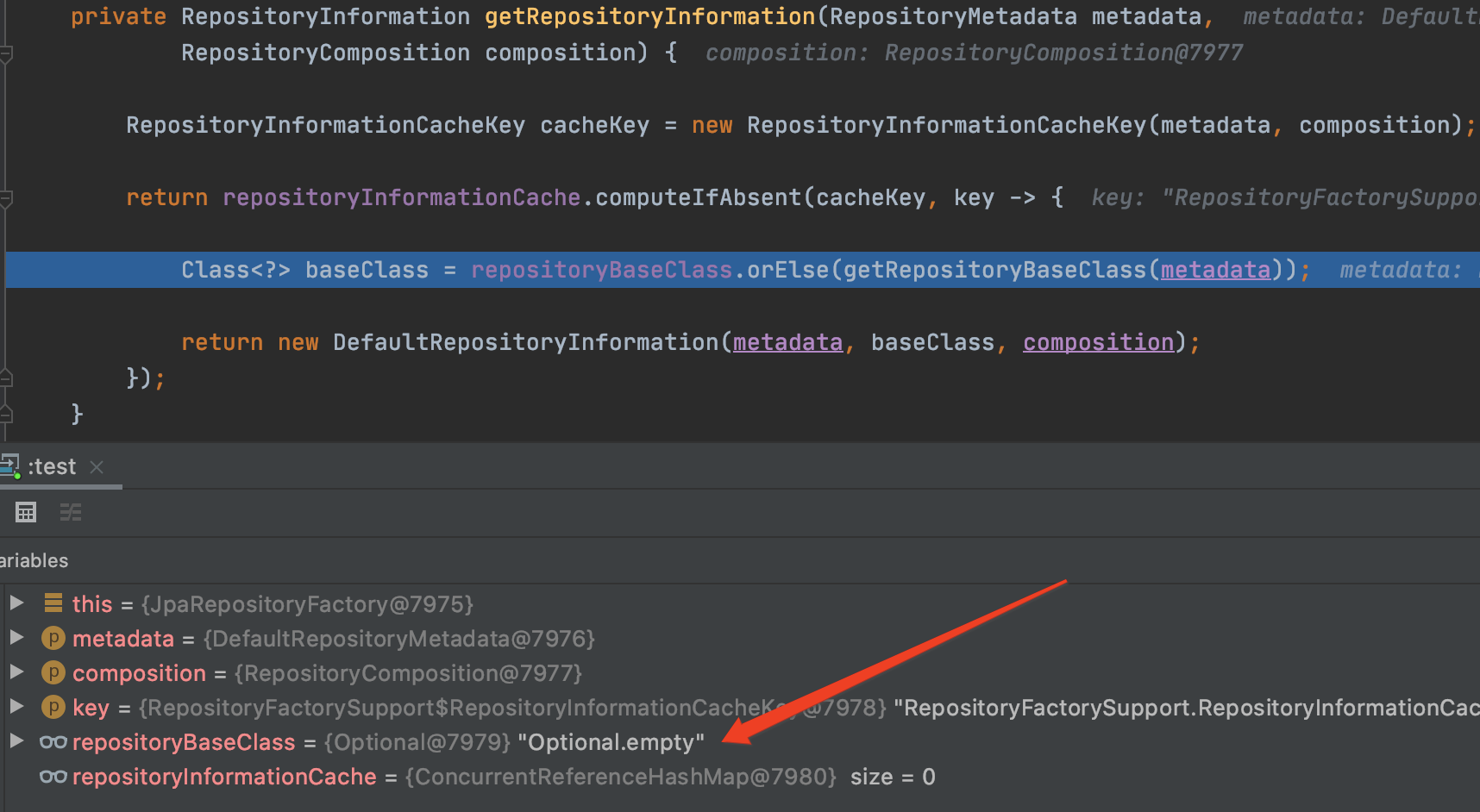
那么baseClass一定是从getRepositoryBaseClass()方法中被初始化的:
//源码10
protected Class<?> getRepositoryBaseClass(RepositoryMetadata metadata) {
return SimpleJpaRepository.class;
}
源码跟到这里,就知道为什么注入的是SimpleJpaRepository了。接下来分析方法名是怎么被转换成SQL的。
QueryLookupStrategy和QueryExecutorMethodInterceptor
在前面的【源码5】中,返回的代理中,加入了方法拦截器QueryExecutorMethodInterceptor,这个拦截器的作用就是拦截查询方法的。它使用一个QueryLookupStrategy来决定从哪里取查询。在【源码5】中创建了一个queryLookupStrategy:
//源码5
Optional<QueryLookupStrategy> queryLookupStrategy = getQueryLookupStrategy(queryLookupStrategyKey,
evaluationContextProvider);
result.addAdvice(new QueryExecutorMethodInterceptor(information, projectionFactory, queryLookupStrategy,
namedQueries, queryPostProcessors));
接下来看看QueryExecutorMethodInterceptor的构造器:
//源码11
/**
* Creates a new {@link QueryExecutorMethodInterceptor}. Builds a model of {@link QueryMethod}s to be invoked on
* execution of repository interface methods.
*/
public QueryExecutorMethodInterceptor(RepositoryInformation repositoryInformation,
ProjectionFactory projectionFactory, Optional<QueryLookupStrategy> queryLookupStrategy, NamedQueries namedQueries,
List<QueryCreationListener<?>> queryPostProcessors) {
this.namedQueries = namedQueries;
this.queryPostProcessors = queryPostProcessors;
this.resultHandler = new QueryExecutionResultHandler(RepositoryFactorySupport.CONVERSION_SERVICE);
if (!queryLookupStrategy.isPresent() && repositoryInformation.hasQueryMethods()) {
throw new IllegalStateException("You have defined query method in the repository but "
+ "you don't have any query lookup strategy defined. The "
+ "infrastructure apparently does not support query methods!");
}
this.queries = queryLookupStrategy //
.map(it -> mapMethodsToQuery(repositoryInformation, it, projectionFactory)) //
.orElse(Collections.emptyMap());
}
可以看到,QueryExecutorMethodInterceptor用一个Map<Method, RepositoryQuery> queries缓存了Repository里面定义的所有方法以便于在后续过程中通过方法名直接找出对应的查询。这些查询来自参数queryLookupStrategy,queryLookupStrategy则来自【源码5】。那么再看看这个getQueryLookupStrategy方法,它返回了一个QueryLookupStrategy的对象,它在RepositoryFactorySupport类中有一个默认的空实现,但真正的实现在JpaRepository中:
//源码12
@Override
protected Optional<QueryLookupStrategy> getQueryLookupStrategy(@Nullable Key key,
QueryMethodEvaluationContextProvider evaluationContextProvider) {
return Optional.of(JpaQueryLookupStrategy.create(entityManager, queryMethodFactory, key, evaluationContextProvider,
escapeCharacter));
}
继续跟这个JpaQueryLookupStrategy.create()方法:
//源码13
public static QueryLookupStrategy create(EntityManager em, JpaQueryMethodFactory queryMethodFactory,
@Nullable Key key, QueryMethodEvaluationContextProvider evaluationContextProvider, EscapeCharacter escape) {
Assert.notNull(em, "EntityManager must not be null!");
Assert.notNull(evaluationContextProvider, "EvaluationContextProvider must not be null!");
switch (key != null ? key : Key.CREATE_IF_NOT_FOUND) {
case CREATE:
return new CreateQueryLookupStrategy(em, queryMethodFactory, escape);
case USE_DECLARED_QUERY:
return new DeclaredQueryLookupStrategy(em, queryMethodFactory, evaluationContextProvider);
case CREATE_IF_NOT_FOUND:
return new CreateIfNotFoundQueryLookupStrategy(em, queryMethodFactory,
new CreateQueryLookupStrategy(em, queryMethodFactory, escape),
new DeclaredQueryLookupStrategy(em, queryMethodFactory, evaluationContextProvider));
default:
throw new IllegalArgumentException(String.format("Unsupported query lookup strategy %s!", key));
}
}
方法的查询策略有三种:
CREATE: 通过解析规范命名的方法名来创建查询, 此时即使有@Query或@NameQuery也会忽略。如果方法名不符合规则,启动的时候会报异常USE_DECLARED_QUERY: 也就是使用注解方式声明式创建, 启动时就会去尝试找声明的查询, 也就是使用@Query定义的语句来执行查询, 没有则找@NameQuery的, 再没有就异常.CREATE_IF_NOT_FOUND: 先找@Query或@NameQuery定义的语句来查询, 如果没有就通过解析方法名来创建查询.
本文主要分析方法名是如何创建查询的,所以这里我们只看1。直接进入CreateQueryLookupStrategy类,它是JpaQueryLookupStrategy的内部类:
//源码14
/**
* {@link QueryLookupStrategy} to create a query from the method name.
*
* @author Oliver Gierke
* @author Thomas Darimont
*/
private static class CreateQueryLookupStrategy extends AbstractQueryLookupStrategy {
private final EscapeCharacter escape;
public CreateQueryLookupStrategy(EntityManager em, JpaQueryMethodFactory queryMethodFactory,
EscapeCharacter escape) {
super(em, queryMethodFactory);
this.escape = escape;
}
@Override
protected RepositoryQuery resolveQuery(JpaQueryMethod method, EntityManager em, NamedQueries namedQueries) {
// 看这里。创建了一个PartTreeJpaQuery对象
return new PartTreeJpaQuery(method, em, escape);
}
}
从源码的注释里面可以看到,QueryLookupStrategy to create a query from the method name(它是一个通过方法名来创建query的查询策略)。并且resolveQuery方法覆盖了父类AbstractQueryLookupStrategy的方法。先来看看父类:
//源码15
private abstract static class AbstractQueryLookupStrategy implements QueryLookupStrategy {
// 省略部分代码 ...
@Override
public final RepositoryQuery resolveQuery(Method method, RepositoryMetadata metadata, ProjectionFactory factory,
NamedQueries namedQueries) {
return resolveQuery(queryMethodFactory.build(method, metadata, factory), em, namedQueries);
}
// 看这里。resolveQuery方法是abstract的,待子类实现
protected abstract RepositoryQuery resolveQuery(JpaQueryMethod method, EntityManager em, NamedQueries namedQueries);
}
果然,在父类有个resolveQuery方法,并且是abstract的,在子类CreateQueryLookupStrategy中被实现,并创建了一个PartTreeJpaQuery对象。继续跟进这个PartTreeJpaQuery类:
//源码16
PartTreeJpaQuery(JpaQueryMethod method, EntityManager em, EscapeCharacter escape) {
super(method, em);
this.em = em;
this.escape = escape;
Class<?> domainClass = method.getEntityInformation().getJavaType();
this.parameters = method.getParameters();
boolean recreationRequired = parameters.hasDynamicProjection() || parameters.potentiallySortsDynamically();
try {
// 看这里。关键的PartTree对象
this.tree = new PartTree(method.getName(), domainClass);
validate(tree, parameters, method.toString());
this.countQuery = new CountQueryPreparer(recreationRequired);
this.query = tree.isCountProjection() ? countQuery : new QueryPreparer(recreationRequired);
} catch (Exception o_O) {
throw new IllegalArgumentException(
String.format("Failed to create query for method %s! %s", method, o_O.getMessage()), o_O);
}
}
最核心的部分来了。这个PartTreeJpaQuery持有了一个PartTree对象,该对象会将一个方法名解析成一个PartTree。打开PartTree类看看:
//源码17
/**
* Class to parse a {@link String} into a tree or {@link OrPart}s consisting of simple {@link Part} instances in turn.
* Takes a domain class as well to validate that each of the {@link Part}s are referring to a property of the domain
* class. The {@link PartTree} can then be used to build queries based on its API
* instead of parsing the method name for each query execution.
*
* @author Oliver Gierke
* @author Thomas Darimont
* @author Christoph Strobl
* @author Mark Paluch
* @author Shaun Chyxion
*/
public class PartTree implements Streamable<OrPart> {
/*
* We look for a pattern of: keyword followed by
*
* an upper-case letter that has a lower-case variant \p{Lu}
* OR
* any other letter NOT in the BASIC_LATIN Uni-code Block \\P{InBASIC_LATIN} (like Chinese, Korean, Japanese, etc.).
*
* @see <a href="https://www.regular-expressions.info/unicode.html">https://www.regular-expressions.info/unicode.html</a>
* @see <a href="https://docs.oracle.com/javase/7/docs/api/java/util/regex/Pattern.html#ubc">Pattern</a>
*/
private static final String KEYWORD_TEMPLATE = "(%s)(?=(\\p{Lu}|\\P{InBASIC_LATIN}))";
// 看这里。查询方法以这些关键字开头都可以。比如:findById, getByNameAndAge
private static final String QUERY_PATTERN = "find|read|get|query|search|stream";
private static final String COUNT_PATTERN = "count";
private static final String EXISTS_PATTERN = "exists";
// 删除的关键字为delete或remove。比如:removeById, deleteByIdAndName等
private static final String DELETE_PATTERN = "delete|remove";
// 匹配方法名的正则表达式
private static final Pattern PREFIX_TEMPLATE = Pattern.compile( //
"^(" + QUERY_PATTERN + "|" + COUNT_PATTERN + "|" + EXISTS_PATTERN + "|" + DELETE_PATTERN + ")((\\p{Lu}.*?))??By");
/**
* The subject, for example "findDistinctUserByNameOrderByAge" would have the subject "DistinctUser".
*/
// 主语对象,就是要查找的东西。
private final Subject subject;
/**
* The predicate, for example "findDistinctUserByNameOrderByAge" would have the predicate "NameOrderByAge".
*/
// 谓语对象,就是通过什么查找。
private final Predicate predicate;
/**
* Creates a new {@link PartTree} by parsing the given {@link String}.
*
* @param source the {@link String} to parse
* @param domainClass the domain class to check individual parts against to ensure they refer to a property of the
* class
*/
public PartTree(String source, Class<?> domainClass) {
Assert.notNull(source, "Source must not be null");
Assert.notNull(domainClass, "Domain class must not be null");
Matcher matcher = PREFIX_TEMPLATE.matcher(source);
if (!matcher.find()) {
this.subject = new Subject(Optional.empty());
this.predicate = new Predicate(source, domainClass);
} else {
this.subject = new Subject(Optional.of(matcher.group(0)));
this.predicate = new Predicate(source.substring(matcher.group().length()), domainClass);
}
}
// 省略很多代码 ...
}
从注释可以看到,这个类会通过正则表达式Matcher来解析一个方法名(字符串)为一个一个的Part(最后形成一个PartTree),另一个Class类型的参数是用于校验解析到的每个Part都能跟这个类的某个属性对应上,最后这个PartTree对象会由API转换成一个Query。
这个PartTree包含了一个主语(要查询什么)和一个谓语(通过什么查询),我们还可以从源码中看到匹配的各种关键字等。
看到这里,就可以回答了一开始的问题了:为什么以下方法没有任何实现,但是却可以正确执行?
User user = userRepo.findByIdAndNameAndAge(1L, "George", 20);
答案就是,SpringDataJPA帮我们把每个方法名解析成了一个PartTree对象,然后转换成了一个Query,最后生成SQL来执行了。
需要注意的是,只有符合规范的方法名才能被正确的转换成查询,这里附上Spring官方文档,介绍了哪些支持的关键字:
The following table describes the keywords supported for JPA and what a method containing that keyword translates to:
Table 3. Supported keywords inside method names
Keyword
Sample
JPQL snippet
And
findByLastnameAndFirstname
… where x.lastname = ?1 and x.firstname = ?2
Or
findByLastnameOrFirstname
… where x.lastname = ?1 or x.firstname = ?2
Is, Equals
findByFirstname,findByFirstnameIs,findByFirstnameEquals
… where x.firstname = ?1
Between
findByStartDateBetween
… where x.startDate between ?1 and ?2
LessThan
findByAgeLessThan
… where x.age < ?1
LessThanEqual
findByAgeLessThanEqual
… where x.age <= ?1
GreaterThan
findByAgeGreaterThan
… where x.age > ?1
GreaterThanEqual
findByAgeGreaterThanEqual
… where x.age >= ?1
After
findByStartDateAfter
… where x.startDate > ?1
Before
findByStartDateBefore
… where x.startDate < ?1
IsNull, Null
findByAge(Is)Null
… where x.age is null
IsNotNull, NotNull
findByAge(Is)NotNull
… where x.age not null
Like
findByFirstnameLike
… where x.firstname like ?1
NotLike
findByFirstnameNotLike
… where x.firstname not like ?1
StartingWith
findByFirstnameStartingWith
… where x.firstname like ?1 (parameter bound with appended %)
EndingWith
findByFirstnameEndingWith
… where x.firstname like ?1 (parameter bound with prepended %)
Containing
findByFirstnameContaining
… where x.firstname like ?1 (parameter bound wrapped in %)
OrderBy
findByAgeOrderByLastnameDesc
… where x.age = ?1 order by x.lastname desc
Not
findByLastnameNot
… where x.lastname <> ?1
In
findByAgeIn(Collection<Age> ages)
… where x.age in ?1
NotIn
findByAgeNotIn(Collection<Age> ages)
… where x.age not in ?1
True
findByActiveTrue()
… where x.active = true
False
findByActiveFalse()
… where x.active = false
IgnoreCase
findByFirstnameIgnoreCase
… where UPPER(x.firstame) = UPPER(?1)
完。
(完整代码:https://github.com/wanxiaolong/JpaDemo)
参考资料:
https://docs.spring.io/spring-data/jpa/docs/2.3.2.RELEASE/reference/html/#reference












